1. Simulation의 조건

우선 첫번째로 떠오르는 점은 Number of MH를 극단으로 보내는 것이다.
해당 논문에서는 IRSML이 무거운 SDWN 네트워크 환경에서 강점이 있다고 하였다.
그러나 과연 30~60 node들을 5 nodes 간격으로 측정한 것이 무거운 SDWN에서의 시뮬레이션일지가 궁금하다.
일반적으로 SDWN은 동적인 환경에서 네트워크 자원을 효과적으로 관리하고 유연성을 제공하기 위해 설계되었으므로, 수백 또는 수천 대의 MH가 있는 대규모 네트워크까지 고려해볼 수 있다.
두번째는 Speed of MH이다. 만약 이 알고리즘이 통상적인 도시의 SDWN을 가정한다면, 0-20 m/s는 너무 한정적인 속도 같다.
도시의 구성에 따라 다르겠지만, 0 ~ 28 m/s 까지는 가정해주고 시뮬레이션을 해보고 싶다.
세번째는 250m라는 transmission range가 부족해보인다. 250m ~ 수 킬로미터까지의 분포를 확인해봐야할 것 같다.
2. Supervised Learning
연구실 석사생 분들과 교수님에게 논문 리딩 결과를 발표하며 들은 얘기이다.
과연 Traffic load, QueueLength로만 PBP와 EED를 올바르게 예측해낼 수 있을까?
우선 주어진 파라미터에 기반해 raw data를 표현하는 식은 MATLAB surface fitting tool을 사용하여 생성 가능하다.
(https://kr.mathworks.com/help/curvefit/command-line-curve-and-surface-fitting.html)
(해당 사진은 curve fitting tool의 사용 예시이다.)
피팅의 결과로는 다음과 같이 파라미터에 기반해 피팅된 식과 상수항이 나오게 된다.
여기서 고민할 점은 Traffic load, QueueLength 만 사용해도 충분한가? 이다.
결국 1. 에서 서술한 보다 큰 SDWN 환경에서를 시뮬레이션 해봐야 더 자세한 갈래가 잡히겠지만, 우선 생각나는 부분은 "Over fitting"의 문제이다. 파라미터를 늘린다는 것은 차원이 늘어난다는 뜻이기 때문이다.
지금 생각나는 방법은 해당 데이터를 C4.5 DT에 넣고 돌려서 어떤 variable을 기준으로 branch를 하는지를 따지거나,
PCA, Autoencoder 등의 방법을 활용해볼 수 있을 것 같다.
즉, 무턱대고 파라미터를 늘리지말고 먼저 Queue Length와 Traffic load parameter들이 얼마나 시뮬레이션 데이터들을 표현해내고 있나를 확인할 필요가 있을 것 같다.
(PBP, EED 둘 다 테스팅.)
3. Reinforcement Learning
아직 3학년 학부과정의 기계학습 내용만 수강한 상태라, RL에 대해서는 자세히 분석이 어려웠던 점이 아쉽다.
일단 지금 생각이 되는 것은 Learning rate, Discount factor 부분이다.
(GPT 검색 결과)
- Learning Rate (학습률):
- 학습률은 강화 학습에서 새로운 정보를 얼마나 빨리 학습할지를 결정하는 요소입니다.
- 새로운 정보를 얻을 때마다, 학습률은 그 정보를 기존의 지식에 얼마나 합치는지를 조절합니다.
- 너무 큰 학습률은 불안정성을 초래할 수 있으며, 너무 작은 학습률은 학습에 시간이 오래 걸릴 수 있습니다.
- 일반적으로는 0과 1 사이의 값으로 설정하며, 적절한 학습률을 찾기 위해 여러 실험이 필요할 수 있습니다.
- Discount Factor (할인 요인):
- 할인 요인은 미래의 보상을 현재 가치로 얼마나 중요하게 고려할지를 결정하는 요소입니다.
- 0에서 1 사이의 값으로 설정되며, 0에 가까울수록 미래의 보상을 덜 중요시하고, 1에 가까울수록 미래의 보상을 더 중요시합니다.
- 할인 요인이 낮을수록 에이전트는 즉각적인 보상을 선호하게 되며, 높을수록 장기적인 누적 보상을 고려하게 됩니다.
- 할인 요인은 에이전트가 불확실한 환경에서 더 강건하게 행동하도록 도와줍니다.
본 논문에서는 Discount factor에 대한 언급은 아예 없고, Learning rate의 경우 Constraint를 만족시키지 못하는 경우 0, 아닐시 1인 on/off 개념을 표현하고 있다.
Discount factor는 Grid search, Try & error 등으로 고정된 상수를 얻는다고 치고, Learing rate에 대해 살펴보았다.
여기서 Learning rate α를 dynamic하게 설정해줄 수는 없을까?
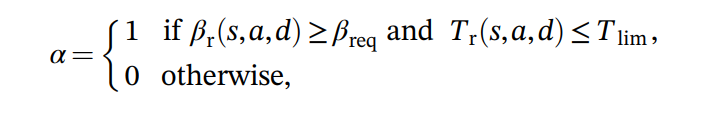
여기서 사용자가 직접 입력하거나, 툴을 돌려보거나 해서 SNR, EED에 대해 위반했을 때 가중치를 찾는다.
시뮬레이션될 SDWN 환경에서 SNR, EED에 대한 weight을 정해준 다음에, SNR, EED Constraint를 지키지 못할 경우
'0'이 아니라 (SNR error weight) * SNR + (EED error weight) * EED ( if α is greater then criterion, then α =0 )을 하여 조금더 약화된 learning rate rule을 적용하는 것이다.
이러한 방법을 활용한다면 물론 Constraint를 위반하는 경우가 가끔 발생하겠지만, 위반률은 여전히 제어가 가능하고, 감당 가능한 위반률 사이에서 best route를 찾으므로 더 큰 성능 향상이 가능할 것 같다.
4. PERFORMANCE
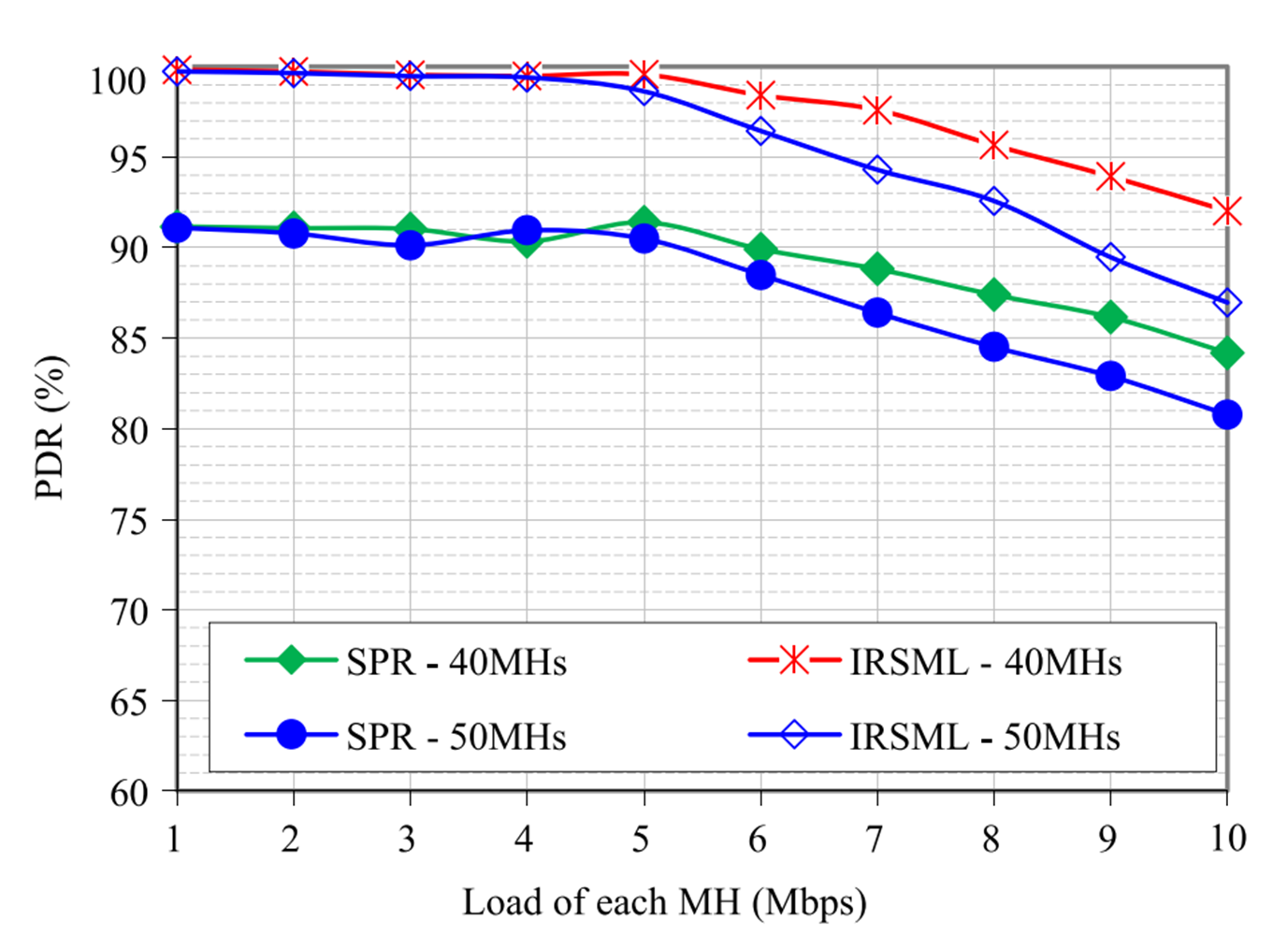
이 결과가 과연 IRSML의 성능이 얼마나 뛰어난지 잘 설명하고 있을까?
논문에도 써있듯이, routing protocol에 있어서 RL은 이미 널리 쓰이고, 관심받고 있는 알고리즘이다.
이러한 관점에서, 성능 비교 대조군이 SPR인 점은 상당히 아쉽다.
아예 ML을 사용하지 않은 알고리즘과 IRSML과의 비교는 좋지만, 중간 과정에 RL만 사용하거나 SL만 사용한 다른 알고리즘과의 성능도 비교하거나, 아예 SPR과 비교를 하지 않고 다른 ML approach algorithm들과 비교를 했으면 더 좋았을 것 같다.
그리고 이 문제는 개인의 생각에 따라 다를 수 있지만, SPR과 IRSML의 Computing power 요구량은 당연히 다를 것이다.
SDN controller의 computing power 소모량에 비해, 위의 성능 차이는 의미가 있는 차이일까? 역시 생각해볼 가치가 있는 문제이다.
'구현' 카테고리의 다른 글
| IRSML 시뮬레이션 직접 구성하기 - 4 (0) | 2024.02.22 |
|---|---|
| IRSML 시뮬레이션 직접 구성하기 - 3 (0) | 2024.02.14 |
| (NS-3) IRSML 시뮬레이션 직접 구성하기 - 2 (0) | 2024.02.06 |
| (NS-3) IRSML 시뮬레이션 직접 구성하기 - 1 (0) | 2024.01.17 |
| IRSML 논문 구현 아이디어(알고리즘) (0) | 2024.01.04 |