* Grounding은 CV와 NLP에서 이미지 내의 객체와 관련된 텍스트 설명 또는 정보를 정확하게 연결하는 과정을 의미한다.
0. Abstract
이 논문에서는 "Grounding DINO"라는 open-set object detector를 소개한다.
* 오픈셋
시스템이 훈련 과정에서 보지 못한 새로운 범주의 데이터나 객체를 인식하고 처리할 수 있는 능력이다.
https://kimjy99.github.io/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0/dino/
[논문리뷰] Emerging Properties in Self-Supervised Vision Transformers (DINO)
DINO 논문 리뷰 (ICCV 2021)
kimjy99.github.io
(Dino 관련 글)
요약
DINO는 라벨이 필요 없는 Supervised Learning 방법이다. 학생 모델이 선생 모델로부터 학습하는 지식 증류 기술을 활용하며 DINO의 주요 개념과 절차는 다음과 같다.
1. 모멘텀 인코더 : DINO는 '교사' 네트워크와 '학생' 네트워크 2개를 사용한다. 교사 네트워크는 시간에 따라 천천히 업데이트 되는 모멘텀 인코더를 사용하여 안정적인 타게팅을 돕는다.
2. 멀티-크롭 훈련 : 다양한 크기와 크롭의 이미지를 사용하여 네트워크를 훈련시키는 것이다. 이는 모델이 다양한 시각적 변화에 robust하게 만들어준다.
3. Self-supervision 학습 목표 : DINO는 이미지의 다양한 뷰(크롭된 이미지들)로부터 추출된 특성을 일치시키는 것을 목표로 한다.
4. Cross entrophy Loss function 사용 : 학생은 교사의 출력을 모방하려고 시도하며, 이 과정중 CE 사용
5. 출력 중심화와 강화 : 배치 내 평균을 사용하여 출력을 조정하고, 강화는 Softmax 함수의 temp 파라미터를 조절하여 출력 분산을 조정한다.
이 Detector는 Transformer 기반의 DINO detector와 ground된 pre-training을 결합하여 카테고리 이름이나 지시 표현과 같은 인간의 입력을 사용해 객체 탐지가 가능해진다.
오픈셋 객체 탐지의 핵심 솔루션은 기존의 Closed dectector에 Language 개념을 도입하여 일반화를 가능하게 하는 것이다.
언어와 시각 modality를 결합하기 위해(multi-modal), 우리는 closed detector를 3 가지 타입으로 나누고
'기능 향상 장치', '언어 안내 쿼리 선택', 'Cross modality decoder'의 융합 솔루션을 제안한다.
이전 연구들은 주로 새로운 카테고리에 대한 open-set object detect를 하는 반면, 해당 연구는 속성으로 지정된 object에 대한 supervise 표현 이해 평가도 같이 수행할 것을 제안한다.
Grounding DINO는 COCO, LVIS, ODinW 등 벤치마크를 포함한 모든 세팅에서 성능이 좋았다.
1. Introduction
컴퓨터가 시각 지능을 가진다는 것은 새로운 개념을 이해한다는 것이다. 본 연구에서는 인간 언어 입력으로 지정된 임의의 객체를 감지할 수 있는 강력한 시스템을 개발하는 것을 목표로 한다. 그리고 이 과정을 "Open set object detection"이라고 한다.
Open set object detection은 사람의 시각 지능처럼 Unseen data를 처리할 수 있기 떄문에 일반적인 객체 감지기로써 큰 잠재력을 가지고 있다. (Ex: 글씨로 고양이를 설명하면 해당 고양이 사진을 생성해준다.)
오픈셋 감지의 핵심은 보이지 않는 객체 일반화를 위해 언어를 도입하는 것이다. GLIP과 같은 기존 대조적 학습을 통해 Unseen data를 handling하는 방법은 기존의 one-stage detector Dynamic-Head를 기반으로 설계했기 때문에 한계점이 있다. 본 논문에서는 open-set과 closed-set detect는 밀접하게 관련되어있기 때문에, 더 강력한 closed-set detector가 더 나은 open-set detector를 만들 수 있다고 한다.
GLIP(Grounded Language-Image Pre-training)
=> 컴퓨터 비전, 자연어 처리예 사용되는 모델이며, 이미지 내의 객체와 관련된 언어적 설명을 연결하는 기능을 제공한다. 이미지와 관련된 텍스트 정보를 이용하여 이미지 내 객체를 정확히 식별하고 특정하는 것이 목적이다.
이를 위해 *대조적 학습을 사용하여, 이미지 내의 특정 객체 영역과 해당 객체를 기술하는 언어적 문구 간의 관계를 학습한다.
대조적 학습(Contrastive Learning)
=> 모델이 유사한(Similarity가 높은) Pair를 높게, 그 외 다른 Pair들을 낮게 평가하도록 학습하는 방식이다.
(CLIP 참고), 즉 Positive Pair, Negative Pair를 두고, 이 샘플들을 임베딩 공간에 매핑하여 Positive Pair의 평가는 올리고 Negative Pair의 평가는 내려가는 방법이다.
One-stage detector Dynamic-Head
=> 이미지 내 객체의 위치 감지와 분류를 한 번에 수행한다. 대표적으로는 YOLO, SSD가 있다.
이 방식은 처리속도가 매우 빠르지만, 정확성에서 two-stage detector에 비해 떨어질 수 있다.
Dynamic Head는 one-stage detector의 한 형태로, 객체 감지를 위한 다양한 기능을 동적으로 조정하여 사용하는 방식이다. Dynamic Head가 최적화되지 않은 특정 dataset이나 객체 유형에 대해서는 최적의 결과를 보장하지는 않는다.
따라서 Transformer based detector를 응용하여 객체 탐지 성능 뿐만 아니라 다중 수준의 텍스트 정보를 grounded pre-training을 통해 알고리즘에 통합하고자한다.
Grounding DINO는 GLIP에 비해 여러가지 강점이 있다.
1. Transformer based 아키텍쳐는 언어 모델과 유사하여 이미지와 언어 데이터를 모두 처리하기가 더 쉽다.
(전체 파이프라인에서 Cross-modality 특성을 더 쉽게 융합 가능.)
2. Transformer based detector는 대규모 데이터셋을 활용이 가능하다.
3. DINO는 어려운 제작 모듈을 사용하지 않고도 끝까지 최적화될 수 있어, 전체적인 Grounding 모델 설계를 크게 단순화한다.
대부분의 Open-set detector는 언어 정보를 포함하여 closed-set detector를 open-set 시나리오로 확장해왔다.
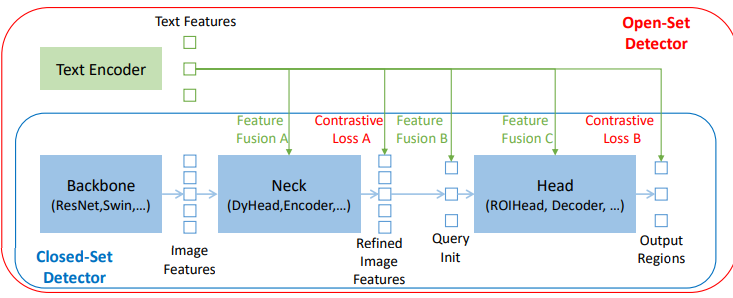
위의 사진처럼, Closed-set detector는 일반적으로 3개의 중요한 모듈을 지닌다.
(특성 추출을 위한 BackBone -> 특징 강화를 위한 Neck -> 박스 예측을 위한 Head)
Closed-set detector는 언어 인식 영역 임베딩을 학습함으로써 새로운 객체를 감지하게 할 수 있다.(일반화)
또한 각 영역을 언어 인식 의미 공간에서 새로운 카테고리로 분류가 가능하다.
이를 위해 가장 중요한 것은 넥/헤드 출력에서 영역 출력과 언어 특징 사이의 Contrastive Loss를 사용하는 것이다.
모델이 Cross-modality information을 정렬하도록 돕기 위해, 일부 연구는 최종 Loss 단계 이전에 Featrue Fusion을 하기도 한다. 사진은 Feature Fusion이 세 단계에서 수행될 수 있음을 시사한다.
이론상 많은 Feature Fusion을 하면 할수록 성능은 올라간다.
검색 작업에서는 효율성을 위해 최종적으로만 Multi-modal feature 비교를 수행하는 CLIP과 같은 two-tower 아키텍처를 선호한다. 그러나 Open-set detect의 경우 초기 단계부터 텍스트와 이미지 정보를 밀접하게 통합하는 것이 유리할 수 있다.
개념적으로는 간단하지만, 3단계 모두에서 Feature Fusion을 수행하기는 어려운 일이다.
이러한 Classic detector와 달리 Transformer 기반 감지기인 DINO는 언어 블록과 일관된 구조를 가지고 있으며, layer-by-layer 디자인을 통해 언어 정보와 쉽게 상호 작용할 수 있다.
따라서 이 원칙에 따라 넥 - 쿼리 초기화 - 헤드 단계에서 3 개의 Feature-Fusion approach를 설계한다.
(text-to-image cross-attention, image-to-text cross-attention, self-attention) 들을 쌓아 넥 모듈로 Feature 강화기를 설계하고, 헤드를 위한 쿼리 init에서 language guided query selection method를 개발한다.
마지막으로 image - text cross attention layer를 갖춘 헤드 단계를 위한 Cross-modality decoder를 설계하여 쿼리 표현을 강화한다.
CLIP에서는 이미지 인코더, 텍스트 인코더에서 Tokenizing된 각각의 token을 한번 임베딩 공간에 매핑, Cosine Similarity를 계산하여 한번만 비교하게 된다.

1-(b)의 왼쪽 열에서와 같이 기존의 open-set detect 연구는 새로운 카테고리의 객체에 대해 모델을 평가했다. 본 연구에서는 속성으로 설명된 객체가 포함된 또 다른 중요한 시나리오도 고려해야한다고 한다.(Referring Expression Comprehension)
즉, Closed-set detection(이미 학습된 데이터 내의 객체 인식), Open-set detection(학습 데이터에 없는 새로운 객체를 인식할 수 있는 능력), Referring object detection(특정 텍스트 설명을 이용해 객체 탐지)의 3가지 평가 기준을 사용한다.
요약하자면, Grounding DINO는 DINO의 확장이며, Feature 강화기, Language guide query selection 모듈, Cross-modality decoder를 포함한다.
2. Related Work
1. Grounding DINO는 DINO를 기반으로 구축되었으며, DINO는 대조적 제거 기술을 포함하여 성능을 발전시킨 end-to-end transformer 기반 detector이다. 그러나 기존의 방법은 closed-set detect에 초점을 맞추고 있으며 사전에 정의된 카테고리가 제한적이기 때문에 새로운 클래스로의 일반화가 어렵다.
2. Open-set object detection은 기존의 bounding box annotation을 이용하여 훈련되며, language generalization을 통해 Unseen class를 감지하는 것을 목표로 한다. 그러나 기존 연구들은 multi modal information을 부분적인 단계에서만 융합하여, 언어 일반화 능력이 최적화되지 않을 수가 있었다.
3. Grounding DINO
Grounding DINO는 주어진 (이미지, 텍스트) 쌍에 대해 여러 개의 객체 상자와 명사 구를 출력한다.

위의 그림에서 보이듯이 모델은 입력 이미지에서 고양이와 테이블이라는 단어를 찾아내고, 입력 텍스트에서 해당하는 라벨로 고양이와 테이블이라는 단어를 추출한다.
GLIP의 방법과 유사하게, 객체 감지 작업을 위해 모든 카테고리 이름을 입력 텍스트로 연결한다.
Groudning DINO는 이중 인코더 - 단일 디코더 구조이다.
위의 사진을 보면, 이 모델은 이미지 특징 추출을 위한 이미지 백본, 텍스트 특징 추출을 위한 텍스트 백본 -> 이미지와 텍스트 특징 융합 이전 최적화를 위한 Feature Enhancer, 쿼리 초기화를 위한 Language-guide Query Selection 모듈 -> Box refinement를 위한 Cross-Modality Decoder를 가지고 있으며, 기존 방법과 다르게 각 단계에서 전부 Text Feature들과 Fusion되고 있음을 알 수 있다.
각 (Image, Text) 쌍에 대해 먼저 Image Backbone, Text Backbone을 사용하여 바닐라 이미지 특징과, 텍스트 특징을 추출한다. 두 바닐라 특징은 Cross-modality feature fusion을 위해 Feature Enhancer로 전달된다.
Cross modality text 및 image feature를 얻은 후, 이들은 Language-guide Query Selection module로 전달되어 Cross modality 쿼리이 된다.
이 후, Cross-Modality Queries를 쿼리로, Image,Text feature들을 Key&Value로 활용하여 2개의 modal feature에서 원하는 feature를 탐색하고 업데이트하기 위해 Cross-Modality Decorder로 전달된다. 마지막 Cross-modality query는 객체 상자를 예측하고 해당 phrase를 추출하는데 사용된다.
* Vanilla Features
=> 기본적이거나 추가적인 처리나 특화된 기술이 적용되지 않은 가장 단순한 형태의 Feature.
(Raw feature들보다는 기본적인 가공은 되어있음.)
1. Feature Extraction and Enhancer

(I,T) 쌍이 주어지면, 이미지 백본으로 Swin transformer 등을 사용하여 multiscale image feature들을 추출하고, BERT와 같은 텍스트 백본으로 text feature들을 추출한다.(다양한 블록의 출력에서 다중 스케일 특징이 추출된다.)
바닐라 이미지와 텍스트 특징을 추출한 후, 이들은 Cross-modality feature fusion을 위한 Feature Enhancer에 입력된다.
Feature Enhancer는 여러 특징 강화 레이어를 포함한다.
위의 사진을 보면 각 Feature들은 Self-Attention, Deformable Self-Attention을 거쳐 Text Feature는 Key, Value로 Image Feature는 Query로 Image-to-text Cross Attention이 된다. 그 후 반대로 Text-to-image Cross-Attention을 수행하여 결과물인 FFN을 출력한다.
* Cross-Attention : 다른 두 modality나 데이터 소스 간의 상호 작용을 모델링하는 어텐션 매커니즘.
하나의 modality info.를 사용하여 다른 modality에서 특정 특징을 강조하거나 추출하는데 사용한다.
(Query : 한 데이터 소스로부터 추출된 표현, Key,Value : 다른 데이터 소스로부터 추출된 표현)
2. Language-Guided Query Selection
Grounding DINO는 입력 텍스트에 지정된 이미지에서 객체 감지를 목표로 한다.
(Ex : 이 사진에서 고양이 찾아줘.)
따라서 텍스트 데이터를 활용하여 객체 감지를 효과적으로 유도하기 위해, 입력 텍스트와 "더" 관련 있는 Feature를 Decoder query로 선택하는 언어 가이드 쿼리 선택 모듈을 설계한다.

image_feature, text_feature를 내적하여 i,t 차원 출력을 배치별로 계산한다.
이후 각 배치의 이미지 특징에 대한 텍스트 특징 중 최대값을 찾아 저장한다.
마지막으로 이전 단계에서 저장된 logits_per_img_feat에 대해 지정된 쿼리 수 만큼 가장 높은 값을 가진 텍스트 특징 인덱스를 저장한다. 결과로 topk_proposals_idx: (bs, num_query)의 결과를 가지게 된다.
결론적으로, Language-Guided Query Selection module은 num query indices를 출력한다.
우리는 해당 정보들을 가지고 Feature를 추출하여 query를 초기화할 수 있다.
기존 DINO를 따라 디코더 쿼리 초기화 위해 혼합 쿼리 선택을 사용한다. 각 디코더 쿼리는 내용 부분, 위치 부분으로 구성되며 독립적이다. 위치 부분은 동적 앵커 박스로 정의되며, 인코더 출력으로 초기화된다. 내용 쿼리는 훈련 중에 학습 가능하도록 설정한다.
(Text Feature를 기반으로 가장 관련 있는 Image feature를 선택, DINO decoder의 위치 쿼리로 사용.)
3. Cross-Modality Decoder

이전 단계에서 선택된 Cross-Modality Query를 Query로 사용하고, Enhance된 Text, Image Feature를 Key,Value로 사용해 디코딩을한다. 먼저 Cross-Modality Query에서 Self-Attention을 수행하고, Image -> Text 순으로 Cross-Attention을 수행한다. 최종적으로 FFN(FeedForwardNetwork)에서 출력처리하여 Updated Cross-Modality Query를 생성한다.
4. Sub-Sentence Level Text Feature

이전 연구에서는 두 종류의 텍스트 프롬프트가 연구되었는데, 본 연구에서는 이를 문장 수준 표현과 단어 수준 표현으로 명명했다.
문장 수준 표현은 하나의 문장을 하나의 특징으로 인코딩한다. 구문 그라운딩 데이터에서 일부 문장에 여러 구가 있는 경우, 중요한 구를 추출하고 다른 단어들은 제거한다. 이 방법을 통해 단어 간의 영향을 제거하면서 문장 내의 세밀한 정보를 잃는다.
단어 수준 표현은 한 번의 순방향으로 여러 카테고리 이름을 인코딩할 수 있게 하나 불필요한 의존성이 도입되며 관련 없는 단어들이 상호 작용하게 된다. (사진에서도 떨어진 단어들이 상호 작용한다.)
하위 문장 수준 표현은 단어 수준 표현의 단점을 극복하기 위해 관련 없는 카테고리 간의 attention을 차단하는 attention mask를 도입한다. 이를 통해 카테고리 이름 간의 영향을 제거하면서 동시에 각 단어의 특징을 유지하여 더 세밀한 이해를 가능하게 한다.
5. Loss function
기존의 DETR 연구들과 비슷하게 bounding box regression에 대해 L1 Loss, GIOU Loss를 사용한다. 추가로 GLIP을 따라 예측된 객체와 언어 토큰 간의 대조적 손질을 분류에 사용한다. 구체적으로, 각 쿼리를 텍스트 특징과 내적하여 각 텍스트 토큰에 대한 로짓을 예측하고 focal loss를 계산한다. Box regression과 classification cost는 예측과 실제 값 간의 이분 매칭에 사용된다. 그 다음에는 실제 값과 매칭된 예측 사이에 동일한 Loss 구성요소로 최종 Loss를 계산한다. 이 후 각 디코더 계층 후와 인코더 출력 후에 보조 Loss를 추가한다.
- Bounding Box Regression
1. L1 loss는 예측된 bouding box의 위치와 크기가 실제 bounding box와 얼마나 차이가 있는지를 절대값을 통해 측정한다.
2. GIOU은 겹치지 않는 상자들 사이의 관계도 고려하여 더 정확한 regression을 도모하는 것이다.
- 예측된 object와 text 지시문 사이의 대조적 손실
입력 쿼리를 text feature와 내적하여 각 text token에 대한 logit을 예측하고 각 로짓에 대해 focal loss를 계산하여 계산한다.
- IoU loss
두 boudning box의 겹치는 영역을 기반으로 계산되는 loss function. 두 상자가 완벽히 겹칠 때 1, 전혀 겹치지 않을 때 0이 된다. 그러나 두 상자가 아예 겹치지 않을 때는 Gradient가 0이 되어 학습이 되지 않는 문제가 있어 개발된 것이 GIoU loss 이다.

4. Experiments
평가는 COCO detection benchmark에서 closed-set setting, zero-shot COCO, LVIS, ODinW에서 open-set setting, RefCOCO/+/g에서의 referring detection setting에 대해 3가지 평가로 이루어진다. 그 다음 모델 디자인의 효과를 보여주기 위해 소거법 실험을 수행하고, 몇 개의 플로그인 모듈을 훈련함으로써 이미 잘 훈련된 DINO를 open-set 시나리오를 전환하는 방법을 탐구한다.
이미지 처리에는 Swin Transformer-T,L. 텍스트 처리에는 BERT를 사용하였다고 한다.
- Zero-shot Transfer of Grounding DINO

COCO benchmark에서 Grouding DINO, GLIP, DINO를 비교했다. 대규모 데이터셋에서 모델을 사전 훈련시키고 COCO 벤치마크에서 직접 평가하였다고 한다. O365 dataset이 거의 모든 카테고리를 이미 포함하고 있기 때문에 O365에서 pre-training된 DINO를 COCO에서 zero-shot baseline으로 평가했다고 한다.
결과는 DINO가 DyHead보다 COCO zero-shot transfer에서 더 좋은 성능을 보여준다. 또한 같은 설정 하에서 Grounding DINO는 DINO와 GLIP에 비해 더 좋은 성능을 보여준다. (각각 +0.5AP, 1.8AP)
Grounding data는 당연히 Grounding DINO에 도움이 되며, 더 강력한 백본과 더 큰 데이터를 사용하여 Grounding DINO는 훈련 중에 COCO 이미지를 보지 않고도 COCO 객체 감지 벤치마크에서 52.5 AP의 기록을 세웠다고 한다.
(괄호 안 63.0/63.0은 COCO 데이터 셋에서 Fine tuning을 했을 때의 점수이다.)
- LVIS Benchmark

LVIS는 long-tail object를 위한 dataset이다. (Long-tail이란 일반적으로 데이터셋에서 드물게 나타나는 객체나 카테고리를 지칭한다.)
이 dataset은 평가를 위해 1000개 이상의 카테고리를 포함하며, LVIS를 downstream task로 활용하여 모델의 zero-shot 능력을 테스트한다. 모델의 basline으로는 GLIP을 사용한다. 결과는 전반적으로 좋게 나타났으나 특이점이 몇가지 있다.
1. Grounding DINO는 일반적인 object에서 GLIP보다 잘 작동하지만 드문 카테고리에서는 더 나쁘다.
(900개의 query num이 능력 제한한다고 의심된다.)
반면 onestage detector는 feature map의 모든 쿼리를 한번에 비교에 사용한다.
2. Grounding DINO가 GLIP보다 더 많은 데이터로 더 큰 이득을 얻는다는 것이다.
(GLIP보다 Grounding DINO가 확장성이 좋음.)
- ODinW benchmark

이외에서도 ODinW benchmark 성능도 좋았다. 따라서 Grounding DINO의 일반화 및 확장성 능력을 확인할 수 있었다.
해당 표는 Zero-shot, Few-shot, Full-shot의 결과이다. O365와 GoldG만을 pre-training에 사용함에도 불구하고, Few,Fullshot 설정해서 Grounding-DINO-T는 DINO를 능가한다는 점도 관찰이 가능하다. (Swin-T를 사용한 Drounding Dino가 풀샷에서 Swin-L 사용한 DINO보다 좋다.)
- RefCOCO/+/g

동일한 설정에서 Grounding DINO는 GLIP을 능가하였다. (그러나 GLIP, Grounding DINO는 REC 데이터가 없다면 성능이 좋지 않았다.) Caption 데이터나 더 큰 모델과 같은 더 많은 훈련 데이터가 최종 성능을 돕기는 하지만, 효과는 미미하다.
따라서 RefCOCO/+/g 데이터를 training에 주입하면, Grounding DINO는 상당한 이득을 얻는다.
결론적으로 대부분의 현대 open-set object detector가 더 세밀한 감지를 위해 더 많은 주의를 기울어야한다는 것이다.
- Ablations

이 섹션에서는 소거법에 대해 다루고 있다.
open-set object detection을 위한 fusion grounding model과 하위 문장 레벨 텍스트 프롬프트를 제안하고 있으며, 모델 디자인의 효과를 검증하기 위해 다양한 변형에 대해 일부 fusion block을 제거한다. 위의 사진은 그 결과이고 모든 모델은 Swin-T backbone으로 O365에서 사전 훈련되었다고 한다. 인코더 퓨전이 가장 중요함을 알 수 있다.
- Transfer from DINO to Grounding DINO
Grounding DINO 모델을 처음부터 훈련하는 것은 계산비용이 많이 든다. 하지만 pre-train된 DINO 가중치를 활용하면 비용을 상당히 줄일 수 있다. 따라서 pre-train된 DINO를 Grounding DINO로 전환하는 연구를 하였다고한다.
그 방법은 DINO와 Grounding DINO에 공존하는 모듈은 고정시키고, 다른 매개변수들만 미세 조정하는 것이라고 한다.
5. Conclusion
이 논문에서는 Grounding DNO 모델을 제시하였으며, 이는 DINO를 open-set object detector로 확장하여 주어진 텍스트 쿼리를 통해 임의의 객체를 감지할 수있게 한 것이다.
open-set object detector 디자인에서 Cross-modality 정보를 더 잘 융합하기 위해 3단계에 걸처 긴밀한 Fusion approach를 제안했으며, 더 합리적인 방식으로 텍스트 프롬프트에 감지 데이터를 사용하기 위해 sub-sentence level의 표현을 제안한다.
추가적으로 open-set object detect를 REC 작업으로 확장하고 그에 따라 평가를 수행한다.
그러나 기존의 open-set detector는 REC 데이터에 대해 fine tuning 없이는 잘 작동하지 않는다.
사용 시, Grounding DINO는 GLIPv2와 같은 분할 작업에는 사용할 수 없으며, 훈련 데이터의 양이 적어 최종 성능에 제한을 줄 수 있다.