1. Threads
- Processor : Instruction 집합을 자동적으로 순서대로 실행할 수 있는 것.
- Process : SW processor 면서 여러가지 Thread를 실행하는 context를 가진 프로그램 실행의 단위
- Thread : 가장 작은 단위의 SW processor. 실행될 수 있는 가장 작은 Instruction 단위. Thread를 저장한다는 것은 현재 실행을 멈추고 그에 관한 레지스터 data들을 다음 stage를 대비하여 저장하는 것을 의미한다.
* Context switching
- Processor Context : Instruction Series을 실행하기 위해 저장하고 있는 레지스터 값들의 collection. (Stack pointer, addressing registers)
- Thread Context : 가장 작은 단위의 Instruction을 실행하기 위해서 저장하고 있는 값. (Processor Context 포함)
- Process Context : Thread를 실행하기 위한 저장 값들의 모임. (Thread Context 포함)
=> 같은 process에 존재하는 thread들은 같은 address space를 공유한다.(Process에 할당된 메모리 내에서 Thread가 돌아감.) 따라서 Thread 간의 Context Switching은 추가적인 메모리 할당이 필요 없으며 OS의 도움이 필요 없다.
=> Process Switching은 OS 레벨에서 이루어지므로 더 무겁다. 따라서 Thread를 없애고 추가하는 것이 더 가벼운 작업이다.
(Process Context > Thread Context > Processor Context)
* Multi threading

- 하나의 process 내에서 여러개의 thread를 concurrent하게 실행하는 것.
- 같은 process 내의 Thread는 memory space와 resource를 공유한다. 그러나 각자의 stack, program counter는 공유하지 않는다.
- 격리된 CPU core들에 여러 Thread를 병렬로 실행하여 성능 향상이 가능하다.
! 장점
1. 성능 향상이 가능하다.
2. Thread switching은 OS의 개입이 없기 때문에 Blocking call이 없다. 즉, Responsiveness에서 이점이 있다.
=> Single Threaded process는 I/O 등이 발생할 때 block이 발생한다. 그러나 Multi Threaded process는 OS가 다른 thread로 Switch를 해주므로 효율적이다.
3. Thread는 Resource를 공유하여 사용하기 때문에 Resource utilization이 상승한다.
4. 프로그램 구조를 단순화 가능하다.
* Avoid Process Switching?
Process Switching은 OS 단위의 개입이 있어야하기 때문에 꽤나 Expensive한 작업이다.
User Space에서 Kernel Space로의 Switch -> Process Context Switch -> Kernel Space에서 User Space로의 Switch를 거치기 때문이다.
그러나, 항상 모든 프로그램이 Single Process Multi Threading을 할 수 있는 것은 아니다. (다른 리소스를 사용하는 등)
또한, Trade-off가 있는데, Multi Threading을 하면,
1. 같은 address space를 사용하므로 오류에 치명적이다.
2. OS/HW Level의 memory 사용 보호가 없다.
3. 그러나, Process context Switching 보다 빠르다.
2. Threads in Distributed Systems
- 일반적인 분산 시스템 Client-Server 구조에서는 Server에서 Processing, Client에서 UI/Application을 담당한다.
Multi Threading을 활용함으로써 Client 쪽에서는 다음과 같은 장점을 얻을 수 있다.
1. Multi threaded web client : network latencies의 은닉
=> Client(Web Browser)는 Server로부터 Response를 받고, Response를 처리, 출력을 하게 된다.
이 때, Single Thread로 구현이 되면, Response를 받는 것과 처리, 출력을 하는 단계를 구별해서 실행이 되게 된다.
따라서, 받으면서 동시에 처리를 하지 못해 전부 받고 후에 처리, 출력을 하게 된다.
2. Multiple Request-Response calls to other machines (RPC)
=> Client 측에서도 한번에 하나의 Request가 아닌 여러개의 서버에 Request를 보내고 여러 Response를 동시에 받는 작업이 가능하다. 또한 같은 Call을 여러 서버에 보내서 Failure에 강건하게 만들어줄 수도 있다.
- Server 측은 특히나 Multi Thread가 필수이다. Client에 비해 Blocking call을 하는 I/O demand가 높으며, 여러 Client를 처리해줘야하기 때문이다.
1. 성능 향상
=> Process Context Switching을 하는 것보다 여러 Thread 사이의 Switching이 편리하다. 또한 Server의 Computing Power demanding을 생각하면 Multi processor system에서 Multi Threading을 하는 것이 일반적이다. 또한 여러 Client를 동시에 처리가 가능하다.
2. Better Structure
=> 대부분의 server는 I/O demand가 아주 높다. 따라서 단순화된 blocking call을 위해서 Multi threading을 사용한다.
=> Multithreaded program들은 단순회된 control flow를 지닌다.
* Dispatcher/Worker model
=> Client로부터 Request가 network를 거쳐 Server에 도달한다.
이는 Server OS를 거쳐 도달하고, 이 때 Dispatcher Trehad라는 것을 두어 이 Request를 받는 Thread를 둔다.
그리고 Dispatcher Thread는 Worker Thread에게 Request를 제공한다. Wokrer Thread는 처리를 완료하고(Processing) Response를 보낸다.
=> 정리하자면 Multithreading은 병렬화가 가능하고 blocking system call을 유연하게 처리 가능하며, Single-threaded process는 병렬화가 불가능하며 blocking system call을 처리한다. Finite-state machine은 병렬화가 가능하나 blocking system call을 처리할 수 없다.
3. Networked User Interfaces
* Client-server interaction
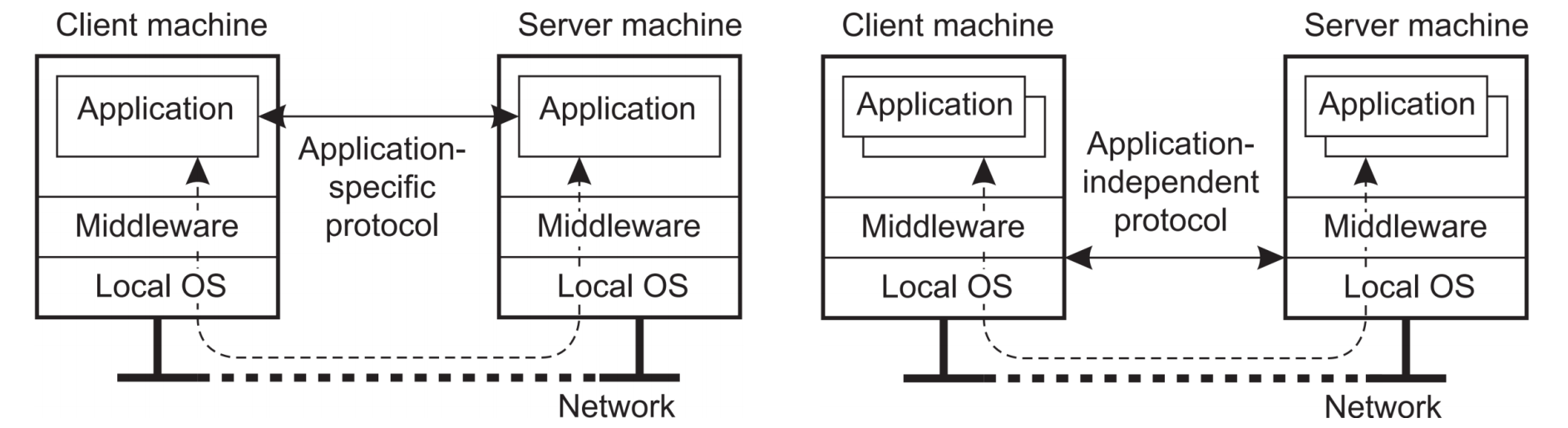
=> Application specific한 networking을 할거냐, middleware의 구조를 이용하는 networking을 할거냐로 나눌 수 있다.
왼쪽이 Application-level, 오른쪽이 middleware-level solution이다.
Application level은 각 Application에 초점을 맞춘 protocol에 의해 통신을 하는 것이고 Client Application이 어느정도 Processing을 부담할 수 있다.
middleware level은 Application과 무관한 protocol을 이용하여 (Common service) 서버의 Application에서 대부분의 Processing을 해서 Client에게 전달해준다. 이 방법은 서버의 부담이 있다.
* Client-side SW (Client 쪽에서 SW의 Distribution Transparency를 지키는 법)
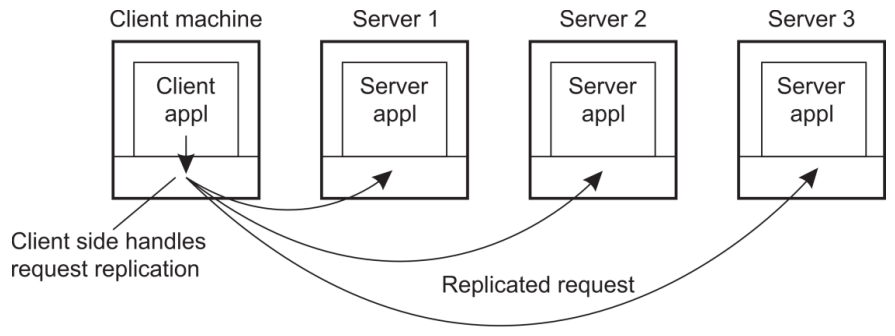
=> 주로 Distribution Transparency 해결을 위해 Middleware 단에서 처리를 한다. 즉, Client든 Server든 Application level에서 보면 Distribution Transparency가 지켜지고 있다는 것이다.(End-user라는게 꼭 최종 사용자만 의미하는게 아니다.)
=> Client-side SW에서 Access Transparency를 위해 RPC를 위한 stubs(Middleware 활용을 위한 OS)가 존재한다. 즉, Application level에서 middleware 단을 볼 때 Interface가 동일하게 보이게 함으로써 Access Transparency를 지킨다.
=> Location/Migration Transparency를 지키기 위해 Client-Side SW의 actual location을 계속 Tracking을 해준다.
=> Client의 Request가 복제됨을 숨기기 위해(Replication Transparency) Middleware 단에서 복제한다.
=> Failure Transparency : Client SW에서는 Failure를 숨기기 위해 Client-side Middle ware에서 처리를 한다. (반복 시도, 데이터 캐싱 등)
* Servers : general organization
=> Server는 Performance가 가장 중요하다. 이를 기준으로 Server의 구현법을 살펴보자.
1. Basic model
=> Server는 여러 Client로부터 Request를 받고 이를 처리하고 이후 다른 Request가 오는 것을 기다리는 것을 의미한다.
따라서 Multi Threaded가 필수이다.
2. Concurrent servers
- Iterative server는 다음 Request를 받기 전에 앞의 Request를 처리하는, 순차적인 Server
- Concurrent server는 Multi Thread를 활용하여 Dispatcher를 두고 Worker Thread로 전달하는 Server
=> Server는 Concurrent server가 표준이다. (I/O demand, High performance 충족)
* Contacting a server


- server에 contact에서 machine까지 전달되기 위해서는 IP 주소를 통해 networking을 한다. 그 후, process에 접근하기 위해 port 번호를 이용한다. Port는 fixed port, Dynamic Port가 있다.
- Dynamic port에는 2가지 방법이 있는데,
첫번째는 먼저 Daemon에 end point를 request하고, Server에서 end point가 등록이 되면, Daemon이 이를 알려준다. 그 후, Server에 통신을 시작하는 방법이다. 즉, 지속적으로 end point table로 port 번호를 관리하는 것이다. 그러나 결국 Server의 port 번호는 fix되어있어 어느정도의 낭비는 있다.
두번째는 Client가 Request Service를 날리면, Super server가 다른 Server에 port 번호를 부여해주고 Request를 전달해준다. 그럼 Specific Server와 Client가 통신한다. 이 방법을 사용하면 그냥 end point만 물어보는 추가 signaling도 없고, 각 server의 port도 fix되지 않는다.
* Out-of-band communication
=> In-band Communication이 일반적인 Client-Server Communication이라면, Out-of-band communication은 interrupt 개념으로 급한 message를 처리하는 방법이다.
=> 이러한 Out-of-band communication이 발생하면 서버를 어떻게 Interrupt 해줄 수 있을까?
1. Out-of-band 상황용 별도의 port를 열어둔다.(급한 일이 있을 때는 전화, 평소는 메일 등으로 처리하는 방법)
- Server는 Urgent용 독립 Thread/process를 운용할 능력이 있어야한다.
- Urgent message가 오면 먼저 처리해준다. (Priority-based scheduling 지원 필수)
2. TCP layer의 기능 활용(TCP header)
- TCP header에 Urgent Pointer를 Setting하여 전송을 하고, 이를 확인하게 server를 구현
* Servers and state (State는 Client의 State이다.)
1. Stateless Servers
=> Client의 state를 저장하지 않는 서버. 즉, 어떤 Request가 들어오면 Response를 하고 해당 데이터를 말소한다. Client SW를 Tracking 하지 않는 것이다. (open-write-close-open-write-close)
(Client의 cache 등이 없다. Client와 Server가 완전히 독립이다.)
=> 장점 : State의 일관성이 깨지는 문제가 발생하지 않는다.(Request에 대한 정보로만 판단한다.)
=> 단점 : Stateful Server에 비해 Request 처리의 Performance 향상을 하지 못한다.
2. Stateful Servers
=> Client와의 통신에서 어떤 파일을 열었었는지 등의 기록을 남긴다. (open-write-write-....-close)
=> Web browser Cookie를 생각하면 된다.
=> 장점 : Performance가 향상된다.
=> 단점 : State의 일관성이 깨지면 문제가 된다. 또한 지속적으로 Tracking을 함에 따른 Server의 부담 증가
* Cookie
-> Stateless Server에서도 Stateful처럼 사용가능하게 해주는 역할이다.
1. Server -> Client로 Status 전송
2. Client에서 저장
3. 다음 접속시 Client가 Cookie를 같이 보냄
4. Server에서 Client의 Status를 확인
=> Client가 어느정도 부담을 같이 지는 형태이다. 단, 여전히 Status Inconsistency 문제는 여전하다.
* Soft State
-> Stateful Server의 단점을 보완하기 위해, limit time을 걸고 그 이상 Client가 Request가 없을 시 Status(Cache)를 날리는 방법이다.
4. Server clusters
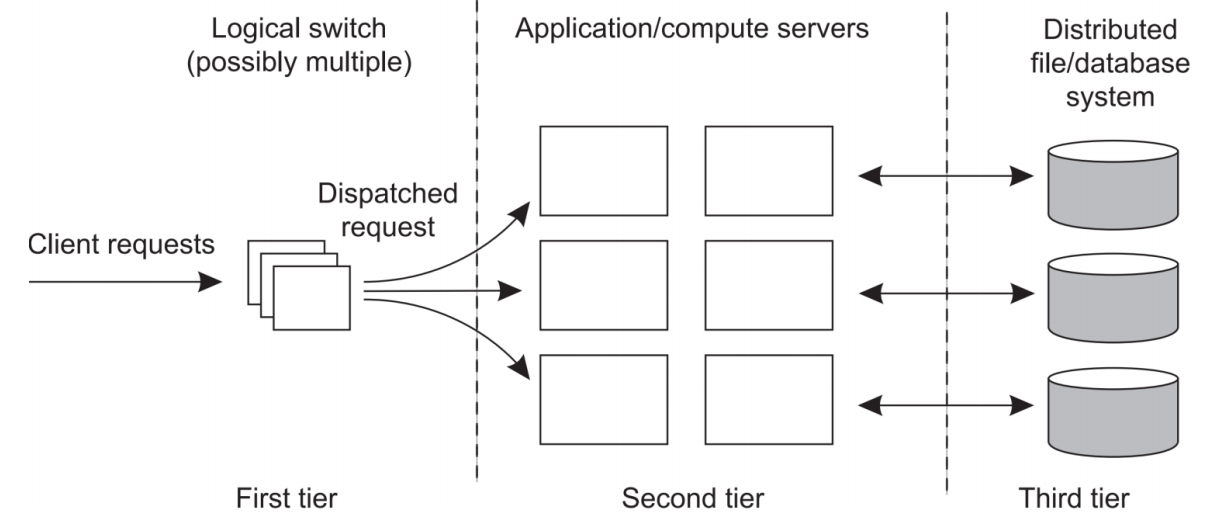
=> First tier에서는 Client의 Request를 받는 Dispatch Server를 운영하고, Second tier에서 processing, Third tier에서 data task를 수행한다.
=> 이 구조를 통해 하나의 AP를 제공하여 Access transparency를 구현하고 있다.(하나의 입구)
* Request Handling
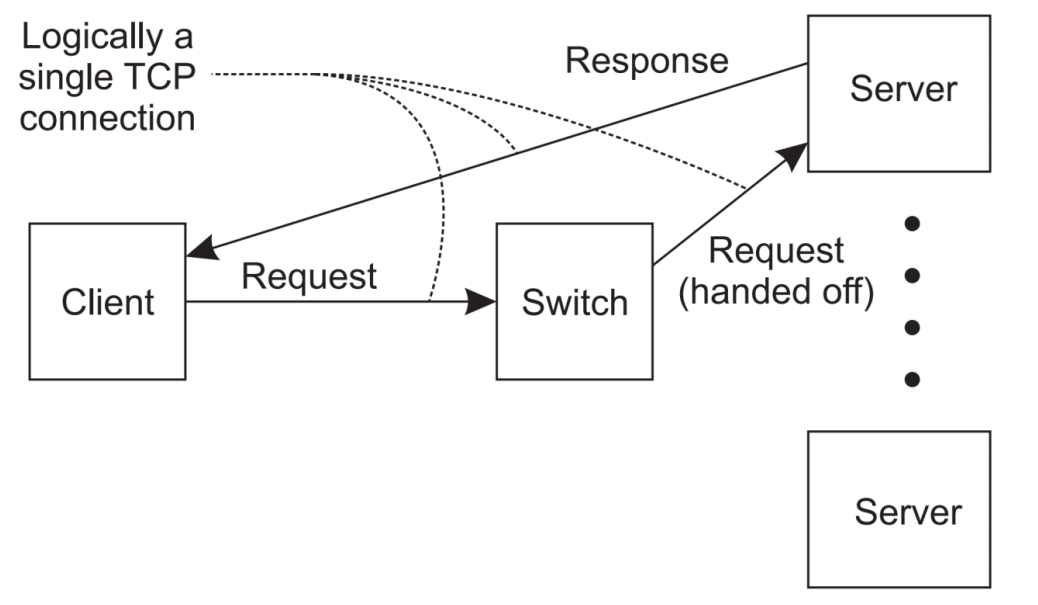
=> 그렇다면 First Tier의 Dispatch Server는 어떻게 Request를 Handling할까? 일단 Dispatch Server가 Server Cluster의 모든 communication을 다 처리하는 것은 여기서 bottleneck이 발생이 가능하다. 따라서 Request는 Dispatch가 받되, Response는 Second tier의 Worker Server가 직접 보내는 것으로 디자인한다. 이 때, Client는 다른 Server로 가는지 모르고 하나의 TCP Connection을 하는 것과 같이 된다.
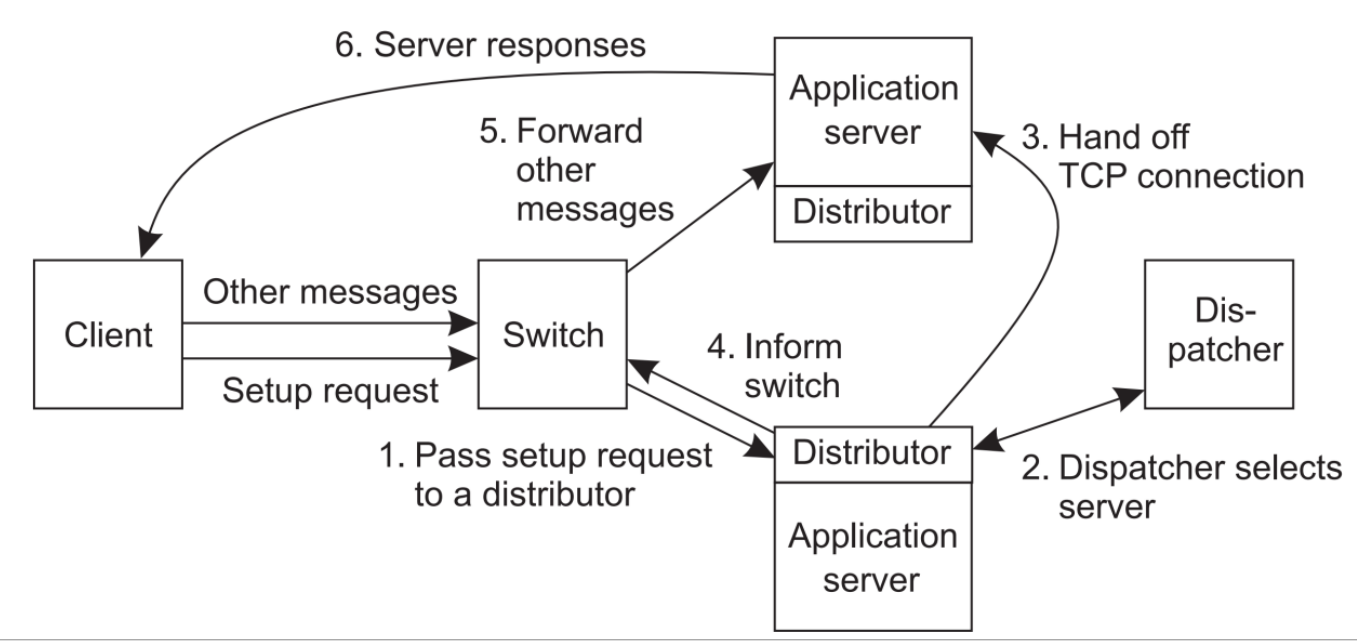
=> 다음으로 어떤 Server에 Request를 handoff 해줄지 정해야한다. 여기에는 2가지 방법이 있다.
1. Transport-layer switching : Dispatch Server에서 판단해서 전달하는 것이다. (Performance metric 확인)
2. Content-aware distribution : Switch가 request의 content를 읽어 best server를 선택한다. (Content-based)
=> Client가 Switch node에게 Request 전달 - Switch 주변 Server의 Distributor에 신호 전달 - Dispatcher까지 신호가 도달하면 Dispathcer가 확인 -> 정보를 다시 Server에 Call back -> Call back을 받은 Distributor는 선택된 Server와 Switch에게 해당 사실 전달 -> Switch는 선택된 Server에 message 전달 -> response
(Switch는 Message 전달자)
* 만약 서버가 넓은 인터넷 환경에 퍼져있다면?
=> 이 경우 Administrative problem이 발생가능하다. 이를 피하려면 Signle cloud provider의 data center만 이용해야한다.
=> Request dispatching은 DNS를 사용하여 Client가 보낸 Request와 client의 IP를 확인, 가장 가까운 Server에 전달해주는 방법이 있다. (Locality를 고려)
=> Client transparency를 지켜야 해서 Client의 Locality를 모를 때는 비효율적인 상황이 발생할 수 있다.
* Distributed servers with stable IPv6 address(es)
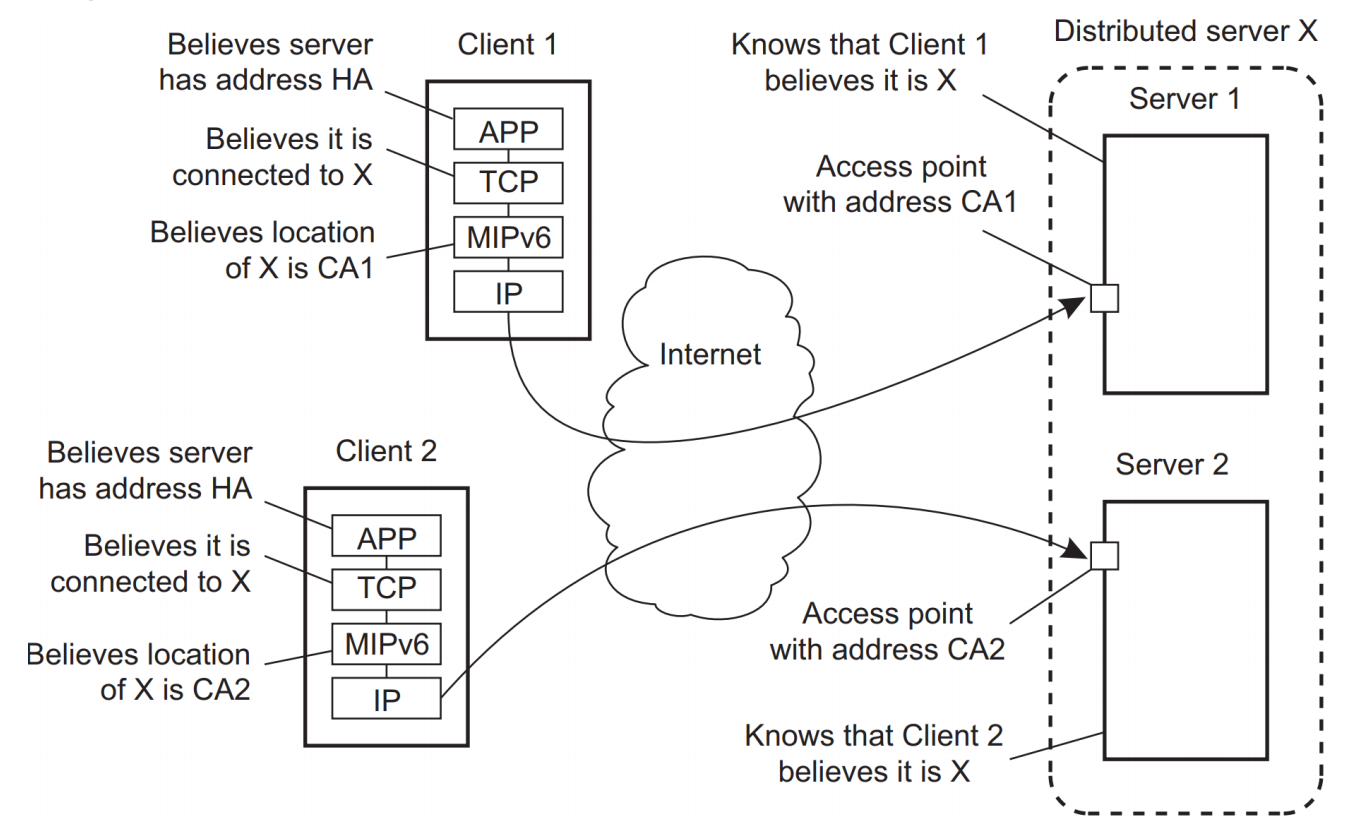
=> Home address는 client가 Server에 접근하기 위한 원래 Client가 가지고 있는 주소, Care-of address는 middleware, TCP layer에서 변환한 주소. (Distributed server X의 HA에 가기 위한 거쳐가야할 실제 address는 다를 수 있다.)
=> 이 경우 HA->CA로 Middleware에서 변환 후, Communication을 시작한다. 이러면 한 Server Cluster HA로 Client들이 연결하더라도, Cluster 내의 다른 Server에 연결될 수 있다. 분산 투명성이 지켜지는 것이다.(사진 참조)
=> Origin server가 HA를 관리하고, Collaborating peer에서 connection을 hand off 해준다.
5. Code migration
=> Code migration의 이유.
1. Load distribution : Code를 실행하는 Load 비용을 분산시켜줄 수 있다. 또한 데이터와 코드 실행 부분의 거리를 줄여 communication cost를 최소화 가능하다.
2. Flexibility : 유연한 분산 시스템의 운용을 위해 client가 원하는 곳으로 code를 옮길 수 있어야한다.
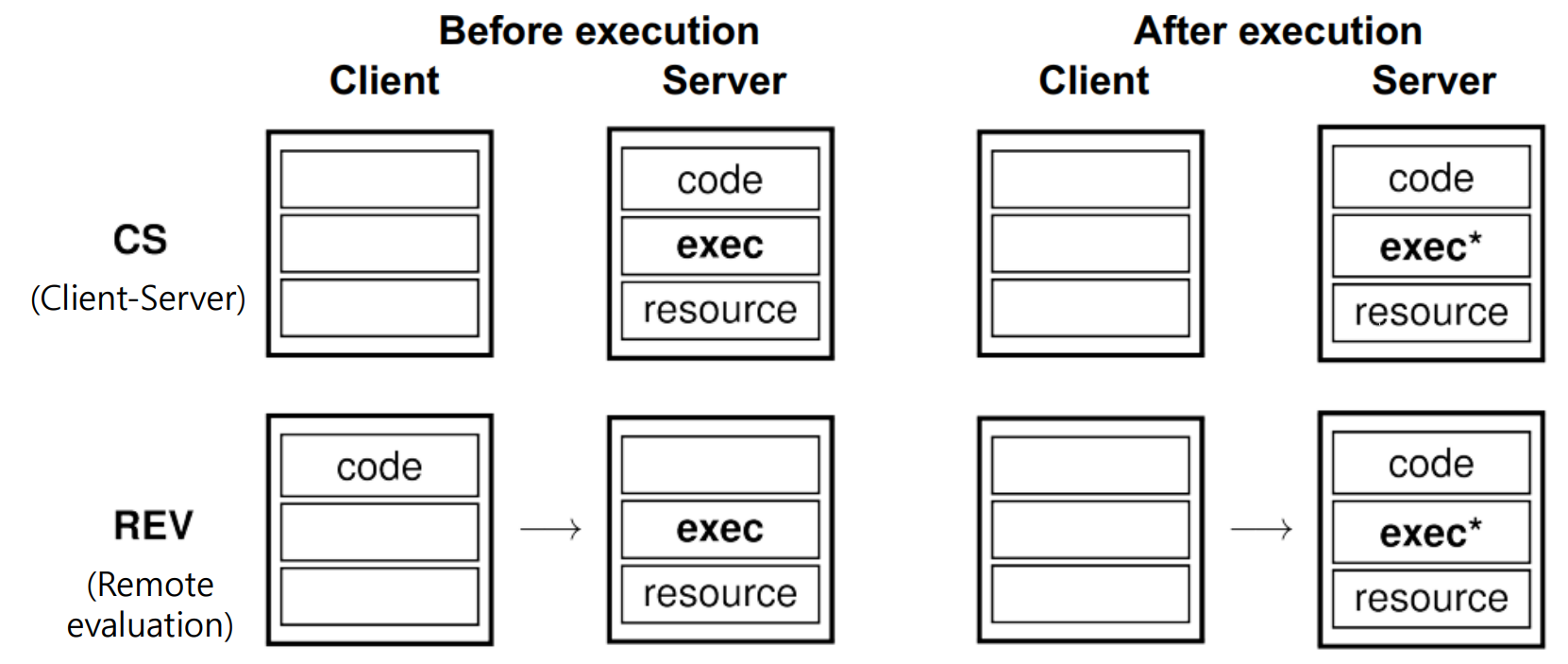
=> 기존 CS 구조에서는 보통 code도 서버에, 실행도 서버에서 하고 Client는 요청만 한다.
=> REV의 경우에는 Client가 code를 가지고 있고, 이를 Server의 Resource를 이용해 실행하고 싶다고 하는 경우이다.
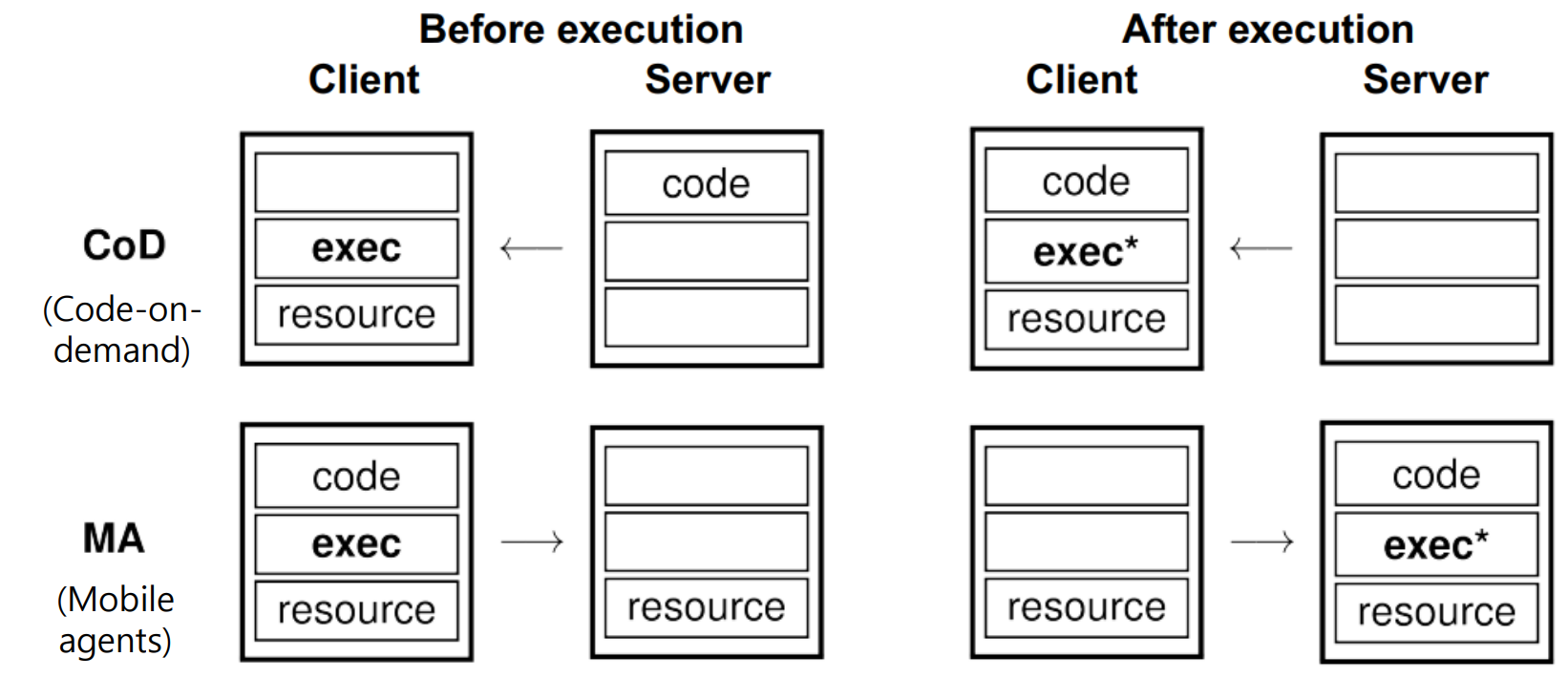
=> Code-on-demand는 Client가 resource를 지니고 있으면, Server가 code를 배포하는 형태이다.
=> Mobile Agents의 경우에는 어디서든 해도 되는데 옮겨가며 적절히 Balencing을 해주는 경우이다.
=> 어떤 것을 옮길까?
- Object components
- Code Segment(실제 코드), Data Segment(Machine과 연결되어있지 않은 Unattached Resource, 넓게 보아서 Fastened resource의 경우. fixed는 미포함), Execution state(Thread context - Stack, Counter)
=> Weak vs Strong
* Weak mobility
- code랑 data segment를 옮겨 다시 실행한다.
- 상대적으로 옮기기 쉽다.
* Strong mobility
- 모든 Object component를 다 옮겨 이동한 곳에서 이어서 실행한다.
- Migration, Cloning 방법이 있으며, Migration은 running process 자체를 이동, Cloning은 Execution state를 가져가지만 동일한 clone process가 생기는 것이다.
=> Migration에서 가장 큰 문제는 system들이 heterogeneous하단 것이다.
- Code migration을 하는 Target machine이 HW에 의존적인 Thread,Process,Processor context 등에 맞지 않을 수 있기 때문이다.
- 이를 해결하기 위해 VM을 활용하는 방안이 있다. (환경 통일)
* VM 에서 Code migration
1. 현재 VM의 메모리 페이지를 새로운 VM으로 전송, Migration 동안 초기 전송 이후 수정된 Memory page는 재전송하여 새로운 VM이 최신 데이터를 확보할 수 있도록 함.
(최종 동기화가 이루어질 때까지 운영 지속 가능, 데이터 일관성 보장)
(네트워크 트래픽 증가와 이동 과정동안 페이지 상태 관리 복잡성 발생)
2. Process를 아예 멈추고, 새로운 VM으로 옮긴 후 이어 실행.
(데이터 일관성을 보장하며 간단함)
(Stop Latency 발생)
3. 새로운 VM을 즉시 시작하고, 초기 전송된 메모리 페이지를 사용하여 운영 시작. 즉, 양쪽에서 바로 운영을 시작, 필요한 추가 메모리 페이지는 프로세스가 실행될 떄 필요에 따라 가져옴.
(즉시 시작이 가능하며 유연성이 높음.)
(성능이 영향이 가며 필요한 페이지 로드시 지연 발생, 복잡성 추가)
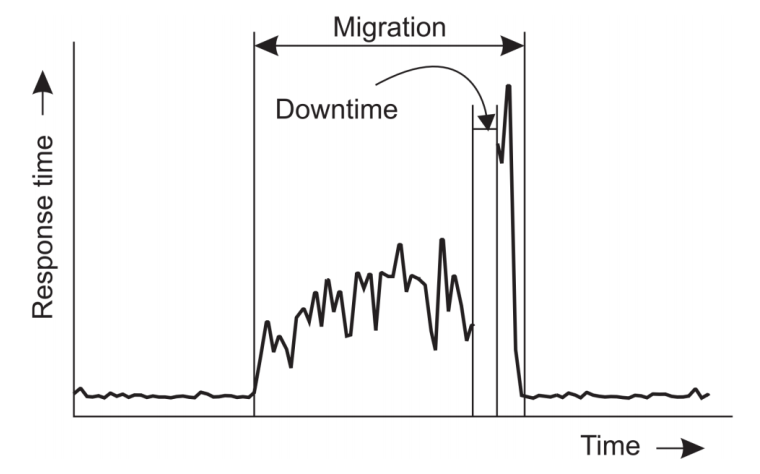
=> 결국 Migration 동안은 어떤 방법을 쓰든 해당 시간 동안 Response time이 늘어난다. 만약 아예 정지하고 Migration을 완료하는 방법을 사용하면 아예 Response가 없는 Downtime이 발생한다. 즉, Downtime을 없앨지, Migration 시간을 줄일지에 따른 Trade-off가 있는 것이다.
'개인 공부' 카테고리의 다른 글
| Distributed System - 5. Naming (0) | 2024.10.23 |
|---|---|
| Distributed System - 4. Communication (0) | 2024.10.20 |
| Distributed System - 2. Architectures (0) | 2024.10.01 |
| Distributed System - 1. Introduction (0) | 2024.09.30 |
| CLIP : Connecting text and images. (기본 개념) (0) | 2024.06.25 |