* DREAM: Dynamic Resource and Task Allocation for Energy Minimization in Mobile Cloud Systems
Jeongho Kwak, Member, IEEE, Yeongjin Kim, Student Member, IEEE, Joohyun Lee, Member, IEEE,
and Song Chong, Member, IEEE를 읽고 작성된 글입니다.
0. Abstract
최근에는 Edge computing 등 다양한 기술이 모바일 단에서 이루어지기 때문에 모바일 장치들의 에너지 소비가 급증하는 추세이다. 하여 이에 대한 대안들이 많이 제시되어왔는데, 그 예시로는 "Mobile cloud offloading"이 있다.
Mobile cloud offloading이란 모바일 장치의 task를 cloud server로 오프로딩하는 기술이다.
Offloading이란 특정 컴퓨팅 작업, 데이터 처리 또는 기타 리소스 집약적인 Task를 한 장치나 시스템에서 다른 장치나 시스템으로 이전하는 과정을 의미한다.
이전 연구들은 고정된 네트워크 환경에서 단일 유형의 Task에 중점을 두었지만, 현실의 네트워크 환경은 동적인 경우가 대부분이다. 또한 일반적인 모바일 장치들은 Single type Task가 아닌, 네트워크 트래픽, cloud offloading 가능/불가능 작업, CPU frequency scaling, network interface selection 기능과 같은 다양한 Type이 있다.
따라서 본 논문에서는 먼저 실제 모바일 환경에서 다음 세 가지 dynamic problem을 고려한다.
1. Cloud offloading policy. 즉, local CPU resource 또는 cloud resource 사용 결정
(어떤 resource를 사용할지?)
2. 네트워크를 통한 task 전송 및 local CPU에서의 task 처리 할당.
(어디서 task를 처리할 지?)
3. CPU clock 속도 및 네트워크 인터페이스 제어.
논문은 Lyapunov optimization을 사용하여 DREAM 알고리즘을 제안하고, 주어진 딜레이 제약에 대해 CPU 및 네트워크 에너지를 최소화한다는 것을 수학적으로 증명한다.(약 35% 이상 절약이 가능하다.)
또한 DREAM 아키텍처를 설계하고 현실 세계에서 DREAM의 적용 가능성을 보여준다.
* Lyapunov optimization
동적 시스템의 안정성을 보장하며 성능을 최적화하는 방법이다. 시스템의 상태를 시간에 따라 추적하여 특정 성능 지표를 최적화하는 방향으로 동작한다.
- Lyapunov Function
에너지와 유사한 개념으로 시스템의 현재 상태가 주어졌을 때 그 상태의 안정성을 수치적으로 나타내는 스칼라 값이다. 이 함수의 값이 시간에 따라 감소한다면 시스템은 안정적으로 간주된다.
- 접근 방식
Lyapunov function의 도함수를 최소화하는 제어 정책을 찾는다. 이를 통해 시스템이 장기적으로 안정되며 주어진 성능 목표를 달성할 수 있도록 한다.
- Lyapunov function의 정의
시스템의 특성과 안정성을 평가하려는 목적에 따라 달라진다. 주로 다음의 단계를 거친다.
1. 시스템의 동적 방정식 정의
- 방정식은 현재 상태에서 미래 상태로의 전이를 기술한다.
2. 후보 함수 선택
- Lyapunov function의 후보로 적합할 수 있는 함수를 선택한다. 이 함수 f(x)는 항상 양의 값을 가지며, 시스템이 안정된 상태에 있을 때는 값이 0이어야한다.
3. 도함수 계산
4. 부호 조건 검증
- 계산된 도함수가 모든 가능한 상태에 대해 음의 부호를 가져야한다. 이는 시스템이 시간이 지남에 따라 안정된 상태로 수렴함을 보장한다.
5. 조정 및 확인
- 도함수가 음의 부호를 가지지 않는 경우, 조정이 필요하다.
1. Introduction
최근 mobile device들에서 HIGH processing-demand application의 개발과 networking demands 증가가 많이 늘어난 추세이다. 이에 따라 모바일 기기들의 Maximum CPU clock frequency들도 올라가는 추세이다.
이러한 higher CPU clock frequency는 많은 에너지 소비량을 야기한다.(CPU의 Clock frequency가 높아질 수록 CPU의 소비 전력이 superlinear하게 늘어난다.)
이러한 mobile device들에서의 에너지 소비를 줄이기 위해, mobile cloud computing과 CPU/network speed scaling은 많은 관심을 가지게 되고있는 분야이다.
Mobile cloud computing(MCC)는 컴퓨터의 workload를 local 장치에서 cloud server로 offloading하는 것으로 에너지 소비 또는 delay와 같은 비용을 최소화하는 것이 목적이다.
MCC는 task를 cloud server로 전송하면서 네트워크 에너지를 소비하는 반면, local computing은 mobile device들의 local CPU energy를 소비한다. 이러한 이유로, offloading policy는 일반적으로 CPU와 networking 사이의 에너지 효율성을 비교하며 결정된다.
여기서 에너지 효율성은 {CPU 사용 또는 네트워킹 사용(전송) 작업량(bit) / consumed energy} 로 정의된다.
CPU energy efficiency
같은 양의 data에 대해 CPU energy efficiency는 2가지의 요인에 영향을 받는다.
1. 각 workload는 일반적으로 같은 양의 데이터를 처리하는데 다른 사이클 수를 요구하기 때문에 같은 양의 작업량을 처리하는데 필요한 에너지 소비는 작업의 유형에 따라 다르다.
(ex : 얼굴 인식 application의 계산량은 이미지 크기에 비해 매우 크기 때문에, 처리 밀도가 높은 application은 mobile device가 처리하는데 많은 local CPU 에너지를 소비하게 한다. 따라서 이미지 10mb를 업로하는 application보다 이미지 10mb를 인식하는 application이 훨씬 큰 local CPU energy 소비를 하게 되는 것이다.)
2. CPU processing energy는 clock frequency에 superlinearly하게 관계가 있기 때문에, 같은 양의 작업을 처리할 때의 에너지 소비는 클록 주파수에 따라 달라진다.
Networking energy efficiency
네트워크 에너지 효율은 네트워크 인터페이스의 유형(셀룰러/Wifi)뿐만 아니라 무선 채널의 상태에도 영향을 받는다.
예를 들어, mobile device가 셀룰러 네트워크보다 data rate이 높은 wifi network의 커버리지 안에 있다고 가정하자. 그렇다면 해당 장치는 느린 셀룰러 네트워크에 비해 data rate이 높은 Wifi network를 사용하여 비트 당 훨씬 적은 networking energy를 소비하게 된다.

(a)는 network,CPU speed와 에너지 소비의 상관 관계도를 모델링한 것이다. 셀룰러가 Wifi에 비해 높은 에너지 소비량을 보여준다. (그러므로 가능하다면, Wifi에 연결하는 것이 일반적으로 네트워킹 효율을 늘리는 방법일 것이다.) 또한 CPU의 clock 수가 늘어날 때마다 소비량이 지수적으로 증가하는 것도 볼 수 있다.
(b)는 시간에 따른 에너지 효율을 모델링한 것이다.
이전에 관련된 MCC 연구들은 고정된 workload, static한 network 환경, 그리고 구식 장치 기능을 가진 mobile device들의 에너지 소비와 delay를 최소하려고 시도해왔다. 그러나 실제 네트워크 환경에서 workload의 도착과 무선 채널이 static하지 않고, 시간에 따라 dynamic하다. 또한 Wifi network에 mobility가 있는 이용자의 경우 항상 커버리지 안에 있는다는 보장이 없다.(즉, 부분적으로만 이용이 가능하다.) 또한, 모바일 사용자는 장치의 CPU cloack frequency를 동적으로 제어하고 Wifi-셀룰러 간 네트워크 인터페이스를 선택이 가능하다. 따라서, Cloud offloading policy와 CPU/네트워크 속도 조절은 실제 mobile network 환경을 측정하여 제어되어야한다.
(작업량의 도착은 네트워크에서 처리해야할 데이터나 작업이 시스템에 입력되는 시점이다.)
dynamic한 cloud offloading policy와 CPU/network 속도 조절 policy는 workload의 도착, 네트워크의 상태 및 workload의 처리 밀도의 변화를 활용하여 주어진 delay 제약 조건에 대해 mobile device의 에너지 효율을 극대화한다.
예를 들어, data rate이 나쁜 3G 연결만 가능한 경우, task의 처리 밀도가 낮고 작업량의 도착률이 낮다면, offloading 정책은 에너지 소비를 줄이기 위해 낮은 clock frequency를 가진 local CPU 자원 사용을 우선시할 수 있다.
또 다른 예로 네트워크의 상태가 좋은 경우, task의 처리 밀도가 높고 작업량의 도착률이 높을 때 에너지 효율적인 Wifi network를 통해 작업량을 전송합으로써 cloud computing resource를 사용할 가능성이 있다.
즉, 네트워크 상태가 나쁜 경우 offloading을 시도하는 것이 에너지 효율성이 떨어진다. 따라서, 이 때는 로컬에서 데이터를 처리하는 것이 좋다. 또한 낮은 clock frequency를 이용하여 CPU의 에너지 소비를 추가로 줄일 수 있다.
(느려지는 건 어쩔 수 없다.)
네트워크 상태가 좋은 경우 처리 밀도가 높고(얼굴 인식과 같은 high computing power demand application) 데이터양이 많은 task를 offloading 하는 것이 효율적이다. 따라서 local에서 cost가 높은 task를 처리하지 말고, cloud server로 데이터를 전송하는 것을 선택할 수 있다.
그렇다면 동적 MCC policy와 CPU/네트워크 속도 조절은 얼마나 효과적일까?
위에 첨부한 그래프에 따르면, 다양한 CPU 및 네트워크 resource 중에서 가장 효율적인 선택이 task의 처리 밀도, CPU clock speed, 시간적 채널/네트워크 연결성(즉, LTE와 Wifi의 가용성)의 변화와 같은 아주 다양한 요인에 따라 달라진다는 것을 관찰할 수 있다. 이러한 많은 요인의 가변성 때문에 정적인 optimal MCC policy나 CPU/네트워크 속도 조절 정책은 존재하지 않으며, dynamic approach를 해야함을 알 수 있다.
dynamic resource assignment approach(즉, Dynamic MCC policy, CPU clock speed selection 및 네트워크 인터페이스 선택)은 더 많은 에너지를 절약할 수 있지만, offloading policy에 offload가 가능한 task만 고려하게 되면 offload 불가능한 작업이나 네트워크 트래픽과 같은 다른 type task들과 자원 간섭 문제가 발생이 가능하다.
예를 들어, mobile device가 동시에 offload 가능한 작업(ex:체스 게임 or 얼굴 인식 처리), offload가 불가능한 작업(ex: 장치의 OS 수준에서의 처리) 그리고 업링크 네트워크 트래픽(ex: Dropbox와 같은 클라우드 서버로 파일 전송)을 처리하거나 전송한다고 가정해보자.
만약 MCC가 local CPU를 선택했을 경우, local CPU가 PA,CA Queue의 task를 동시에 처리하려고 하기 때문에 간섭이 일어날 수 있다.
만약 네트워크 자원을 선택했을 경우, Network traffic의 간섭이 일어난다.
따라서 이 문제는 dynamic resource assign에서 해결되어야한다.

이 논문에서는 Mobile cloud system에서 CPU/네트워크 resource 및 task 할당 알고리즘인 DREAM을 제안한다.
이 알고리즘은 네트워크 트래픽 및 offload 가능/불가능한 작업을 통합된 프레임워크 내에서 고려하여 delay 제약 조건을 충족하는 동시에 mobile device의 에너지 소비를 최소화한다. 이 방법은 Lyapunov optimization을 사용하여 cloud offloading policy와 CPU/네트워크 속도 조절을 공동으로 최적화하는 방법이다.
더 구체적으로 DREAM은 다음을 제어한다.
1. CPU 및 네트워크 resource를 위한 task(traffic/workload) type 선택
2. CPU 에서의 clock speed 조절
3. 네트워킹에서의 인터페이스 선택
본 논문에서는 3G/LTE/Wifi와 같은 셀룰러/Wifi의 커버리지와 Data rate, 대중적인 스마트폰 모델에서 CPU와 네트워크 인터페이스의 에너지 소비에 대한 실제 측정치를 기반으로 시뮬레이션을 수행한다.
해당 실험은 안드로이드 플랫폼에 실제 구현이 된 후, 상용 Windows Azure mobile cloud system에 설치된 서버를 이용하여 진행되었다고 한다.
DREAM 알고리즘은 다음의 효과가 있다.
1. Lyapunov 방법을 활용해 dynamic mobile network 환경에서 Cloud offloading policy와 CPU/network 속도 조절을 공동으로 최적화하는 최초의 방법이며, delay 제약을 만족하며 동시에 CPU/네트워크 에너지 소비를 최소화한다.
2. 자원 간섭 문제를 최초로 해결한다. (공동 스케줄러의 도입.)
3. 실제 네트워크 환경에서의 시뮬레이션을 통해 현실 세계에 대입이 되었을 때를 제시한다.
2. System model
A. Task and Traffic Arrival Model
위에 두번째 그림을 보면, 본 논문에서는 스마트폰의 task를 3가지 유형으로 분류한다. (PA, CA, NA)
PA는 offload가 불가능한 workload, CA는 CPU 자원 또는 네트워크 자원 중 하나를 활용할 수 있는 workload이다.
NA는 네트워크 트레픽이다. PA와 NA는 각각 하나의 자원 유형만을 활용할 수 있다.
t={0,1,...}으로 시간 슬롯 시스템을 가정하며, 단위는 second이다.
각 시간 슬롯에서 A(t) = (Ap(t),Ac(t),An(t))양 만큼의 workload 또는 traffic이 PA,CA 및 NA에 도착하며, A(t)는 모든 시간 슬롯에서 i.i.d 조건을 만족한다. 또한 E[AP(t)] = λP, E[AC(t)] = λC, E[AN(t)] = λN 이다.
모든 도착이 각 시간 슬롯에서 APmax, ACmax Anmax를 넘지 않는다고 가정하자.
B. Processing and Networking Model
workload를 순차적으로 처리할 CPU는 단일 코어 CPU를 탑재한 스마트폰 모델을 고려한다.
현대의 스마트폰 프로세서는 DVFS(동적으로 전압과 주파수를 조절하는 기능)을 갖추고 있어 프로세서가 매 시간 슬롯 t마다 CPU cloack speed rc(t) ∈ {rc,1, rc,2, ..., rc,max}를 조정할 수 있다. 각 workload는 각자 다른 CPU 처리 자원을 필요로한다. 예를 들어 체스 게임은 이미지 검색 어플리케이션보다 훨씬 높은 계산량을 요구한다. 이 개념을 "처리 밀도"라고 정의하며, PA = γP, CA = γC라 표현한다. 단위는 cycle/bit 이다.
또한, PA 또는 CA는 각 시간 슬롯에서 CPU에 의해 처리되며, 시간 슬롯 t에서 CPU의 CA 스케줄링 indicator를 θc(t) ∈ (0, 1)로 나타낸다. 즉, CA가 스케줄러에 의해 스케줄링될 때를 θc(t) = 1로 나타내고, PA가 스케줄링 될 때를 θc(t) = 0으로 나타낸다.
네트워크 인터페이스로는 셀룰러(L)과 Wifi(W)를 고려한다. 스마트폰은 셀룰러와 Wifi 사이에서 전송할 인터페이스를 선택하거나 에너지 절약을 위해 어떠한 인터페이스도 사용하지 않을 수 있다.(N) 셀룰러 네트워크는 항상 사용 가능한 반면 Wifi 네트워크는 사용자의 이동성에 따라 간설적으로 사용 가능하다고 가정한다. 따라서 장치의 위치에 따라 가능한 네트워크 인터페이스의 정의역은 {W,L,N} 혹은 {L.N}이다.시간 슬롯 t에서의 네트워크 속도 rn(l(t),t)는 선택된 인터페이스 l(t) ∈ B(t)와 체널 조건에 의해 결정된다. 동일한 네트워크 인터페이스 l(t)에서도 동적인 채널 조건에 의해 네트워크 속도 rn이 변할 수 있다.
CA workload가 Network resource로 처리될 경우, 해당 workload는 cloud data center로 전송된다. cloud server의 computing speed는 mobile devices의 max computing speed(rc,max)보다 훨씬 빠르다고 가정한다. 따라서 클라우드 서버단의 처리 시간은 가정하지 않고, CA 작업이 network로 offloading 되기로 결정했다면 지연시간은 스마트폰 내의 대기 시간만 계산하기로 한다. 작업 처리 결과의 위치는 로컬 스마트폰이거나 클라우드 서버일 수 있으며, 어플리케이션 코드는 mobile device나 클라우드 서버 양쪽에 이미 존재한다고 가정하자.스마트폰이 CPU와 네트워크 자원에 대해 동시에 CA를 스케줄할 수 없다고 가정하다.즉, θc(t) + θn(t) ≤ 1 이다. 이 조건은 CA가 병렬 계산을 허용할 경우 완화될 수 있다. 최종적으로 주어진 모델에 대해 매 시간 슬롯 t마다 네 가지 제어 ( θc(t), θn(t), rc(t), l(t) )를 결정한다.
C. Task Queue Model
3가지 타입의 큐들은 다음과 같다.

Qp(t), Qc(t), Qn(t)는 타임 슬롯 t에서의 각 큐의 Queue Length를 표시한다. 그리고 [x]+ = max(x,0)이다.
각 큐에 제공되는 workload들의(departure) 표시는 각 시간 슬롯 t에서 ( θc(t), θn(t), rc(t), l(t) )에 의해 결정된다.
CPU 부분에서 rc(t)의 단위는 cycle/time 이고 QueueLength의 단위는 비트이므로, 예정된 큐에서 제공된 workload는 rc(t)를 처리 밀도 γP 또는 γC로 나눈 값이다.
즉 다음 시간 단위 t+1에서 큐의 길이는 Qp(t)에 처리량을 빼고, 다음 시간 단위에 도착하는 workload인 A(t)를 더하는 것이다. 이 때, Qc의 경우 네트워크로 offload가 되는 경우에 rn(l(t),t)로 네트워크 처리량도 빼줘야한다.
D. CPU and Network Energy Model
일반적으로 CPU energy consumption model은 다음과 같이 알려져있다.

지수 x는 [2~3]에서 정의되며 α와 β는 CPU 모델에 의해 결정되는 parameter이다.
대부분의 스마트폰은 기본적으로 셀룰러와 WiFi 인터페이스를 가지고 있으므로, 다음과 같은 에너지 소비량이 정의된다.


l(t)=N일 때는 local CPU만 돌아가므로 전송 에너지 소비를 0으로 잡는다.
여기서 PL,tx와 PW,tx 부분은 각각 셀룰러 전송 전력, WiFi 전송 전력 및 1 단위 시간 슬롯의 지속 시간을 나타낸다.
3. Dynamic Resource and Task Allocation Algorithm
앞서 정의한 요소들을 가지고 큐 안정성을 가지면서 에너지 최소화를 고려한 문제를 공식화 한다.
A. Problem Formulation
MCC를 위한 목표는 CPU 및 네트워크 resource, CPU clock speed, 네트워크 인터페이스 l(t)에 에 대한 스케줄링 indicator의 공동 제어 알고리즘 ( θc(t), θn(t), rc(t), l(t) )를 개발하는 것이 문제이다.
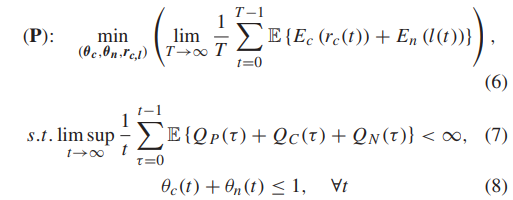
식 (6)은 시간 슬롯 t 동안 CPU 및 네트워크 인터페이스에서 소모된 에너지 합의 평균 값이다.(기대값)
식 (7)은 각 큐들의 평균 길이가 유한하게 유지되어야함을 의미한다.
식 (8)은 모든 시간 슬롯에 대해 스케줄러 indicator는 local CPU, network offload 중 하나만을 선택한다는 것이다.(병렬 불가)
B. Algorithm Design
Lyapunov drift + penalty technique으로 알고리즘을 디자인한다.
이 기법은 workload 도착과 미래 네트워크 상태의 분포에 대한 정보를 요구하지 않는다는 장점이 있으며, 현재 큐 길이와 처리량의 정보만을 알면 됩니다. 각 슬롯에 대해 목표를 설정하고(slot-by-slot objective), 목표는 (P)에서 전체 작업 큐를 안정화시키며 CPU와 네트워크 에너지 소비를 최소화하는 것이다. 다음은 Lyapunov drift, Lyapunov 함수를 다음과 같이 정의한다.

식 (9)는 PA, CA, NA 큐를 동등한 수준에서 안정화 하기 위해 디자인 된 것이다. 즉, 3개의 큐는 공평하게 최적화 되어 큐 길이가 유사하게 유지되어야 한다.
다음으로 장기 에너지 최소화 문제를 고려한다.

V는 energy-delay tradeoff parameter이다. 따라서 매 시간 슬롯마다 위의 목적함수를 최소화하는 것이 목표가 된다.
- Deriving an upper bound
Section 2에서 정의한 내용에 대해 몇가지 정리를 세울 수 있다.
Lemma 1. 어떠한 가능한 control variable들 (θc(t),θn(t)) ∈ {(0, 0), (1, 0), (0, 1)}, rc(t) ∈ {rc,1,...,rc,max }, l(t) ∈ B(t)에 대해 다음이 성립한다.

- Deriving the DREAM algorithm
우리는 다음의 Theorem 1에서 최적의 policy π∗가 있고, 이를 결정한다는 것을 보여줘야한다.
Theorem 1:
평균 arrivals , 및 E이 정의역에 있을 때, (λp,λc,λn) ∈ A 에서 각 시간 슬롯 t 마다 애플리케이션 스케줄링 , , CPU 속도 및 네트워크 인터페이스 를 선택하는 정상 상태의 무작위 제어 정책 이 존재하며 다음을 만족한다:
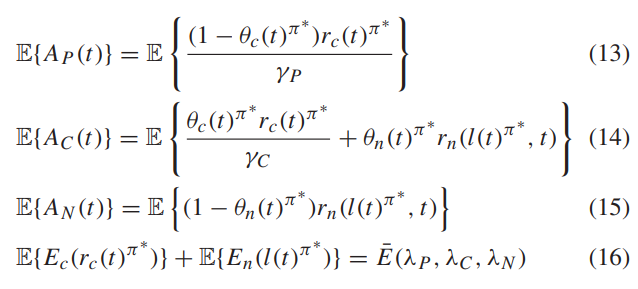

따라서 (16)은 cpu와 network의 energy 소비량의 합이 최소 에너지 정의치가 된다는 의미이다.
그럼 시간 슬롯마다 (12)의 Lemma 1에서 제시된 식의 왼쪽 측면을 최소화 하는 ( θc(t), θn(t), rc(t), l(t) )를 찾아 DREAM 알고리즘을 개발하는 것이다.
즉, 알고리즘은 (12)의 오른쪽 측면을 가능한 모든 고정 무작위 control policy에서 얻을 수 있는 값 중 가장 작은 값을 선택하는 것이다.
C. Dynamic Resource and task Allocation for energy minimization in Mobile cloud systems (DREAM)
DREAM 알고리즘은 현재의 무선 네트워크 상태를 이용해 최적화하므로 미래의 무선 네트워크 상태나 workload arrival에 대한 통계를 알 필요가 없다. DREAM 알고리즘은 CPU 와 network resource에서의 task schedule들과 CPU speed, network interface 선택을 각 시간 슬롯마다 다음과 같이 제어한다.

=> Dream 알고리즘은 CPU와 network resource들을 task들에 할당한다. (scheduling) 그리고 CPU clock speed와 network interface를 결정한다. Scheduling task는 2가지 케이스로 나뉜다.
Case I-1.

CA의 queue가 PA나 NA queue보다 크지 않을 때이다. (큐 길이를 처리밀도로 나눈 값)
CA queue는 CPU resource와 network resource를 공유하는 반면, PA는 CPU만, NA는 network만을 이용한다.
DREAM 알고리즘은 Queue Length 측면에서 작업간의 공정성을 고려하므로, Queue Length 측면에서 급한 PA, NA 큐가 먼저 처리된다. 그 후, PA와 NA를 스케쥴링 했으므로, 변한 값들에 대해 rc(t), l(t) 값을 업데이트 해준다.
Case I-2.

이 경우는 PA>CA>=NA인 경우이다. PA가 가장 급하므로 CPU 자원에서 스케줄되고 CA는 네트워크 자원에서 스케줄 된다. (17)과 똑같이 CPU speed를 업데이트하고, 변한 CA에 대해 인터페이스 select I(t)도 업데이트 해준다.
Case II-1.

PA<=CA<NA 이다. 이 경우 CA와 NA를 스케줄 해줘야한다. 이때 NA가 network resource를 받을 것이기 때문에 CA를 CPU에서 스케쥴한다. 그 후, 변한 CA 값에 대해 CPU speed를 업데이트하고 변한 NA에 대해 (18)과 같이 l(t)값을 업데이트해준다.
Case II-2.

CA가 가장 큰 경우이다. 위의 사례와 달리 CA는 큐 길이 측면에서 가장 급한 작업이므로 반드시 스케줄되어야한다. 그러니 CA는 CPU 자원 또는 network 자원 중 하나를 선택할 선택권이 부여된다. 즉, Network interface를 선택해서 offloading을 하는 것이 유리한지 아니면 local CPU에서 돌아가는게 유리한 지를 선택해야하는 것이다.
따라서 다음과 같은 비교를 한다.


정의를 보면 Yc(t)는 CPU speed rc(t)를 이용하여 계산된 CPU 에너지 Ec에서 Qc(t)의 처리 비용을 차감한 값이다. (CA 작업이 CPU 단에서 실행될 때의 비용)
Yn(t)는 같은 원리로 NA queue가 network resource를 이용할 때의 비용이다. 즉, CA가 CPU를 택했을 때의 비용이 Y이다.
Z는 반대로 CA가 Network를 선택했을 때의 비용이다.
즉, Y>Z 일 때는 Z를 선택해야한다. 따라서 이 경우 (PA,CA) 할당을 하고 반대로 Y<Z일 때는 (CA,NA) 할당을 선택한다. 그리고 그에 따른 변한 값들에 대해 CPU speed, Interface value를 update한다.

(17)을 보면 첫번째 항은 CPU 에너지 소비를 줄이려는 노력이며, 두 번째 항은 PA 큐를 줄이려는 시도이다 같은 V 값에서 처리 작업의 큐 길이가 길게 나오면, 해당 알고리즘은 큐 길이를 빠르게 줄이기 위해 rc(t)가 가능한 큰 경우를 선택할 것이다.

(18)을 보면 동일하게 첫번째 항은 에너지 최적화 두번째 항은 큐길이 최소화이다. 같은 V 값에서 NA가 짧다면, rn(l(t),t)가 높은 인터페이스보다 에너지 효율이 높은(En(l(t)) 인터페이스를 선택할 것이다. 또한 V를 통해 energy-delay trade off의 조정이 가능하다.(V가 커질 시, 에너지 요소가 크게 평가되어 delay가 길어진다.)
이 DREAM 알고리즘은 cloud offloading과 CPU,Network speed control을 동시에 고려하게 된다.(MCC, CPUspd,Network interface 모든 것을 고려한다.)
D. Theoretical Analysis
DREAM 알고리즘의 PA,CA 및 NA 큐 길이의 합과 평균 CPU 및 네트워크 에너지 소비의 합은 다음 정리에 의해 상한선이 결정된다.
Theorem 2 : t={0,1,…,T−1} 이라고 하자. 양의 e가 존재하여(λp+e, λc+e, λn+e)가 O의 정의역에 속한다고 생각하자.
(O는 PA,CA,NA의 arrival rate의 capacity region이다.)
그럼 다음의 정의가 성립한다.

(21)은 총 큐 길이 합의 기대 값이 우변보다 크지 않다는 뜻이고, (22)는 총 cpu,network 에너지의 소비 기대 값이 우변보다 크지 않다는 것이다.
Ec,D(t)와 En,D(t)는 DREAM이 적용될 때 t 동안의 CPU와 network의 에너지 소비를 의미한다. E*(e)는 cpu와 네트워크 에너지 소비 합계의 최적화 값이다.
(21), (22)는 Energy-delay의 trade off 관계로 설명될 수 있다. parameter v가 작아질 시, delay가 크게 평가되어 에너지 소비율이 늘어난다. 반면 V가 커지면 Energy가 높게 평가되어 큐의 길이가 늘어난다.
실제로는 셀룰러 인터페이스가 데이터를 몇 초동안 전송한 후에 tail energy를 소비하는 반면, WiFi 인터페이스는 소비하지 않는다. 따라서 시뮬레이션은 테일 에너지까지 포함해서 진행되어야한다.
'논문' 카테고리의 다른 글
| Learning Transferable Visual Models From Natural Language Supervision - CLIP (0) | 2024.06.27 |
|---|---|
| DREAM: Dynamic Resource and Task Allocation for Energy Minimization in Mobile Cloud Systems - 2 (0) | 2024.05.02 |
| ML System for Routing Decision in Urban VANET - 1 (0) | 2024.01.15 |
| SL, RL을 기반으로 한 라우팅 알고리즘 - 5(Conclusions) (0) | 2024.01.02 |
| SL, RL을 기반으로 한 라우팅 알고리즘 - 4 (0) | 2024.01.02 |