1. What is a distributed system?
분산 시스템이란 종단 user들에게 하나의 coherent system으로 보이는 Autunomous computing element들의 collection을 의미한다.
Autonomous computing element(node)란 물리적으로 독립된 하드웨어나 프로세스를 의미한다. 즉, 메모리 등 자원 공유가 안되는 상태이다.
Single coherent system 이란 하나의 시스템으로 인지되는 시스템을 의미하며, 이를 위해 노드들은 협력이 필요하다.
각 노드는 물리적으로 독립되어있으므로 각자의 시간을 가지고 작동하며 phsycal global clock이 없고, 동기화 및 조정 문제를 해결해야한다.
즉, Collection of nodes는 어떻게 group을 관리할 것인가? 어떻게 실제로 승인된 member와 통신하고 있는지 확인할까? 라는 문제를 내포하게 되는 것이다.
2. Collection of autonomous computing elements
Overlay network : 노드들이 서로 어떻게 연결되어있는가에 대한 정의이다. 명시적으로 구조가 알려져있을 수도 있으며 동적인 구조를 가질 수도 있다.
Overlay types : Peer-to-Peer systems, Tree, Ring 등. 전체 구조를 다 그릴 수 있고 각각의 노드가 어디와 연결되어있는지 표현이 가능하면 implicit하며 static한 구조이며 loockup table 관리가 가능하다.
Single coherent system이 되기 위해서는 "분산 투명성"(Transparency)를 지켜야한다.
* Distribution transparency
1. end user는 실제 연산이 어디서 이루어지는지 모른다.
2. end user는 데이터가 정확히 어디에 저장되는지, 어디서 로드 됐는지 모른다.
3. 데이터가 원본인지 사본인지 모른다.
=> 이러한 분산 투명성은 Partial Failure를 겪을 수 있다. Partial Failure는 end user가 분산된 node 간의 차이를 느끼게 되는 것이다. 예를 들면 아시아 서버가 터져서 북미에서 데이터를 가져오기 시작하여 데이터 송신이 느려진 경우이다.
3. Middleware and distributed systems

Middleware : distributed system의 OS이다. 애플리케이션에서 별도로 구현할 필요 없는 API와 같은 느낌의 components와 function 들을 의미한다.
=> 그렇다면 어떻게 Design goal을 정해야 제대로 된 Middleware를 만들어 분산 시스템을 서비스할까?
*Design Goals
1. 어떻게 리소스들을 독립된 노드들에 공유할까?
(여러 노드에 동일한 리소스가 동시 접근된다면?)
2. 분산 투명성을 어떻게 지킬까?
3. 개방성이 있는가?
4. Scalability가 있는가?
=>
- Resource Share Canonical examples
1. Cloud-based shared storage and files
2. P2P assisted multimedia streaming
3. Shared mail services (Outsourced mail systems)
4. Shared Web hosting (Content Distribution Networks)
- 분산 투명성의 Type
1. Access : 데이터 표현을 어떻게 하는지를 숨기고, 객체에 어떻게 접근하는지를 숨긴다.
2. Location : 객체가 어디에 있는지를 숨긴다.(사용자는 객체의 물리적 위치를 몰라도 엑세스 가능하다.)
3. Relocation : 객체가 사용 중에 다른 위치로 이동되는 것을 숨긴다.(객체가 이동하더라도 사용 중 영향이 있지 않다.)
4. Migration : 객체가 다른 위치로 이동한 것을 숨긴다.
5. Replication : 객체가 복제된 것이나 아니나 차이가 없어야한다.
6. Concurrency : 객체가 여러 독립된 사용자에 의해 동시에 접근됨을 숨긴다.(다수의 사용자가 동시에 객체를 사용해도 시스템에서 중재한다.)
7. Failure : 객체의 실패 및 복구를 숨긴다.
=> 종류는 다양하지만, Full distribution transparency를 구현하는 것은 어렵다.
(Communication latencies는 숨길 수가 없고, network와 node의 failure를 완벽히 숨기는 것은 일단 실패가 나고 나서 확인이 된 후 조치를 하기 때문에 불가능하다, Full transparency를 지속하여 관리, 유지하는 것은 시스템에 큰 부담이며 분산 구조를 노출시킬 수도 있다.)
따라서 분산 투명성은 좋은 목표이지만, 이를 완전히 달성하는 것만을 추구할 필요는 없다.
! 물론, 분산 구조가 노출되는 것이 항상 불리한 것은 아니다. 친구의 위치를 찾는 위치 기반 서비스나, 다른 시간대의 이용자와 상호작용 할 때 시간대의 노출, Partial Failure가 발생시 문제가 발생했다는 것을 공개하는 것이 있다.
4. Being open
* Openness of distributed systems : 나의 환경과 관계없이 다른 open system의 서비스와 상호작용이 가능해야한다.
이를 위해서는 다음이 지켜져야한다.
1. 시스템은 well-defined interface들을 가지고 있어야한다.
2. 시스템은 쉽게 상호 운용이 되어야한다.(시스템간 호환성이 뛰어나야한다.)
3. 애플리케이션의 portability 지원을 하여 특정 환경에 관계 없이 작동할 수 있어야한다.
4. 시스템은 쉽게 확장될 수 있어야한다.
* Polices vs Mechanisms
- Policies (무엇을 고려해야할지?)
1. level of consistency : 클라이언트에 캐시된 데이터의 일관성을 어떤 수준으로 관리할 것인지 결정해야한다.
2. 코드의 실행 권한 : 다운로드 된 코드가 수행할 수 있는 작업의 범위를 결정해아한다. (보안)
3. QoS 조정 : Bandwidth의 변화에 따라 QoS를 어떻게 조정할지를 결정해야한다.
4. 보안 수준 : 통신에 필요한 보안의 수준을 결정해야한다. (어떤 수준의 암호화를 채택할지?)
- Mechanisms (어떻게 실현할지?)
1. Caching policy dynamic setting : 캐싱 정책을 동적으로 설정할 수 있는 메커니즘을 제공한다. 예를 들어 hit ratio가 낮은 데이터는 짧게 캐시하도록 할 수 있다.
2. 모바일 코드에 대한 신뢰 수준 지원 : 신뢰할 수 있는 코드, 그렇지 않은 코드에 대해 다른 보안 정책을 적용한다.
3. QoS parameter 조정 : 데이터 스트림마다 QoS parameter를 조정할 수 있는 매커니즘을 제공한다.
4. 다양한 암호화 알고리즘 제공 : 통신 보안을 위해 여러 가지 암호화 알고리즘을 제공한다.
=> 정책과 매커니즘의 엄격한 분리가 이루어질 수록 더 많은 구성의 매개변수와 복잡한 관리를 필요로한다. 예를 들어 각 상황에 맞는 정책을 설정하고 이를 실행하는 메커니즘을 따로 설계하여야한다.
하드 코딩된 정책(fixed)은 관리가 간단하고 복잡성이 줄어드나 유연성이 떨어져 Openness를 저해할 수 있고, 정책에 따른 매커니즘이 dynamic하게 관리될 수록 Openness는 증가되나 복잡해진다. (Trade-off)
5. Being scalable
"확장 가능하다"에 대한 정의를 먼저해보자.
1. Size Scalability : 시스템이 더 많은 사용자나 프로세스를 처리할 수 있는가?
2. Geographical Scalability : 시스템의 노드 거리가 어디까지 멀어져도 지원하는가?
3. Administrative Scalability : 시스템이 얼마나 많은 도메인을 지원하는가?
=> 대부분의 시스템은 Size Scalability만 집중하고 이는 여러 강력한 서버를 병렬로 독립적으로 운영하며 해결한다.
그러나, 여전히 다른 2개의 확장성은 어려움을 겪고 있다.
* Centralized solution에서 발생하는 scalability의 근본적인 문제
1. Computational capacity : CPU에 의해 제한되는 계산 능력.
2. Storage capacity : 저장소 용량 및 CPU와 디스크 간의 전송 속도.
3. network between the user and the centralized service : 네트워크의 병목현상 등 bandwidth의 문제.
=> 이 때문에 강력한 서버, 강력한 네트워크를 요하는 것으로만 문제 해결이 집중된다.

* Centralized system Assumptions and notations
1. queue는 무한한 용량을 지닌다.(Req의 도착 속도는 현재 큐 길이나 어떤 것을 처리 중인지에 영향 받지 않는다.)
2. Arraval rate requests : λ
3. Processing capacity service : μ req/sec
=> k개의 request가 시스템에 존재하는 시간의 비율

=> 수식을 보면, λ 만큼 요청이 도착하고, μ만큼 요청이 처리되므로, λ/μ 는 초당 처리되는 Request의 비율이다.(서버의 이용률)
=> pk는 시스템에 k개의 요청이 있을 확률을 의미한다. (1- λ/μ)는 시스템이 idle일 확률이다. (λ/μ) 는 시스템에 k개의 요청이 있을 확률을 나타낸다.

* System의 평균 요청 수

* 평균 처리량(Expectation)

* Response Time

* Service Time

=> 즉, U(λ/μ)가 작으면, Response-to-service time은 커지고, U가 커지면 거의 무한대로 간다.(Service time을 줄이는 것으로 해결이 가능하다.)
* Geographical Scalability의 문제
1. LAN에서 WAN으로 단순 확장은 불가능하다.
=> 많은 분산 시스템은 Sync(동기식) client-server interaction을 가정한다. 즉, 클라이언트가 요청을 보내고 서버의 응답을 기다리는 구조인데, 이 과정에서 Latency가 필연적으로 발생한다. LAN은 Latency가 짧기 때문에 이런 효과를 무시할 수 있지만 WAN 단위로 가면 Latency가 훨씬 길어지므로 Client가 요청을 보내고 서버의 응답을 무한히 기다리는 방법은 적합하지 않다.
2. WAN 연결의 Reliability 문제
=> WAN Link는 LAN에 비해 신뢰성이 낮을 수 밖에 없다. (전송 오류, 네트워크 지연등이 자주 발생한다.). 따라서 비디오 스트리밍 서비스 등을 단순히 LAN에서 WAN으로 옮기면, WAN의 불안정성으로 인해 실패 가능성이 높아진다.
3. Multi Point Communication 부족
=> 여러 지점 간의 동시 통신이 부족하다는 문제이다. 예를 들어, 간단한 검색 브로드 캐스트를 여러 네트워크 지점에 보내려는 시도를 할 때, WAN 환경에서는 효과적으로 구현하기 어려울 수 있다. 이를 해결하려면 별도의 네이밍 및 디렉터리 서비스를 개발하여야하며 이를 여러 지리에서 통합시켜야하므로 문제가 된다.
(유튜브 라이브 스트리밍 서비스 등에서 한 사용자의 스트리밍에 전 세계의 사용자가 실시간으로 접속하여 시청한다. 이러한 문제를 해결하기 위해 등장한 것들이 CDN, Load balencing, Multicast Communication, Distributed naming service 등이다.)
*Administrative Scalability의 문제
1. Conflicting Policies : 비용, 관리, 보안에 대한 상충되는 정책들이 Administrative Scalability의 주요 문제이다. 예를 들어, 다른 조직이 같은 리소스를 사용할 때, 각 조직의 관리 및 보안 정책이 달라 충돌할 수 있다.
(Examples : 서로 다른 도메인 간에 비싼 리소스(클러스터, 슈퍼컴퓨터)를 공유하는 시스템은 각 도메인마다 서로 다른 관리와 보안 요구 사항을 지닐 수 있으며, 이로 인해 리소스의 공평한 사용과 관리가 복잡해진다.)
=> 그러나 예외도 있다. P2P system은 주로 end user 끼리 서로 협력하는 방식으로 돌아가므로, 시스템의 중앙 관리가 필요 없이 잘 돌아가며 확장될 수 있다. (Decentralized Network) - end user들은 이러한 시스템에서 협력적 주체로써 작동하므로 전통적인 관리 확장성 문제를 겪지 않는다.
* Techniques for scaling

1. Hide communication latencies
- Async communication을 만든다. 이를 통해 클라이언트는 서버의 응답을 기다리지 않고 다른 작업을 할 수 있다.
- 응답처리를 위한 별도의 핸들러를 사용한다. 이를 통해 응답 대기 시간 동안 다른 작업을 병렬로 수행 가능하다.
=> 이 방법도 문제가 있는데, 모든 애플리케이션이 이 모델에 맞는 것이 아니라는 점이다. 이메일 등은 이렇게 간편히 해결이 가능하겠으나, 동기적인 응답이 필요한 RealTime Application의 경우는 Async한 접근이 불가능하다.
2. 계산 자체를 Client로 이동한다. 사진의 두번째를 보면, Client에서 이메일 형식을 확인까지 해서 승인이 되었을 경우 서버에서는 Process만 하는 방식으로 계산 부담을 분산하였다. (Ex : DNS, Java Applets, WWW)
3. Replication and Caching. 데이터를 여러 머신에서 복제하여 사용 가능하게 하여 여러 machine에서 동시에 데이터를 사용 가능하게 한다. 동일한 데이터를 여러 서버에 복제하여 사용자가 어디서 접속하든 가장 가까운 서버에서 데이터를 제공하게 할 수 있고, 미러 사이트를 생성하여 가까운 미러 서버에 접속하게 할 수도 있다. 또한 웹 캐시, 파일 캐싱을 하여 매번 네트워크를 거치는 과정을 생략할 수 있다.
=> Replication의 문제 :
데이터를 여러 곳에 복제시켜두는 것은 확장성을 높이고 성능을 향상시킬 수 있지만, 그 과정에서 발생하는 일관성이 큰 문제가 된다.(한 복제본이 수정되면 다른 복제본의 업데이트 필요 -> Global Sync.작업의 발생. 그러나 이러한 Global Sync는 대규모 시스템에서는 비현실적인 일이며, 네트워크에 큰 부담이 가는 일이다.
만약, 일부 불일치를 허용할 수 있다면, 전역 동기화를 정해진 시간마다 하는 식으로 부담을 줄일 수 있다.
6. Pitfalls
* 분산 시스템을 만들 때 일어날 수 있는 실수들(잘못된 가정을 하지 않고 시스템을 구성해야함.)
1. 네트워크가 항상 작동할 것이다. (Reliable, 즉 항상 목적지까지 도달할 것이다.)
2. 네트워크는 항상 보안이 확보되어있다.
3. 네트워크가 항상 homogeneous하다. (즉, 같은 QoS와 Bandwidth를 지닌다는 가정이다. 실제는 Heterogeneous이다.)
4. 네트워크 항상 토폴로지가 고정되어있다.
5. Latency는 항상 0이다.
6. Bandwidth는 무한하다.
7. 연결이 끝나면 유지와 통신 비용은 0이다.
8. 네트워크에는 한 명의 관리자만 존재한다.
7. Types of distributed systems
* 분산 시스템의 타입
1. High Performance distributed Computing systems(HPC) : 분산을 통해 성능의 향상을 꾀한다.
2. Distributed Information System : 정보를 분산하여 저장, 제공하는 시스템.(WWW)
3. Distributed systems for pervasive computing : 유비 쿼터스 등 작고 나뉘어있는 단위의 네트워크를 위한 시스템. (Edge network)
1. HPC
* Parallel computing

=> 엄밀히 이야기하면 병렬 컴퓨팅은 분산시스템이 아니다. 여러개의 프로세서가 Interconnection을 통해 메모리를 공유하기 때문이다. 즉 Physical global clock이 존재하는 단일 노드로 보는 것이 맞다.
=> 병렬 컴퓨팅은 Data rate이 매우 높고(Tbps), 하나의 노드로 행동하기 때문에 Reliability가 높다.
* Distributed Computing

=> 각 노드들이 분리된 Private memory를 사용하며 이 노드들이 Interconnect 되어있다. 즉, Logical global clock을 사용하며 Datarate가 낮다.(Gbps) 또한 노드간 통신을 통해 작동하므로 Reliability가 낮다. 그러나 단순히 한 노드를 연결하면 되므로 Scalability가 매우 높다.
(여기서 저 노드들 하나하나가 병렬컴퓨팅 되어있을 수 있다.)
* Cluster computing(분산 컴퓨팅의 한 종류)

=> 기본적으로 LAN을 연결된 하이엔드 시스템 그룹. 이용해 LAN 안의 여러개를 연결하여 하나를 Master(managing node)로 둔 뒤 관리하는 방식. LAN안에 있으므로 각각의 node는 homogeneous하다고 가정한다.(동일한 OS, 동일한 하드웨어)
* Grid computing(분산 컴퓨팅의 한 종류)
=> Cluster computing의 발전형으로, 모든 곳의 무작위 다수 노드들의 연결을 가정한다. 즉, Heterogeneous를 가정한다. 따라서 여러 조직을 포함 가능하며 WAN으로 쉽게 확장할 수 있다.(Scalability 높음)
=> Heterogeneous한 환경에서도 작동해야하기 때문에 여러 인터페이스를 가진다.

- Fabric Layer : grid computing architecture에서 가장 하위 layer. local resource에 접근 가능하게 해주는 인터페이스를 제공한다.
- Connectivity Layer : 통신, 트랜잭션 프로토콜을 제공한다. 보안 프로토콜도 이 layer에 속한다.(ex : 데이터 이동 등)
- Resource Layer : 개별 리소스를 관리한다. 프로세스를 만들거나 데이터를 읽는 등이 이에 속한다.
- Collective Layer : 여러 개의 Resourcve에 대한 관리, discovery, scheduling을 담당한다.
- Applications : 하나의 organization으로 보이기 위한 grid application을 제공한다.
* Cloud computing(분산 컴퓨팅의 한 종류)

=> Infrastructure를 제공하냐, Platform을 제공하냐, Software를 제공하냐에 따라 애매하긴 하지만 분류된다.
그냥 하드웨어 자원만 분산으로 제공하면 Infrastructure, 그러한 자원을 이용하기 위한 Platform까지 같이 제공하면 Platform, 아예 Application까지 같이 제공하면 Software라고 보면 된다.
- Hardware Layer : Processor, router 등을 제공한다. 보통 Customer는 Hardware layer까지 올 일이 없다.
- Infrastructure : 가상화 기술이 들어가서 통일된 가상 환경에서 storage 등을 제공한다.
- Platform : Infrastructure보다 높은 level의 API 등을 제공한다.
- Application : 실제 사용할 수있는 환경까지 만들어준다.
2. Distributed Information Systems
=> 데이터나 정보를 여러군데 나눠서 저장하고 그에 대한 정보를 제공하는 시스템이다. network application을 제공하며 여러 시스템에 쉽게 통합되는 상호 운용성을 지는 것은 쉽지 않다.
단순히 생각하면, 그냥 client들이 서로 다른 application의 server에 대한 요청을 모아서 전달하는 것도 가능하지만, 이는 비효율적이다. -> Enterprise Application Integration(EAI)를 통해 Application간 직접적인 연결이 가능하게 하면 어떨까?
3. Pervasive Systems
=> Pervasive System은 HPC와 다르게 하나의 강력한 시스템을 구축하는 것이 아니라 가벼운 노드들의 개별 운용을 통해 이점을 살리려는 시도이다. 최근 모바일 노드들의 성능이 강력해짐에 따라 각광받고 있다.(IoT, 더 큰 시스템의 임베디드 등)
=> 노드들이 작고 이동성이 있으며 edge 서버에 뭔가 의존하는 환경을 생각할 수 있다.(edge 서버를 활용함으로써 허용 가능한 노드가 많아지며 end 유저에 맞닿아 있다는 이점이 있다.)
* Three overlapping Pervasive system subtypes
1. Ubiquitous computing system : 항상 사용자와 시스템이 연속적인 상호 작용이 가능하게 함.
2. Mobile computing systems : 이동 중에 사용이 가능하다. (Wireless : 이동을 했을 때 다른 노드에 쉽게 붙을 수 있다. - Handover)
Handover(또는 Handoff)는 모바일 네트워크에서 사용자가 이동할 때, 기지국(BTS) 또는 네트워크 셀 간에 연결을 전환하는 과정이다. 이 과정은 사용자가 끊김 없이 통화, 데이터 전송, 인터넷 접속 등을 계속할 수 있도록 해준다.
3. Sensor network : Sensing을 통한 데이터 수집에 초점을 맞춘 네트워크
1. Ubiquitous systems
- Distribution : 기기들이 분산되어있으며 네트워크가 연결되어 있고, 분산 투명성이 지켜진다고 가정.
- Interaction : 사용자와 디바이스의 Interaction이 unobtrusive하다. 즉, 상호작용을 하는데 있어 추가적인 과정이 필요없다.
- Context awareness : 시스템은 사용자의 context를 인지할 수 있다.
- Autonomy : 사람의 개입 없이 디바이스들이 self manage가 가능하다.
- Intelligence : 다양한 범위의 행동이나 상호작용을 수행 가능하다.
2. Mobile systems
- Mobile device들의 모임이다.
- Mobile은 토폴로지가 계속 변한다는 뜻을 내포하며, local service의 변화, reachability(coverage) 등의 고려가 필요하다.
즉, discover 용 프로토콜이 필요하고, handover가 중요하다.
- Communication에서 stable한 route를 가지지 못하고, connectivity 보장이 없으므로 어려움이 있다.
즉, disruption에 강건한 networking이 중요하다.
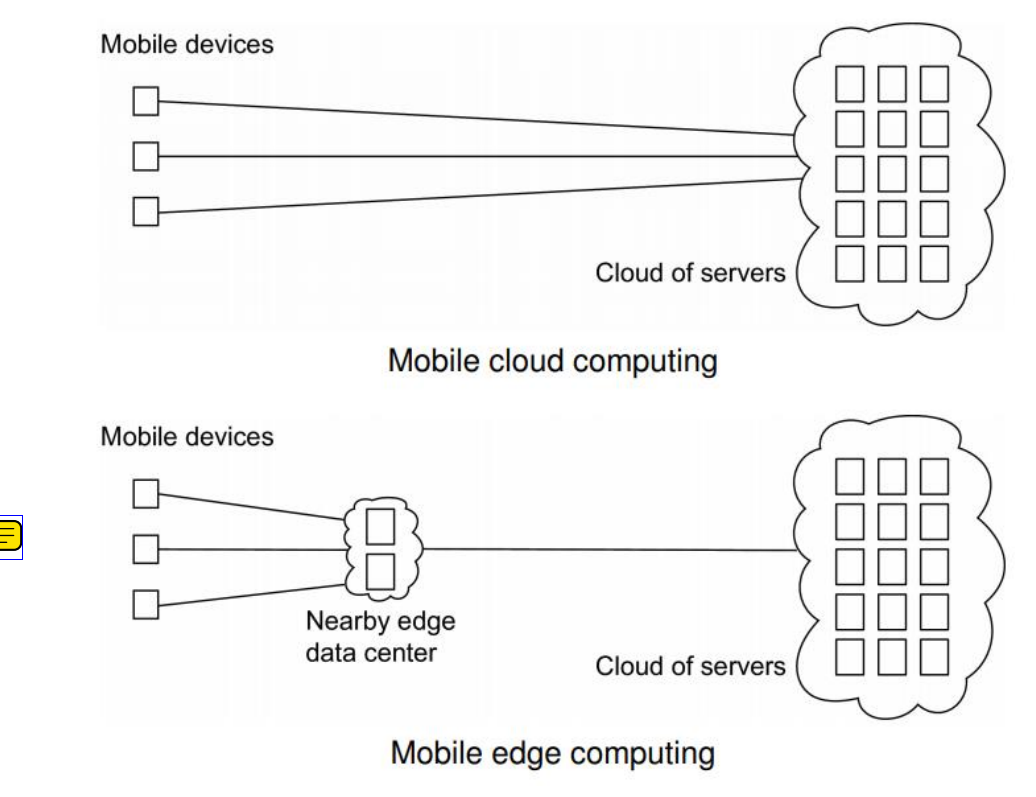
- 위의 사진을 보면, Mobile cloud computing과 Mobile edge computing의 예시가 그려져있다. Mobile computing은 Computing power가 떨어지는 상황도 고려해야한다. 따라서 HPC를 위한 설계가 되어있는 Cloud server에서 계산을 맡길 수도 있다.
- Mobile cloud computing은 바로 노드들이 Cloud에 접근하는 방식으로써, Communication Latency, Bottleneck이 발생 가능하다.
- 따라서 Mobile edge computing과 같이 중간 관리자인 mobile edge data center(MEC)를 구성하여 중간 관리자로 사용할 수 있다. 이를 통해 network burden의 감소, Server의 computation 부담 감소가 가능하다.
=> 그러면 어떤 작업을 MEC에서 처리하고 어떤 작업을 본 서버에서 처리해야할까?

- 다음과 같이 여러 단계의 작업 할당 방식이 있는데, 골자는 Latency 제약 조건이 적은 작업, 계산이 빡센 작업은 본 서버에서 처리, Latency 제약 조건이 큰 작업은 edge 서버에서 처리하는 방식으로 진행하는 것이다.
- Cloud server에 작업을 할당할 수록 data offloading의 비용이 올라가고, edge 쪽으로 내릴 수록 Autonomy가 증가하고 계산력이 감소한다.
- 딥러닝 등 AI Training/Inference 관점에서 보면, Training은 연산량이 많으나 Latency 제약조건이 적고, Inference는 연 산량은 적으나 Latency 제약조건이 크다. 즉 추론은 MEC에서, 학습은 Cloud Server에서 하는게 일반적이다. Level 3,4 를 기점으로 cloud training과 edge training이 나뉜다.
(클라우드에서 전부 처리 -> 클라우드와 엣지에서 같이 추론 -> 엣지에서 추론 -> 디바이스에서 추론 -> 클라우드와 디바이스에서 같이 학습 -> 모두 엣지에서 처리 -> 엣지와 디바이스에서 같이 학습 -> 모두 디바이스에서)

- 따라서, Cloud computing으로 갈 수록 데이터의 저장량, 저장 길이, 계산력, 신뢰성은 증가하나, Latency도 증가한다. 그러나 Device(end node) 쪽으로 갈수록 계산력은 감소하고 신뢰성도 감소하나 Mobility support, 상호작용, Latency의 감소, Context awareness 등이 증가한다. 단순하게 end 단에 가까워 질 때의 장 단점을 생각하면 된다.
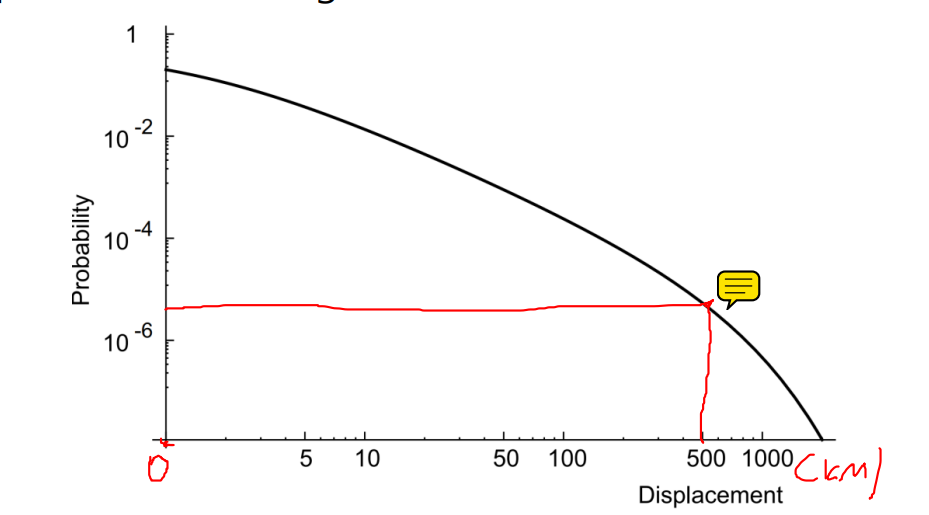
- 사실 그렇게까지 mobility에 강건한 network도 필요없다. 실험에 의하면 사람들은 24,48,72시간 내에 자신의 생활 반경으로 돌아오기 때문이다. 즉, 극단적으로 mobile한 경우는 적다.
3. Sensor network

- 센서 네트워크는 극단적으로 pervasive한 경우를 가정한다. end node는 10~1000개로 매우 많은 경우로 가정하며 각 end node는 sensor로써 작은 저장공간, 계산력 등을 가정한다.
- 사진을 Senrsor에서 수집된 데이터를 Opt에서 바로 받아서 처리하는 형태(Centralized), Sensor가 데이터를 저장하며 Opt가 Sensor network에 Query를 하면 이에 대한 Response만을 전송하는 형태가 존재한다.(Decentralized)
'개인 공부' 카테고리의 다른 글
| Distributed System - 3. Processes (0) | 2024.10.07 |
|---|---|
| Distributed System - 2. Architectures (0) | 2024.10.01 |
| CLIP : Connecting text and images. (기본 개념) (0) | 2024.06.25 |
| Q-Learning (0) | 2024.06.24 |
| 확률 및 통계 - 10. Generating functions (0) | 2024.05.24 |