0. Abstract
이 논문은 다양한 개방형 카테고리를 위한 일반화 능력을 향상시키는 Recognize Anything Plus Model(RAM++)을 소개한다. 이전 접근법들(CLIP 등)은 주로 이미지와 함께 제공되는 global supervision을 활용했으나, 이는 여러개의 개별 의미 태그를 인식하는데 있어 최적의 성능을 발휘하지 못했다.
반면, RAM++는 개별 태그 supervision과 global text supervision을 통합한 통합 정렬 프레임워크 내에서 원활히 통합될 수 있다. 이 통합은 사전 정의된 태그 카테고리의 효율적인 인식을 보장할 뿐만 아니라 다양한 open-set 카테고리에 대한 일반화 능력을 강화한다.
또한 RAM++는 의미론적으로 제한된 태그 Supervision을 더욱 확장된 태그 설명 Supervision으로 변환하기 위해 대규모 언어 모델을 사용하여 open-set visualization concept의 범위를 넓게 만들어준다. 다양한 이미지 인식 벤치마크에서의 평가는 RAM++이 대부분의 측면에서 SOTA를 능가함을 볼 수 있었다.
1. Introduction
이미지 인식은 CV에서 중요한 연구 분야로, 모델은 제공된 이미지의 다양한 의미를 추출하여야 한다.
이를 위해 CLIP, ALIGN, Florence와 같은 vision model들은 인터넷에서 대규모 이미지-텍스트 쌍을 활용하여 광범위한 데이터 셋을 구축하였다. 이러한 과정을 통해 학습된 모델들은 단일 라벨 이미지 분류에서 뛰어난 오픈셋 추론 능력을 보여주며, 다양한 도메인 특화 데이터 셋에 임의의 시각적 개념이 포함된 경우에도 일반화 능력을 기반으로 효과적인 적용이 가능하다.

위의 그림은 multi-grained text supervision의 그림이다. Global text supervision은 여러 의미를 얽히게 하여, 여러 개별 의미 태그를 인식하는 데 sub-optimal performance를 가져온다. 본 연구의 모델은 여러 개별 tag super vision과 global text supervision을 모두 활용하여 pre-trained category와 open-set category 모두에서 tagging 능력을 향상시키는 것이다.
또한 LLM을 통해 tag supervision을 보다 광범위한 tag description supervision을 사용하여 다양한 오픈셋 카테고리에서 시각적 개념을 인식할 수 있도록 한다.
이러한 발전에도 불구하고, 이 모델들은 주로 Global text supervision에 의존한다.
이는 global text embedding을 해당하는 global vision feature와 직접 연결하는 것이다.
이러한 방식은 더 복잡한 multi tag 인식 작업에는 최적이 아니며, Global text supervision은 여러 의미를 얽히게 하며 개별 태그의 의미를 퇴색시키는 경향이 있다.
(문장의 포괄적인 의미를 이해하는 것은 이미지 내의 여러 객체나 개념을 각각 정확하게 인식하고 태그하는 것을 목표로 하는 multi tag task에서 문제가 된다.)

다양한 벤치마크에서 제로샷 이미지 인식 성능 비교이다. RAM++ 모델은 최신 open set image tagging 모델들 (CLIP 및 RAM)을 넘는 tagging 성능을 보여준다.
즉 global text supervision과 individual tag supervision을 전부 참조하여 일반화 능력의 향상을 꾀하겠다는 아이디어가 먹혀들어간 것이다.
그렇다고 전부 individual tag supervision을 사용하는 모델은 주로 제한된 규모의 수동으로 주석이 달린 image tag를 활용한다. 최근 연구들은 image-text 쌍을 활용하여 image teg의 규모를 크게 확장했음에도 불구하고, image tagging model들은 여전히 pre-train label system을 넘어서는 tag category를 인식하는데 한계가 있다. (openset 추론 성능 떨어짐)
이러한 점을 고려하면, multi-grained text supervision을 활용하는 open set image tagging model의 필요성을 제기할 수 있다.
이 모델은 global text supervision과 individual text supervision을 통합한 사례이며, image tag는 텍스트에서 자동으로 파싱되어 더 세밀한 supervision을 제공하며, 이는 pre-train된 tag 카테고리에 대한 효과적인 인식을 돕는다.
동시에 다양한 text supervision은 모델이 고정된 tag 카테고리를 훨씬 뛰어넘는 넓은 범위의 텍스트 의미론을 학습하도록 하여 open set 일반화 능력을 상승시킨다.
구체적으로 통합된 정렬 프레임워크 내에서 Image-Tag-Text 삼중항을 결합하는 것이다. Multi-grained text supervision은 효율적인 정렬 디코더를 통해 시각적 공간 특성과 상호 작용한다. 기존의 유명한 정렬 패러다임과 비교했을 때, 해당 접근 방식은 높은 효율성으로 우수한 tagging 성능을 보여준다.
더 나아가, tag supervision의 불충분한 vision 개념을 고려하여 LLM을 통해 tag supervision을 더 확장된 tag description supervision으로 전환한다. LLM은 각 tag 카테고리에 대해 다양한 시각적 설명을 자동으로 생성하는 데 사용된다.
LLM에 의해 생성된 description들은 이후에 automatic re-weighting mechanism에 tag embedding에 통합된다.
이는 해당 이미지 특징과의 관련성을 강화한다. 이 접근 방식은 image tagging model의 시각적 개념 범위를 풍부하게 하여, 추론 중 open set 인식을 위해 시각적 설명을 통합할 수 있는 능력을 향상시킨다.
예를 들어, "코기"라는 tag는 LLM을 거쳐 "짧은 다리를 가진 소형 개"라는 더 상세한 설명으로 확장될 수 있다.
따라서 제안된 접근 방식을 기반으로, 다양한 tag category를 인식하는 뛰어난 능력을 갖춘 open set image tagging model인 Recognize Anything Plus(RAM++)를 소개한다.
다음은 해당 논문의 대표적인 컨셉이다.
1. Image-tag-text 삼중항을 통합된 정렬 프레임워크 내에서 결합하여, 사전 정의된 tag 카테고리에서 우수한 성능을 달성하고 open set 카테고리의 인식 능력을 확장한다.
2. LLM의 지식을 tagging training 단계에 통합하려는 최초의 시도이다. 모델이 추론 중 open set category 인식을 위해 시각적 설명 개념을 통합할 수 있게 해준다.
3. Open set tagging model 중 최고의 성능을 보여줬으며, multi grained text supervision의 성능을 입증했다.

Image-tag-text 삼중항을 사용하여 RAM++는 Alignment Decorder로 image-text, image-tag를 동시에 정렬한다.
여기서 tag는 ChatGPT를 통해 확장된다. Individual tag supervision은 pre train된 tag 카테고리의 효율적인 인식을 보장하며, 다양한 text super vision은 open set tagging 능력을 향상시킨다.
2. Related Works
1. RAM++은 기존 모델에 비해 얻는 장점은 open set tagging 능력이 좋다.
2. Image + Text 쌍을 활용하는 CLIP과 같은 모델은 많았지만, 이들은 개별 의미의 multi tag task에서 global text supervision에 의존하는 문제점을 가지고 있다. 또는 깊은 vision-language feature fushion을 택한다고 해도 광범위한 tagging 작업에서 효율성과 용량의 한계를 가지고 있다. 이와 대조적으로, RAM++는 통합된 정렬 프레임워크 내에서 여러 텍스트와 개별 태그를 정렬하여 높은 효율성으로 우수한 tagging 성능을 보여준다.
3. 여러 선행 연구들은 텍스트 기반 설명을 이미지와 multi modal 컨셉으로 근사하여 이미지 인식 성능을 향상시켜왔다.
그러나 이전 연구들은 모두 외부 자연어 DB에 의존하였다. 이러한 접근과는 다르게, 본 연구에서는 Image tagging의 훈련 과정에 LLM 지식을 통합하는 것을 선도하고 있으며, 이는 Tagging model의 open set 능력을 향상시키는 방법이다.
3. Approaches
3.1. Overview Framework

위의 사진과 같이 RAM++의 구조는 이미지 인코더, 텍스트 인코더, 정렬 디코더로 구성된다. 훈련 데이터는 이미지-텍스트 쌍과 텍스트에서 파싱된 이미지 태그를 포함하는 이미지-태그-텍스트 삼중항이다. 훈련 과정동안 모델에 입력되는 것은 다양한 배치 텍스트와 고정된 태그 설명이 동반된 이미지이다. 모델은 각 이미지-태그/텍스트 쌍에 해당되는 정렬 확률 함수를 출력하며, 이는 Loss funcation에 의해 최적화 된다.
3.2. Multi-Grained Text Alignment
- Unified Image-Tag-Text Alignment Paradigm : Image-tag-text 삼중항을 사용하여 RAM++는 이미지-텍스트와 이미지-태그를 동시에 정렬하는 공유 정렬 디코더를 채택한다. Batch Text는 Text encoder를 통과하여 global text embedding을 추출한다. 이 text embdding은 이후 정렬 디코더의 Cross-attention layer를 통해 이미지 특징과 연결된다.
정렬 디코더는 두 개의 층으로 구성된 attention decoder로써.광범위한 카테고리를 포함한 이미지 tagging 작업의 효율성을 보장한다. Self-Attention을 생략하여 Tag embedding 간의 상호 영향을 제거하였다. 따라서 모델이 성능에 영향을 주지 않고 어떤 양이던 상관없이 Tag Category도 인식할 수 있게 된다.(Individual)
self-attention을 없애면 tag 간의 독립성을 유지할 수 있다. (tag 간의 상호 의존성 삭제)
따라서 tag가 몇 개가 되던간에 multi tagging이 가능해진 것이다.

- Alignment Paradigm Comparison : 위의 그림에서는 ITTA(Image-Tag-Text-Alignment)를 다른 주요 정렬 패러다임과 비교한다.(정렬은 이미지와 텍스트 사이의 의미적 관련성을 매핑하고 동기화하는 과정을 의미한다.)
CLIP과 ALIGN에서 채택된 ITC(Image-Text-Comparison)과 ALBEF 및 BLIP에서 채택된 ITM(Image-Text Matching)과의 비교를 하였다.
ITC는 dot product를 통해 여러 이미지와 텍스트의 global feature를 동시에 정렬하여 높은 효율성을 보인다. 그러나 Global Text Supervision에 의존하며 여러 개별 tag의 spatial 인식 성능이 떨어진다.(Multi-tagging 불가)
ITM은 deep align decorder를 활용해 심층적 시각-언어적 특징을 융합한다. 그러나 단일 이미지-텍스트 쌍만 처리하여 훈련 및 추론 시 상당한 계산 비용이 발생한다.
ITTA는 Global Text Supervision과 inidividual text supervision을 융합하였다. 이는 사전 정의된 카테고리뿐만이 아니라 open-set 카테고리에 대해서도 견고한 tagging 성능을 보장한다. 추가적으로 이미지의 global feature 대신 spatial feature를 사용하여 태그가 종종 다양한 이미지 영역에 매칭되는 것을 고려한다. 결과적으로 ITTA는 성능과 효율성 사이의 균형을 맞추며, 수천 개의 태그 카테고리와의 이미지를 높은 효율성으로 정렬할 수 있는 능력을 갖추고 있다.
3.3. LLM-Based Tag Description
LLM 기반 Tag Description 생성은 LLM의 지식을 활용하여 의미적으로 제한된 Tag Supervision을 넓은 의미로 확장하는 것이다. 이를 통해 설명할 수 있는 open set visual concept의 범위를 풍부하게 한다.
- LLM Prompt Design : LLM 프롬프트 디자인은 label 시스템 내에서 각 tag 카테고리에 대한 설명을 얻기 위해 필수적이다.
본 연구에서는 LLM에 의해 생성된 Tag 설명이 주로 2가지 특성을 지닐 것이라고 예측하였다.
1. 가능한 다양한 시나리오를 포괄할 수 있드록 다양하게.
2. 높은 관련성을 보장하기 위해 이미지 특징과 가능한 한 관련성 있게.
이에 따라 5가지의 프롬프트를 디자인 했다.
1. "Describe concisely what a {} looks like."
2. "How can you identify a {} concisely?"
3. "What does a {} look like concisely?"
4. "What are the identified characteristics of a {}"
5. "Please provide a concise description of the visual characteristics of {}"
- Tag Description Generation : Tag Description Generation은 LLM 프롬프트를 기반으로 각 Tag 카테고리에 대한 설명을 자동적으로 생성한다. 결과적으로 각 프롬프트에 대해 10개의 반응을 획득하여 카테고리당 50개의 태그 설명을 수집한다.
여러 후보 Tag Description에서 선택적 학습을 가능하게 하기 위해, Multiple tag description을 처리하기 위한 자동 re-weighting module을 설계하였다. 다음의 그림을 참고해보자.

Cat이란 카테고리에 의해 생성된 50가지의 Tag를 임베딩하여 Image의 Global Feature와 내적된다.
여기서 Reweight으로 최종 output은 다음과 같이 결정된다.

3.4. Online/Offline Design
이미지-텍스트 정렬과 이미지-태그 정렬 작업을 통합하기 위해 Online/Offline Design을 채택하였다. 이미지 태깅의 경우, 50개로 태그 설명의 수는 고정되어 있지만, 그래도 큰 볼륨을 지닌다. (ex: 4500개 태그 x 50개 설명)
모든 태그 설명의 임베딩을 추출하는 것은 시간이 많이 걸리지만, off-the-shelf text encoder를 사용함으로써 오프라인에서 설명 임베딩을 사전 처리할 수 있다.(GPT 등)
반면, 이미지-텍스트 정렬은 배치 크기에 의해 결정되는 변수 텍스트 입력을 다루며, 상대적으로 적은 볼륨이다. 따라서 개별 배치에 대한 텍스트 임베딩을 온라인으로 추출하여 계산 비용 부담을 줄일 수 있다.
4. Experiment
4.1. Experimental Settings
- Training Datasets : 공개 이미지-텍스트 쌍 데이터셋을 기반으로하며, 4백만 이미지 데이터셋과 1400만 이미지 데이터셋의 두 가지 설정을 포함한다. 4백만 설정은 인간이 주석을 단 데이터 셋(COCO,VG)등을 포함한다.
라벨 시스템은 텍스트에서 흔히 사용되는 4585개의 카테고리를 포함한다.
- Implementation Details : ImageNet에서 사전훈련된 SwinBase를 이미지 인코더로 사용하고, 텍스트 인코더는 CLIP에서 제공하는 텍스트 인코더를 사용한다. (텍스트 및 태그 설명 임베딩 추출).
이미지 - 텍스트 정렬 및 이미지 태깅을 위해 ASL의 정렬 손실 함수를 채택하였다. 많은 사전 훈련 모델을 사용하여 4M, 14M 버전의 RAM++는 각각 1일, 3일 만에 8개의 A100 GPU를 사용하여 훈련을 완료하였다.

- Evaluation Benchmakrs : multi tag 인식 성능을 평가하기 위해 널리 사용되는 평가 지표인 mAP를 사용했다. 사용한 벤치마크는 OpenImages, ImageNet을 사용하였는데, ImageNetMulti는 포괄적인 주석을 가진 다중 레이블을 가지게 한 버전이다. Common Uncommon 카테고리는 RAM++ 레이블 시스템에 포함되는지, 안되는지에 따라 나뉜다.
(즉 Uncommon 카테고리는 open-set 능력을 테스트하게 될 것이다.)

사진상 녹색 부분은 vertical domain training datasets에서 fully supervised 되었을 때를 의미한다.
Inference Prompt는 모델 추론시 사용되는 카테고리 프롬프트를 지칭하며 예를 들어 handwritten의 경우 "A photo of a cat". LLM Tag Description의 경우 "Cat is a small general with soft fur..."을 가리킨다. *는 CLIP을 활용한 모델을 나타낸다.
또한 HICO 벤치마크의 경우는 인간과 객체간의 상호작용에 대한 널리 인정받는 표준이라고 한다.
4.2. Comparison with SOTA
- Quantitative Results : 결과를 해석해보자면, CLIP과 BLIP 등의 Text Supervision model들은 다중 태그 인식에 있어많은 성능 저하가 일어난다.
RAM은 Common category에서 성능이 좋게 나오나 Openset 추론인 Uncommon에서 성능 저하가 나타난다.
또 특이 사항으로는 RAM은 LLM Tag Description을 사용하였을 때 오히려 성능이 떨어졌는데 이는 Tag Supervision의 제한적인 의미론 때문에 Open set 일반화 가능성이 제한적임을 보여준다.

RAM의 구조. RAM++와 달리 따로 Text 정보를 병합하지 않기에 Open-Set 추론 성능이 떨어지는 경향이 있다.
RAM++ 모델은 Text, Tag Description Supervision을 모두 활용하여 다양한 벤치마크에서 SOTA 제로샷 성능을 달성하였다고 한다.
특히 RAM++는 OpenImages의 일반 카테고리에서 CLIP을 10.0 mAP, ImageNet에서는 15.4mAP 차이로 앞질렀다. 또한 RAM에 비해 Tag-Uncommon Phrase-HOI에서 현저하게 우수한 성능을 보여 접근 방법의 중요성을 알 수 있다.
또한 RAM의 빠른 수렴 장점도 가져왔다.
그리고 RAM++가 Uncommon ImageNet-Multi에서 다른 모델에 비해 성능이 떨여젔는데, 이는 RAM++ 모델이 사용하는 1400만 규모의 데이터 셋이 드문 카테고리를 포괄하기에는 부족하다고 판단했다고 한다. 이 근거는 데이터 셋의 규모를 400만에서 1400만으로 확장했을 때 3.7 mAP 성능이 올라간 것을 통해 얻었다고 한다.
- Distribution of Probability Scores :
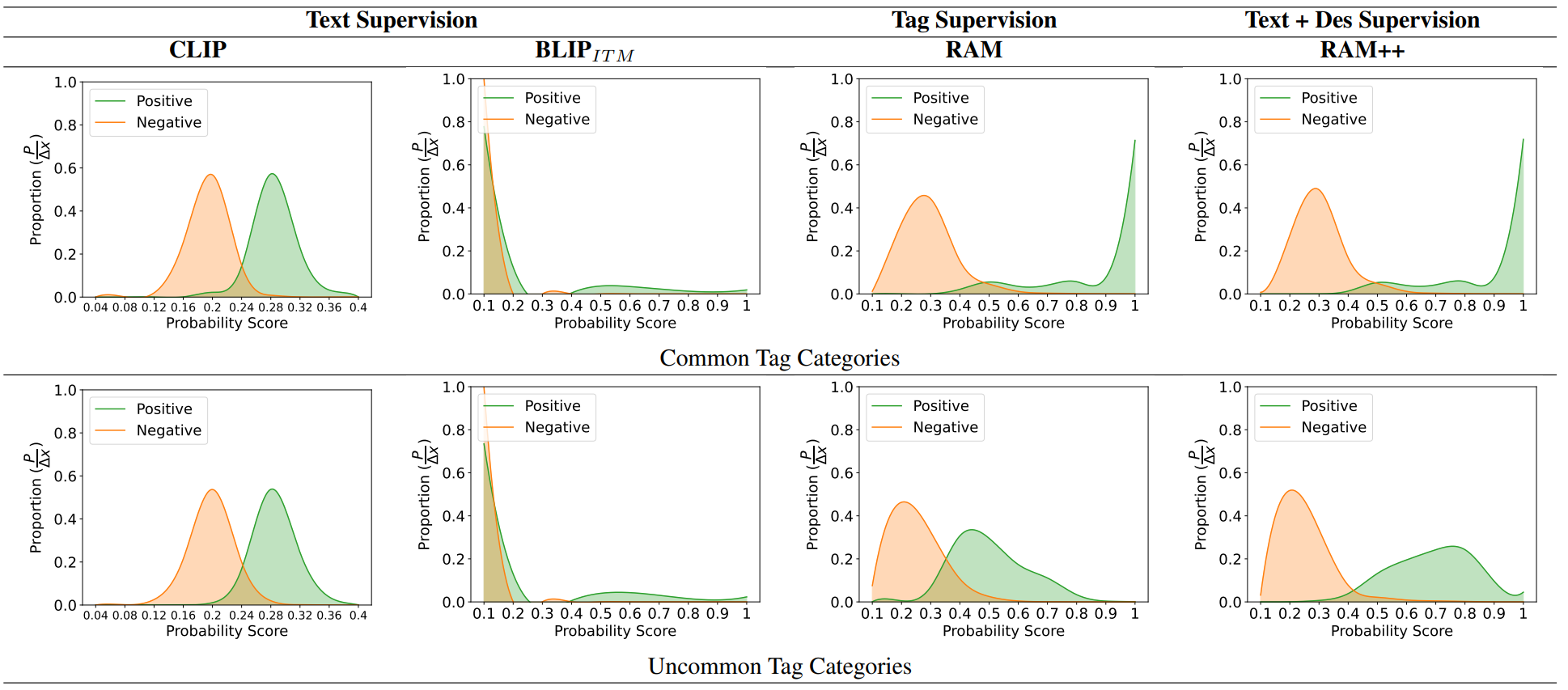
다음의 그림은 OpenImages 벤치마크에서 다양한 모델들에 걸쳐 Positive Tag와 Negative Tag의 확률 점수 분포를 분석한 것이다. 효과적인 모델은 긍정적 태그와 부정적 태그를 명확히 구분하여야 하며, 특히 텍스트와 태그 설명 multi-supervision RAM++는 견고한 성능을 보인다. CLIP과 BLIP과 같은 Text Supervision 모델들은 Positive Tag에 높은 확률 점수를 부여하는데 어려움을 겪어 다중 태그 인식에 있어 최적이 아닌 성능을 보여준다. 반면 RAM은 Open Set 카테고리를 인식하는 데 있어 어려움을 보여준다.

위의 그림에서는 RAM과 RAM++ 간의 예측 확률 비교에 대한 정량적 결과를 제공한다.
그림에 묘사된 설명은 Automatic re-weight에서 높은 weight을 가진 것들을 나타낸다. RAM++는 Open-Set 카테고리에서 예측 확률의 강력함을 나타낸다. (영어 설명은 RAM++ Automatic Re-weight module에 의해 가장 높은 가중치가 부여된 것들이다.) reweight module은 모델 훈련 과정에서 특정 데이터 포인트나 특성의 중요도를 조정하여, 그 중요도에 따라 모델의 학습에 더 큰 영향을 미치게 한다.
4.3. Analysis of Multi-Grained Supervision

- Evaluation on Multi-Grained Text Supervision : 위의 표에서는 Multi-Grained Supervision의 영향을 평가하기 위한 ablation 연구를 수행한다. Tag Supervision은 Common set 추론에 성능 향상을 시키는 것으로 볼 수 있고, Text, Tag Supervision을 섞어 활용함으로써 선으이 향상될 여지가 있음을 보여준다.
RAM++ 모델은 Tag SuperVision RAM 모델(기존)과 달리 추론 프롬프트로 LLM TAG DES.를 통해 성능의 급격한 저하를 피하며, Open Set 추론 성능 또한 올릴 수 있다.
사례 e는 특히 훈련 단계에서 LLM Tag Des를 통합하는 것의 효과성을 강조하며, (f)는 다중 태그 설명의 Automatic Weighting 이 모델의 능력을 더 향상시킨다는 것도 확인할 수 있다.

- Inference Time Comparison : 위의 그림은 태그 카테고리 수가 증가함에 따라 3 가지 정렬 패러다임 간의추론 시간 소모를 비교한 것이다. A100 GPU에서 1000회의 반복을 통해 계산된 평균 추론 시간을 사용한 것이라고 하며, ITM 모델은 단일 이미지-텍스트 쌍과 정렬되므로 추론 시간이 기하급수적으로 증가한다. ITC와 ITTA 모델은 태그 카테고리가 대폭 증가해도 높은 효율성을 유지한다.
5. Conclusion
RAM++는 Global, Spatial/Token Feuature들의 결합을 통해 Multi Grained Text Supervision을 활용함으로써 다양한 오픈 세트 카테고리에서 뛰어난 성능을 달성했다.