* 정렬
- Bubble Sort
0번째 인덱스를 골라서 정렬이 안된 마지막 인덱스까지 탐색하며 규칙에 맞게 적절한 위치를 찾아주는 정렬법.
시간 복잡도는 O(n^2)이다.
//ascending
int a[n];
int selec_num;
for(int i=0; i<n-1; i++){
for(int j=0; j<n-i-1; j++){
if(a[j]>a[j+1]){
selec_num = arr[j];
arr[j]=arr[j+1];
arr[j+1]=selec_num;
}
}
}
- Heap Sort
주어진 데이터들을 힙 자료구조로 만든다. 그러면 Max든 Min이든 새로 삽입된 노드를 규칙에 해당하는 위치까지 이동시키면 된다. 시간복잡도는 O(nlogn)이다. 주어진 배열을 힙으로 구성하는데 O(n)의 시간이 걸리고 힙에서 루트를 제거하고 다시 힙을 구성하는데 O(logn)의 시간, 전부 정렬하는데 O(nlogn)의 시간이 걸린다.
(어짜피 Max Heap을 구성했다면 Root가 최대값, Min Heap을 구성했다면 Root가 최소 값이다.)
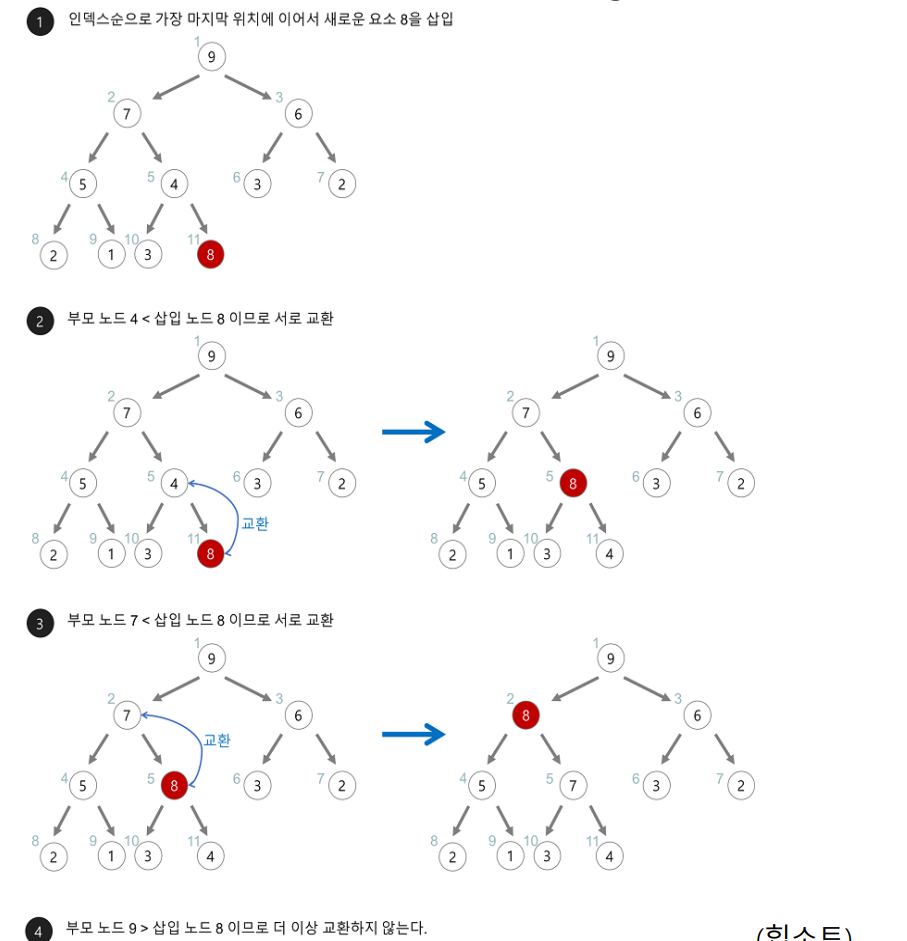
이러한 힙의 구조에서 root를 뽑아내고 다시 힙으로 만들고를 반복하면 정렬된 순서의 데이터를 얻을 수 있다.
단, Stable 정렬은 아니다.
- Merge Sort
배열을 크기가 1인 배열로 계속 분할하고, 합병하면서 정렬을 진행하는 Divide/Conquer 알고리즘이다. 시간 복잡도는 O(nlogn)이다.(분할하는데 logN, 합치면서 대소 비교하는데 N)
병합은 양쪽 배열에 p1, p2 포인터 하나씩을 두고 p1 p2 위치의 값을 비교해서 큰 것 혹은 작은 것을 넣어주고 삽입시킨 포인터를 하나 증가시키는 방법으로 진행된다.
하나의 문제를 동일한 유형의 작은 문제로 분할한 후, 작은 문제에 대해 결과를 조합하여 큰 문제를 해결하는 것을 Divide Conquer라고 부른다.
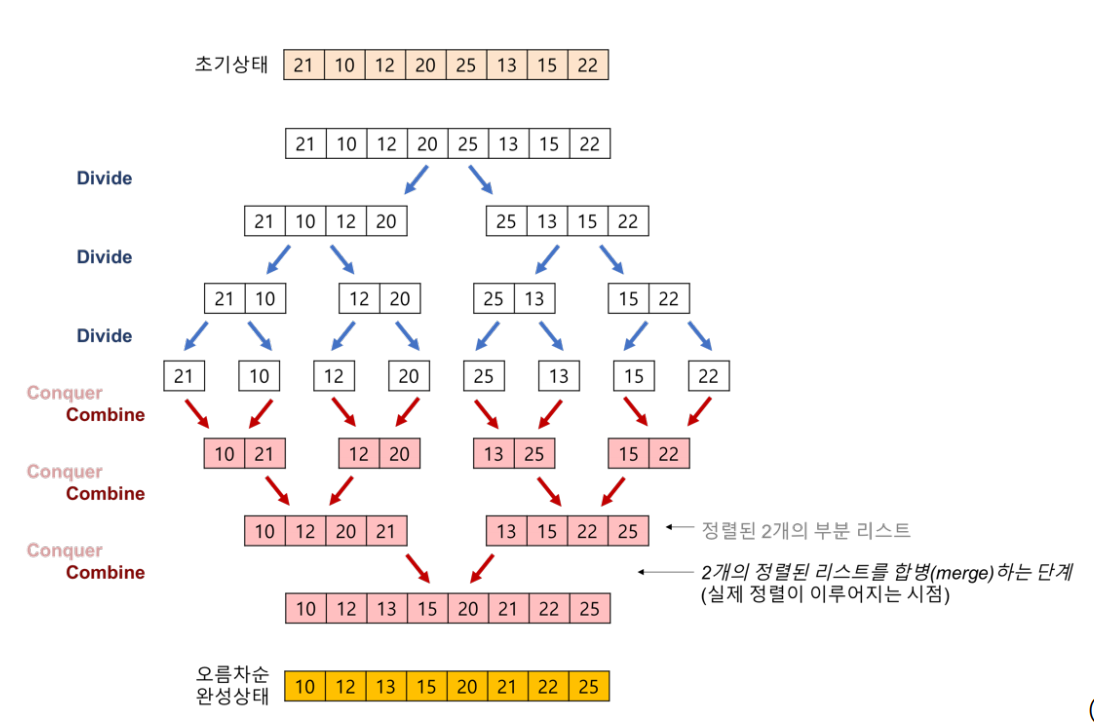
- Quick Sort
Divide & Conquer 중 하나로 리스트를 비균등하게 분할한다. 피봇을 선택하고(선택법엔 여러가지가 있다.) Left, Right 포인터를 설정한다.
그 뒤, Left pointer가 기준을 불만족 시키는 데이터를 찾을 때까지 증가시키고, Right pointer도 기준을 불만족 시키는 데이터를 찾을 때까지 감소시킨다.
양 쪽 포인터가 정지하면, 2개의 포인터의 값을 바꾸어준다. 이렇게 해서 Left 포인터가 Right 포인터를 마주치면, Left 포인터의 위치에 pivot을 넣어주고 pivot 기준 왼쪽, 오른쪽 리스트를 분할하여 각자 다시 Quick Sort를 한다.
시간 복잡도는 left, right 스캔을 하며 위치를 바꾸어주는 O(n) 리스트를 분할하는 횟수 O(logn)을 하여 총 O(nlogn)이 된다. 만약 리스트가 이미 정렬되어있으면 리스트는 계속 불균등하게 분할될 것이고, O(n^2)까지 나빠진다.
(분할이 불가능해질 때 까지.)
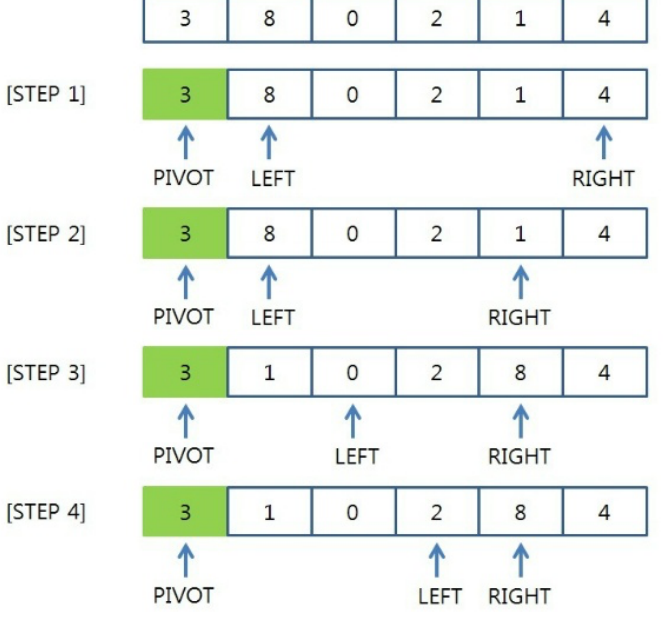
- Insertion Sort
삽입정렬은 2 번째 값부터 시작해서 그 앞에 존재하는 원소들과 비교하여 삽입할 위치를 찾아 삽입하는 알고리즘이다.
시간 복잡도는 O(n^2)이며, 이미 정렬되어있는 데이터에 시행하면 한번도 검색이 이루어지지 않고 Key를 잡고 전 포인트랑 확인만 하고 끝나기 때문에 O(n)까지 증가한다.

- Selection Sort
현재 Key pointer의 값을 min 혹은 max 값으로 잡고 리스트를 스캔하여 min, max 값을 검색하고 제일 첫 자리에 가져다 두고, 다시 반복하여 두번 째 자리...를 반복하는 것. 시간 복잡도는 O(n^2)이다.

- Shell sort
간격 k로 배열을 끊으면 부분 리스트들이 생긴다. 해당 부분 리스트 들을 간격이 1이 될 때까지 줄여가면서 각각 삽입 정렬
O(n*sqrt(n), 최악에는 O(n^2)이다.
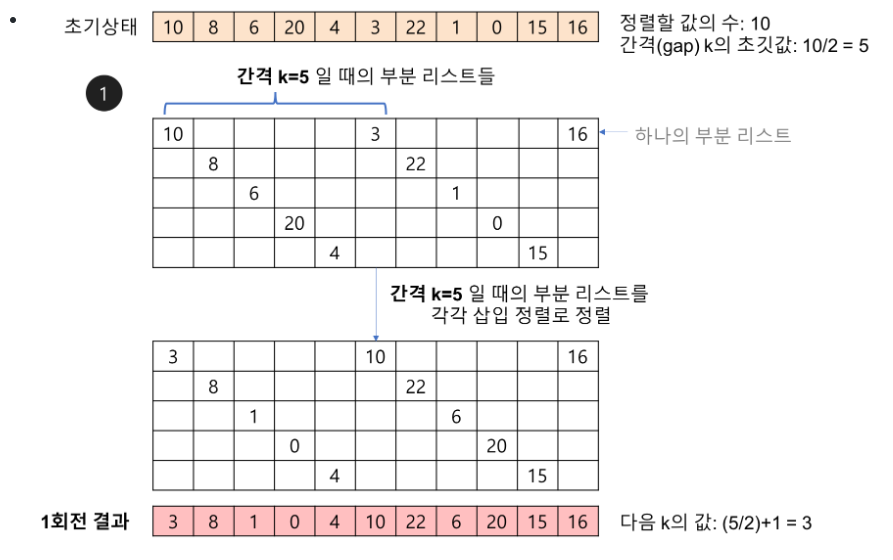
* 동적 프로그래밍(Dynamic Programming)이란?
- 주어진 문제를 풀기 위해서 문제를 여러개의 하위 문제로 나누어 푼 다음, 그것을 결합하여 해결하는 방식.
=> Divide Conquer는 큰 문제를 작은 하위 문제로 바꾸고 하위 문제를 해결한 뒤 이들을 결합하는 과정은 똑같다. 하지만 이 분할된 하위 문제들은 서로 "독립적"이며 하나의 하위 문제 해결이 다른 하위문제 해결에 도움이 되지 않는다.
그러나 Dynamic Programming에서는 각 하위 문제의 해결책을 저장하여 다른 하위 문제 해결에 도움을 준다.(재 계산 방지) 예를 들면 팩토리얼 계산법에서 5!를 계산할 때 4!까지의 수에서 5를 곱하는 방법이 있다.
=> 따라서 재귀 알고리즘 등에서 사용한다.
* 팩토리얼 재귀 알고리즘의 시간 복잡도
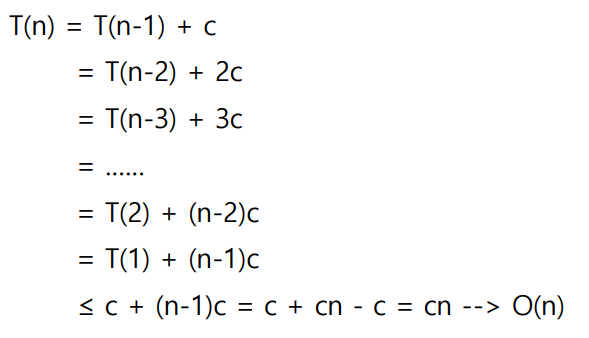
* n개의 배열에서 k(k<=n) 번째로 큰수를 찾는 알고리즘
퀵정렬을 사용하되, 우리는 k번째 까지의 값만 관심이 있다. 나머지 부분은 정렬해주는 것이 시간 낭비인 것이다.
이럴 경우 정렬의 scope를 줄여서, 퀵정렬을 한 후 pivot이 k라면 return. k<pivot이라면 왼쪽, k>pivot이라면 오른쪽만 퀵정렬을 돌리면 되는것이다.
이 경우 n+n/2+n/4+...+1 = O(n)이 된다.
* Huffman Coding이란?
문자의 빈도를 이용해 압축하는 방법으로, 빈도가 높은 문자에 짧은 코드를 부여한다.
이를 통해 데이터를 효율적으로 압축할 수 있다.

(자세한 과정은 너무 길어지므로 다음을 참고하면 좋다. https://lipcoder.tistory.com/187)
'CS 기본 지식' 카테고리의 다른 글
| 4. CS 기본 지식 - 네트워크 (0) | 2024.04.08 |
|---|---|
| 2. CS 기본 지식 - 프로그래밍 (0) | 2024.04.03 |
| 1. CS 기본 지식 - 자료구조 (0) | 2024.04.02 |