정의
* 자료구조
- 데이터를 원하는 규칙 또는 목적에 맞게 저장하기 위한 구조,
* 알고리즘
- 자료구조에 쌓인 데이터를 활용해 어떠한 문제를 해결하기 위한 여러 동작들의 모임.
자료 구조의 종류
- 자료구조는 매우 다양하나, 큰 갈래로 보면 다음과 같은 종류가 있다.
1. 스택 : First-In Last-Out 구조. 물건을 쌓아놓고, 해당 물건을 다시 빼내는 과정을 생각하면 된다. 이 경우, 데이터는 먼저
들어온 것이 나중에 빠지게 된다.

2. 큐 : First-In First-Out 구조. 대기열을 생각하면 된다. 먼저 들어온 것이 먼저 빠져나간다.

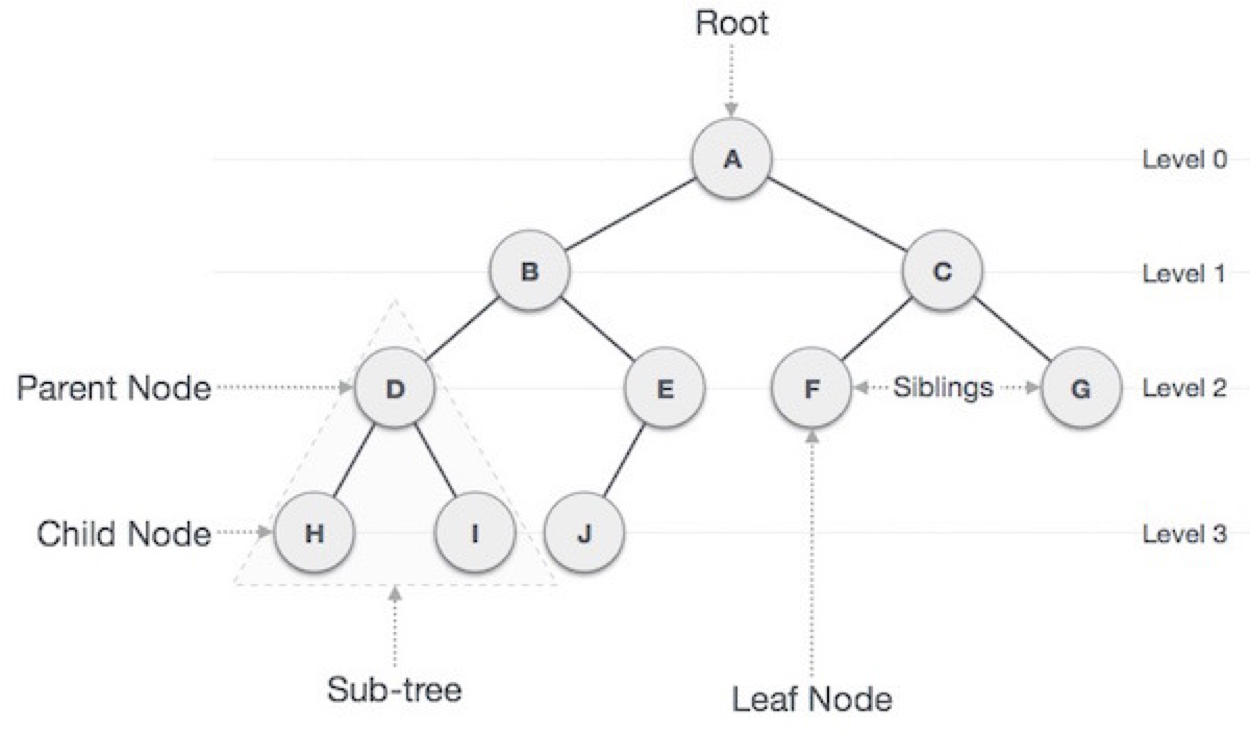
3. 트리 : 정점(Vertex)와 간선(Edge)를 이용해 사이클을 이루지 않도록 구성한 Graph의 특수한 형태.(Acyclic Graph)
기본적으로 루트 노드가 존재하고 이에 연결된 자식 노드들이 아래로 내려가며 구성되므로 방향성이 존재한다.
노드가 N개일 때, N-1개의 edge가 존재하게 된다.
* 계층이 있는 데이터를 표현하기에 적합하다. (Graph는 사이클이 존재 가능하다.)
4. 배열 : 초기화 시 미리 사용할 메모리를 선언해서 그 공간만큼을 할당해두는 자료구조. 사전에 할당하기에 초기화시 크기 지정이 필수이며, 사이즈는 변경 불가하다.
5. 리스트 : 순서가 있는 데이터들의 집합. 배열과 다르게 빈 공간은 허용하지 않는다. 그냥 각 element를 이어놓고 순차적으로 탐색하는 특성 때문에, 같은 리스트에 여러 object type들이 존재 가능하다.
(각 element의 메모리 용량을 미리 알 필요가 없음)
6. 벡터 : 동적인 배열(ArrayList와 비슷), 그러나 동기화된 메소드로 구성되어 멀티 스레드 환경에서 안전하게 객체 삽입/삭제가 가능하다. 즉 동시에 여러 스레드가 같은 메모리에 접근하고 수정할 때 손상되지 않는다.
(Thread-safe기 때문에 lock을 걸고 푸는데 시간이 걸린다. 나머지는 배열 단점 공유)
* 힙(트리의 한 갈래) : 최댓값 또는 최솟값을 찾아내는 연산을 쉽게 하기 위해 고안된 구조. 각 노드의 key-value가 자식의 key-value보다 작지 않거나(최대 힙), 크지 않은(최소힙) 완전 이진 트리이다.
(완전 이진 트리 : 자식이 무조건 2개, 마지막 레벨 노드는 가능한 왼쪽으로 몰기)
! 트리와 힙의 자료구조는 자료구조를 관리하는 쪽에서 신경써서 관리해야하는 부분이다. Array 혹은 LinkedList와 같은 구조로 관리 될 수 있다. 완전 이진 트리의 경우에는 항상 child node가 2개이다. 따라서 완전 이진 트리로 구성된 heap의 경우에는 parent node의 index i에서 2i+1을 하여 left child, 2i+2를 하여 right child로 이동할 수 있다.
=> 일반 이진 트리는 자식 노드가 한쪽이 비어있을 수도 있고, 다양한 예외가 있어 배열로 관리하며 index로 접근하기 쉽지 않다. 그러나 완전 이진 트리로 자료 구조를 구성해두면 index만으로 신속하게 접근이 가능한 배열의 자료구조를 취할 수 있다는 장점이 있다.

* 우선 순위 큐(큐의 한 갈래) :
우선 순위 큐는 단순히 FIFO를 유지하던 기존 큐와 달리 데이터들에게 "Priority"라는 개념을 추가로 도입시켰다.
pop(큐에서 데이터를 꺼냄)을 할 시 먼저 들어온 것이 아닌, Priority가 높은 데이터를 꺼낸다. 보통 이를 구현하기 위해 힙을 사용하고, 힙은 완전 이진 트리를 통해서 구현되기 때문에 시간 복잡도는 O(logn)이다.
(시간 복잡도 관련은 알고리즘에서 정확히 확인할 것이다.)
* 해시 테이블과 해시 테이블의 시간 복잡도:
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조다. 빠른 데이터 검색이 필요할 때 유용하며, 해시 테이블은 Key 값에 해시함수를 적용해 고유한 index를 생성하여 해당 index에 저장된 값을 꺼내오는 구조이다.
해시 테이블은 고유한 index로 바로 buckets에서 값을 찾아오기 때문에 검색 시간이 없다. {O(1)}
그러나 해시의 index 값이 충돌한 경우 충돌된 index에 연결된 값들 중 원하는 값들을 찾아와야하기 때문에 최악의 경우 O(N)의 시간 복잡도를 지닌다.(N개의 데이터가 전부 동일 hash 값 가질 시)

* ArrayList vs LinkedList
1. ArrayList : 배열의 형태로 관리되는 리스트 (사실상 빈 공간이 없는 동적인 배열이라고 생각하자.)
- 원하는 데이터에 바로 접근이 가능하다. (배열의 특성)
- 만약에 ArrayList의 크기를 재조정해야할 시, 새로운 공간을 확보하고 그쪽으로 다시 일일히 옮기는 과정이 필요하다. 또한 데이터의 추가, 삭제가 발생 시 기존 데이터들의 인덱스를 하나하나 수정해줘야하므로 손해다. (배열의 단점)
(사용할 메모리를 미리 비워두어야하기 때문. 이 역시 배열의 특성이다. 자세한건 시스템 프로그래밍에서 더 자세히 기술)
=> 따라서 크기도 별로 변하지 않을 것이고, 데이터의 추가나 삭제가 드문 자료에 대해 적합한 구조이다.
2. Linked List : 한 데이터 블록에 Data, next pointer가 존재하여 직선형으로 연결된 체인과 같은 구조.

- 리스트의 크기에 제한이 없다. (물론 컴퓨터 물리적 메모리에 제한은 당연히 있다.)
- 삭제하려면 그냥 전 노드의 next를 삭제하려는 node의 next node에 연결해주면 되고, 추가 역시 비슷하게 next pointer만 2개 수정해주면 되므로 ArrayList에 비해 빠르다.
- index를 통한 직접 접근이 불가능하다. 따라서 항상 순차접근을 하여야한다.
=> 따라서 크기가 매우 가변적이며 삭제 추가가 빈번한 자료에 대해 적합한 구조이다.
* 큐와 스택의 구현
1. Queue : Array로 Queue를 구현하면 삭제 연산 이후 대기하는 데이터들을 한 칸씩 앞으로 당겨야한다. (Array가 불리하다.)
2. Stack : Array로 구현해도 항상 헤드만이 추가, 삭제되므로 삭제 추가 절차가 쉽다.
* AVL 트리 :
AVL 트리란 한 쪽으로 값이 치우치는 이진 탐색 트리의 단점을 보완하기 위해 만들어진 트리다. AVL은 항상 좌/우로 데이터를 균형 잡힌 상태로 유지하기 위해 추가적인 연산으로 트리를 평준화한다.
(AVL 트리는 왼쪽, 오른쪽 자식 노드의 트리 높이 차이가 최대 1이 되도록 한다. 이를 통해 O(log n)의 시간 복잡도를 유지한다. 반면, 이진 탐색 트리는 한쪽 서브 트리로 데이터들이 전부 몰릴 시 사실상 LinkedLIst가 되어버린다.)
=> AVL 트리는 트리의 균형을 유지하기 위해 LL,RR,LR,RL 회전을 적용하여 높이 균형을 재조정한다.
- LL case(Right Rotation) : 노드의 왼쪽 자식이 왼쪽 서브 트리에 삽입시, 왼쪽의 불균형이 일어난다.
이 때, left 자식 노드를 head로 만드는 Left 회전을 통해 균형을 맞춘다.

- LR case(Left-Right rotation) : 왼쪽 자식 트리의 오른쪽이 삽입될 시, 문제가 된 노드의 헤드를 Left, Right 순으로 돌린다.
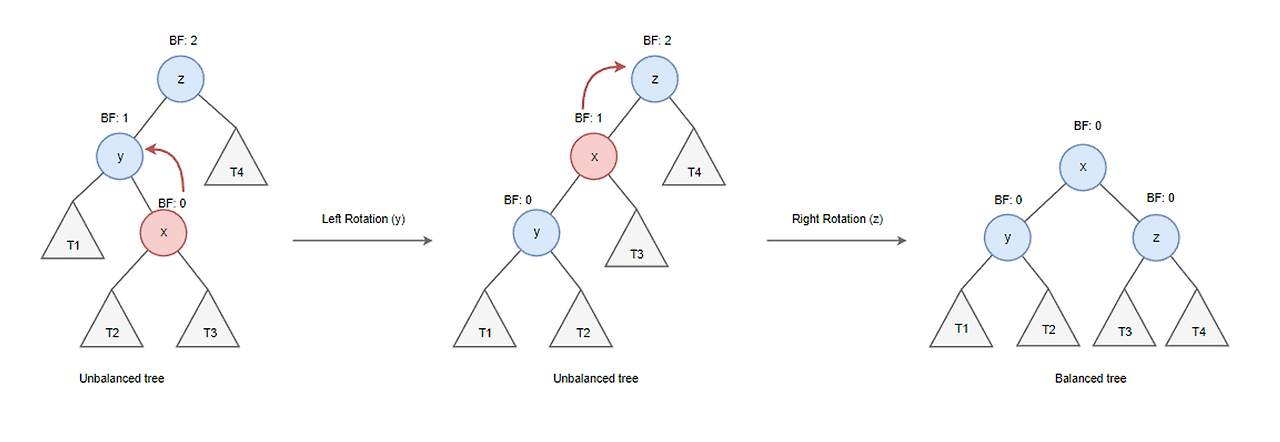
- RR case(Left Rotation) : 오른쪽 자식 트리의 오른쪽이 삽입 시, Right 자식 노드를 right 회전한다.
- RL case(Right-Left Rotation) : 오른쪽 자식 트리의 왼쪽이 삽입 시, 해당 삽입 노드의 헤드를 (Right-Left Rotation)을 통해 균형을 맞춘다.
결국 L'R', R'L'은 돌려서 L'L', R'R' case로 만들고, 처리해주는 아이디어다.
* 레드블랙 트리 :
컴파일러 개론에서 배운 개념과 비슷했다. Graph Coloring이라고 배웠던거 같은데, 컴파일러 개론에서는 추가로 활용 가능한 레지스터의 갯수를 색상의 갯수로 지정해서 노드들을 칠하는 방식으로 설명했다. 이 이웃 노드들의 색이 일치하지 않게 구성함으로써 레지스터 할당 문제를 해결하는 문제였다.
레드블랙 트리는 모든 노드를 빨간 색 혹은 검은색으로 칠하고, 연결된 노드들은 색이 중복되지 않게 관리한다. 여기서 각 노드가 Red 또는 Black의 색을 가지고 있으며, 이 색 정보를 겹치지 않게 구성하여 트리의 균형을 유지하는 자료구조이다.
1. 루트 색상을 블랙으로 지정
2. 레드 노드의 자식은 전부 블랙. (즉, 레드 노드는 연속해서 나타날 수 없다.)
3. 모든 경로에 대한 블랙 노드의 갯수가 일치해야한다. (균형 보장)
4. 모든 리프 노드는 블랙이다.
=> 이 과정을 통하면 블랙 노드의 갯수를 새는 것으로 트리의 깊이를 추정할 수 있고, 필요애 따라 트리를 회전하고 노드의 색을 변경해가며 균형을 재조정한다.
'CS 기본 지식' 카테고리의 다른 글
| 4. CS 기본 지식 - 네트워크 (0) | 2024.04.08 |
|---|---|
| 3. CS 기본 지식 - 알고리즘 (0) | 2024.04.04 |
| 2. CS 기본 지식 - 프로그래밍 (0) | 2024.04.03 |