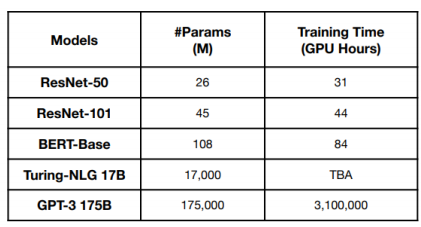
* Distributed learning- 왜 분산 학습을 하여야할까?ex) On-device learning만약 모델이 개인 데이터를 학습하여 맞춤형 서비스를 제공해야한다고 생각해보자. 이 경우 Privacy 문제 때문에 Server로 데이터를 보내는 것은 문제가 될 수 있다. 1. 데이터의 분산성 : 데이터는 센서, 기기, DB 등 다양한 곳에 분산되어 존재하지만, 보안 등의 이유 때문에 고립되어있을 수 있다.2. AI 시스템의 적응 필요성 : AI 시스템은 센서에서 수집된 새로운 데이터에 지속적으로 적응해야할 필요가 있다. 즉, 개인적인 데이터를 다룰 일이 필수적으로 생긴다.=> 분산된 여러 client에서 데이터를 활용해 모델을 자체적으로 학습할 수 없을까?1. Federated Learning ..