1. Architectures
- Distributed System의 아키텍처를 나누는 기준으로는 여러가지가 있을 수 있는데, 그 기준은 다음과 같다.
1. Replaceable : Component들이 잘 정의된 인터페이스를 가져서 다른 component와 상호작용이 가능한가?
2. Connectivity : Component 간의 연결이 어떻게 되어있는가?
3. Data exchange : Component 간 데이터 교환법이 어떻게 되는가?
4. Mechanism : Component와 Connector들이 시스템 상에서 어떻게 구성되는가?
(* Connector : Connector는 Component 간 통신 등을 중재하는 Component이다. 여기서 통신은 procedure call, messaging 등을 포함한다.)
=> 이 기준으로 나뉘는 아키텍처 타입은 다음과 같다.
1. Centralized, Decentralized, Hybird
2. Layered, Object-based, Data-based, Event-based
2. Layered architectures

- 상위 레이어에서 하위 레이어로 Request가 가고, 그 Request에 대한 Response가 하위 레이어에서 상위 레이어로 가는 구조를 가진다. 물론 Req/Res 가 오가는 양방향 콜이 있지만, 한 쪽만 보내는 단방향 콜이 있을 수도 있다.
- 통신 프로토콜이 이 구조에 해당한다. (TCP/IP, OCI 7계층)
* Application layering

- Application은 Application - Interface layer, Processing layer, Data layer로 나뉜다.
- Application - Interface layer는 end user와의 상호작용, Processing layer는 실제 기능을 수행, Data layer는 Process에 따른 데이터 저장, 쿼리 응답 등의 데이터 관련 작업을 수행한다.
- User 로부터 App-Interface => Processing => Data 순으로 req.가 가고, Data => Processing => App-Interface 순으로 res.가 간다.
3. Object-based architectures

- Object는 component를 가리키며, 각 object 끼리는 Procedure call로 연결되어 있다.
- 각 Object는 독립된 다른 Object와 상호작용하기 위한 Interface를 지니고 있다.
- 또한 각 Object는 Encapsulation 되어있어 그들이 제공하는 method나 State 등의 내부 구현 정보는 드러나지 않는다.
4. Publish - subscribe architectures

- Data-based, Event-based는 Publish - Subscribe Architecture 이다.
- 시간적 커플링 여부, 레퍼런스(메세지) 커플링 여부로 나눌 수 있다.
- 레퍼런스 커플링은 수신자가 명확히 정해져있는지에 대한 여부로 나뉜다.
- 시간적 컴플링은 보내면 수신자가 바로 확인해야하는지에 대한 여부로 나뉜다.
- Direct의 경우, 바로 정해진 대상에게 보내서 확인하지 않으면 소멸되므로 시간적,레퍼런스적으로 커플링 되어있다.
- Mailbox의 경우, 정해진 대상에게 보내지만, 시간적으로는 언제 읽든 보관되므로 레퍼런스적으로만 커플링 되어있다.
- Event-based의 경우 정해지지 않은 대상에게(자신을 Subscribe 하는 대상들) 일시성 Event를 날리므로 시간적으로만 커플링 되어있다.
- Shared data space의 경우 정해지지 않은 대상에게 저장되어있는 data를 요청이 들어오면 제공하므로 시간적, 레퍼런스적으로 커플링되어있지 않다.
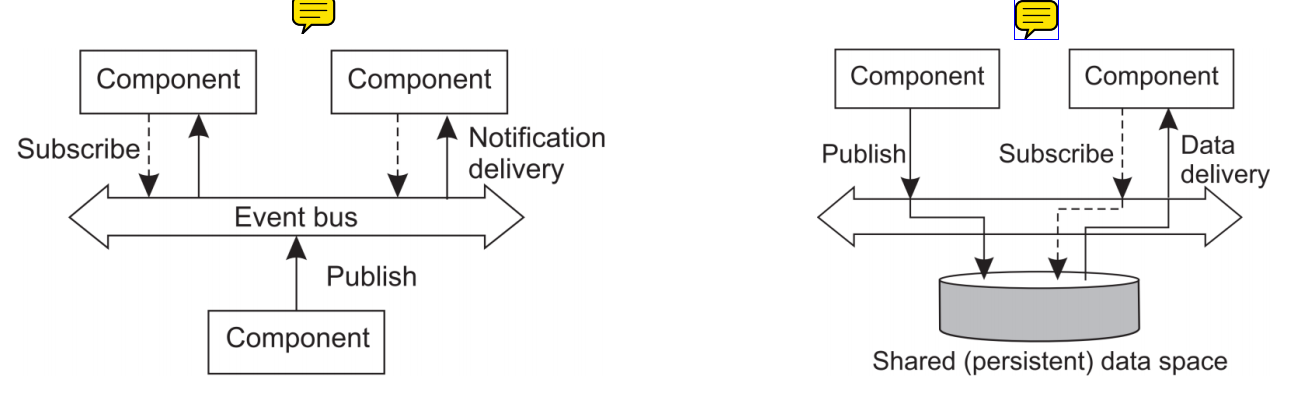
- 전자는 Event-based고 후자는 Shared data space이다.
- Event-based는 Event를 발생시키는 Component가 본인을 Subscribe하고 있는 Component들에게 이벤트를 전송한다.
이 때 Event를 받지 못하면 영구적으로 소멸된다.
- Shared data space는 Subscribe를 하면 누구든지 요청하여 데이터를 받아볼 수 있는 저장공간이 있다.
* Publish and Subscribe
=> 그렇다면 Publish와 Subscribe는 어떻게 정의해야할까?
- 각 Event를 E = (Attribute, {Value or Range})로 정의한다고 가정하자. 그러면 2개의 Subscription을 정의 가능하다.

1. Topic-based subscription : "Attribute == Value"
2. Content-based subscription : "Attribute ∈ Range"
- Topic-based의 경우에는 Publisher가 정의한 Event의 Attribute가 자신이 Subscribe한 Value와 같을 시 Event를 받는 것이다.
- Content-based의 경우에는 Value의 Range를 정의하여 Value의 Range까지 일하면 받아보는 형태이다. 이러한 매칭 여부를 확인하고 매칭시 데이터를 Subscriber로 이동시키는 역할을 Middleware가 수행하게 된다.
4. Middleware organization
- 위에서 살펴봤듯, 각 component 들의 고유한 레거시 인터페이스로 서로 통신하는 것은 어려운 일이다. 따라서 호환성을 확보하기 위해 Middleware가 분산 시스템의 OS로 들어가야하는 것이다.
- Middleware를 사용하면 컴포넌트끼리 별도의 상호작용 없이 어댑터로 연결되는 것처럼 편하게 연결이 가능하다. 그러나, 특정 application 만을 타게팅 해서 서비스하지 않기 때문에 Optimal이 아니라는 단점도 있다.
=> 이러한 단점을 해결하기 위해 Adaptable middleware를 개발하고자하는 노력이 있다.
- 이 Middleware organization의 기준으로 나눌 수 있는 아키텍처가 Centralized, Decentralized, Hybird 이다.
* Centralized system architectures
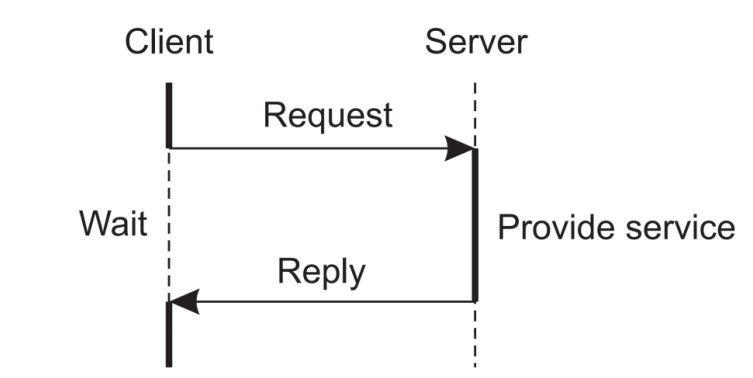
- 대표적인 Centralized로는 Client-Server model이 있다. 컴퓨터 네트워크를 배웠다면 익숙한 구조일 것이다.
- Client는 Req.를 서버에 보내고 Server는 그 Req.을 처리 후 그에 따른 Reply를 전송하므로 2단계에 걸친 2-Tierd 구조임을 알 수 있다.
- Single-tiered model : Terminal/mainframe 구성이 있다. 서버가 모든 것을 다 하고 그 결과만 디스플레이 하는 모니터가 있는 구조를 생각하면 된다.
- Two-tiered model : Client-Server model
- Three-tiered model : Server의 역할도 나누어 여러 layer로 분할한 구조.(Data server, Processing Server 등)
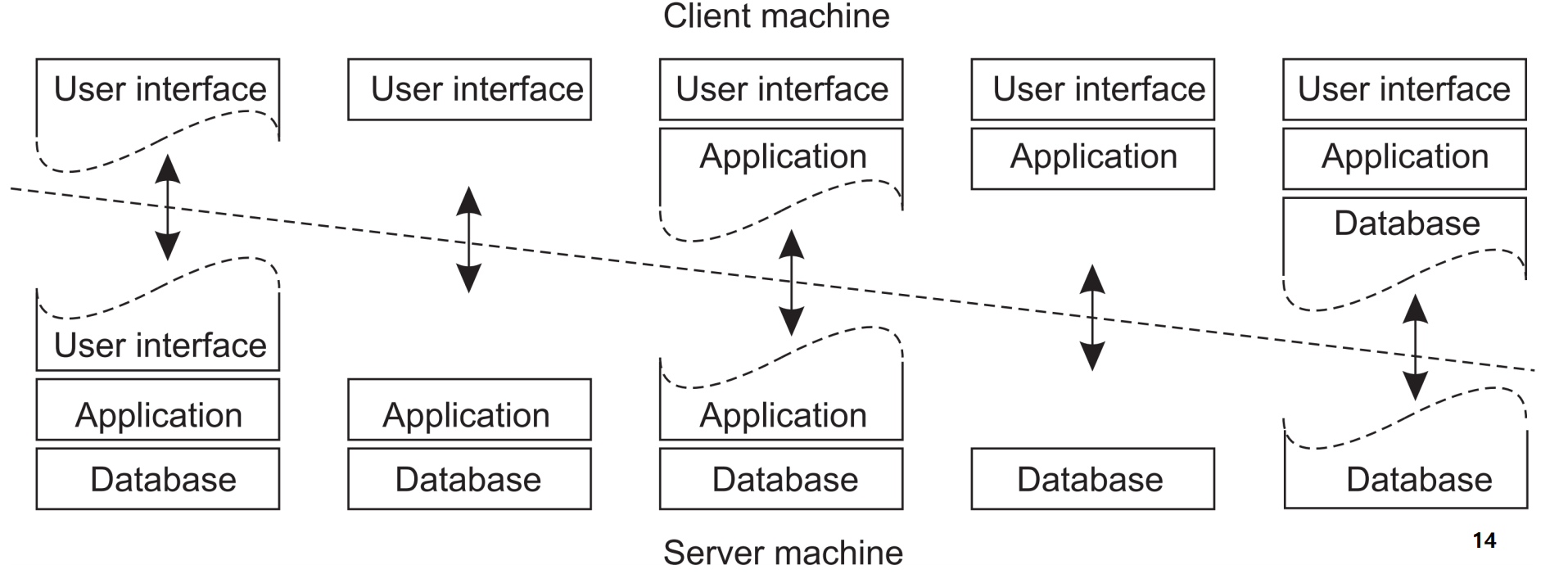
- 사진을 보면 서버에 더 Centralized 될 수록(왼 쪽으로 갈 수록) 서버의 부담이 증가하고 오른쪽으로 갈 수록 Client의 자율성이 증가하는 것을 볼 수 있다. UI+Application 까지 단계가 Processing layer에 해당한다. 따라서 Client-Application(Processing) - Database 의 3 layer로 정의가 가능하며, 따라서 Three-tiered architecture는 다음과 같이 정의된다.
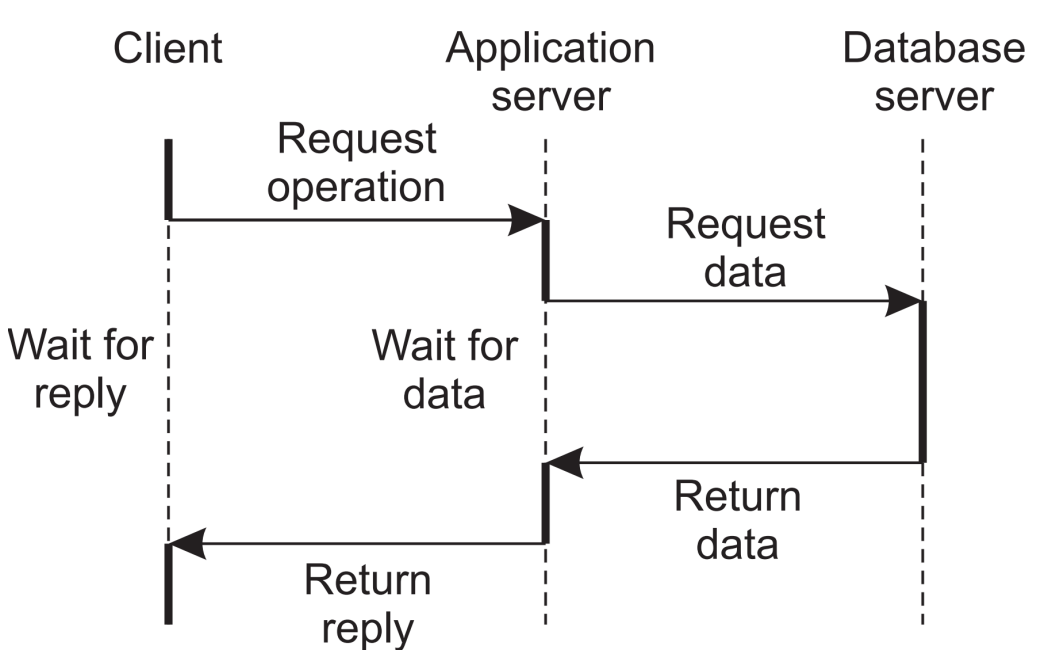
- 이러한 중앙 집중형 구조의 치명적 단점으로는 Single point failure가 발생시 모든 시스템이 한번에 붕괴되는 위험성과 서버에 큰 부하가 걸려 한 슈퍼 컴퓨터가 필요하다는 점이다. 그러나 중앙 집중형 구조를 채택함으로써 더 단순하고 빠른 프로토콜과 관리가 가능하며 복잡도가 내려가고, 보안도 유지를 하는 등의 장점도 있다.
* Decentralized organizations : Peer-to-Peer systems
- Decentralized organization을 구성하면 단순하게 생각해도 여러 노드가 분산되어 역할을 수행하므로 Single Point failure의 문제가 없을 것이다. 그러나, 누가 데이터를 저장하고 있을 것이며, 어떻게 Search해서 Deliver할 건지 등 복잡도가 매우 올라가고 관리가 어려워진다. 또한, 항상 모든 노드가 연결이 되어있다고 가정할 수가 없다.
- Decentralized는 또 다시 모든 노드가 동일한 역할을 수행할 것인지, 각 노드별로 역할을 정해줄 것인지로 나뉠 수 있다.
- Vertical distribuition : Application 의 3 layer 별(UI-processing-data)로 역할을 나누어 각 노드에 다른 역할을 부여하는 것이다.
- Horizontal distribution : 모든 node가 동일한 역할을 나누어 분담한다.
=> P2P architecture는 Horizontal distribution에 해당한다. 따라서 확장성과 유연성이 높다.
* Structured P2P

- 노드들 사이의 연결을 fix하는 등 구조를 만드는 형태의 P2P이다. 각 data item은 고유한 key를 가지며 이를 index로 바꿔 사용한다. (주로 hash function을 사용한다. { key(data item) = hash(data item's value) }
=> P2P system은 (key, value) 쌍을 저장한다.
- 이 대표적인 구조로는 Chord가 있다. 각 노드는 ring 형태로 구성된다고 보며, 각 노드는 m-bit identifier로 구분된다. (즉, 2^m 개의 노드를 운용 가능하다.) 각 데이터 아이템 역시 m-bit의 key로 해시되어있으며, k key를 가지는 data item은 node id가 k보다 크거나 같은 node 중 최소의 node에 저장된다. 이를 sucessor of key k 라고 한다. 또한 각 노드는 각자의 shortcut link도 가진다.
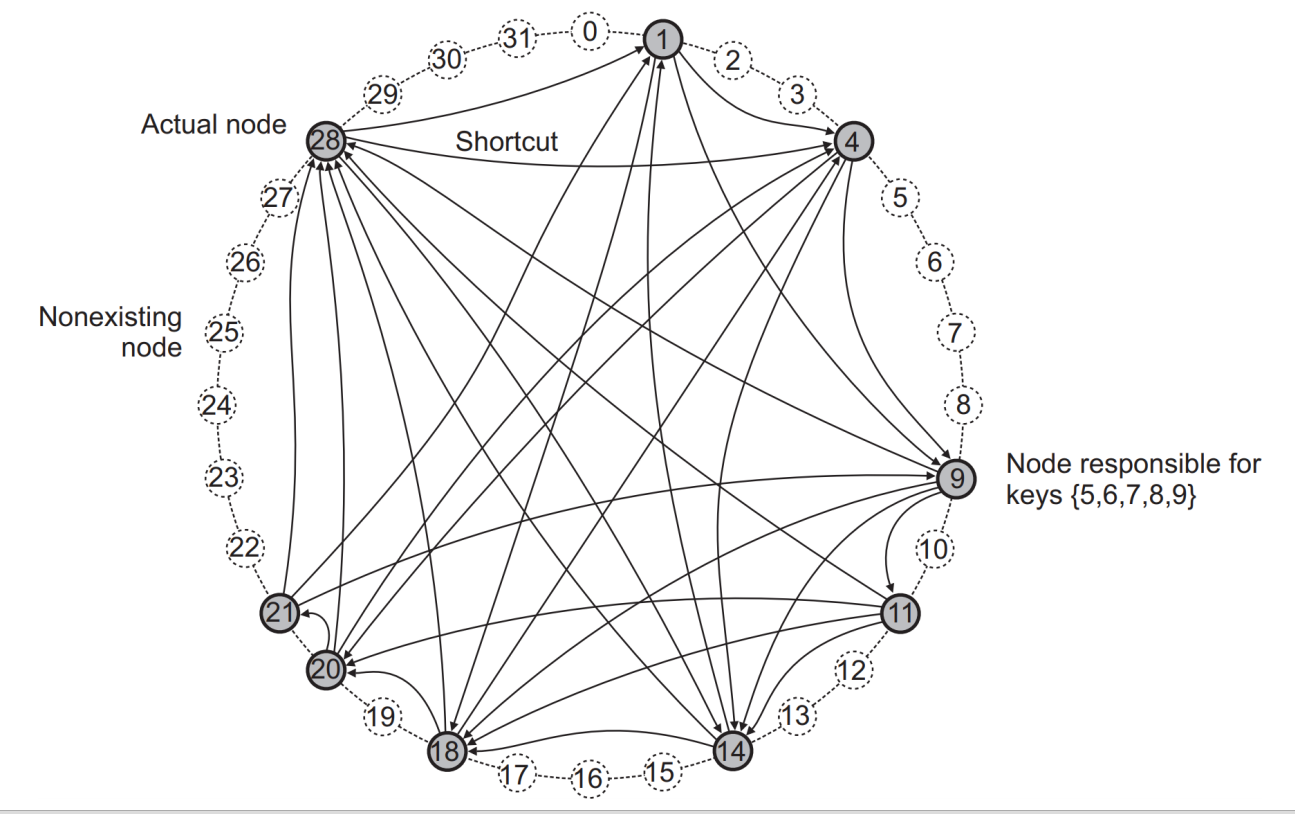
- 예를 들어, 사진의 9번 노드는 {5,6,7,8,9}까지의 데이터를 저장한다. 또한 9번 노드가 P2P system에서 빠지게 되면, 11번 노드가 그 데이터까지 저장하게 된다.
- 만약에 14번 노드에게 3번 아이템의 search query를 보내게 되면, 14번 노드는 자신이 가지고 있는 shortcut route {1,18,28} 중 에서 데이터 아이템의 key를 넘지 않는 가장 큰 node로 보내게 된다. 여기서는 1로 보낼 것이며, 1에서는 다시 자신이 가지고 있는 table {4, 20, 28} 중 3을 넘지 않는 shortcut link가 없으므로 4로 보내게 되고 search 과정이 끝나게 된다.
* Unstructed P2P
- 전체적인 overlay network가 명시적으로 보이지 않는 경우이다. 각 노드는 이웃의 ad hoc list만 유지하며 중앙 서버나 명확한 데이터 구조가 없다.
- 랜덤 그래프로 이루어져있다고 보면 되며, 각 노드는 인접한 다른 노드들과 임의로 연결되며 edge<u,v>는 항상 존재하는 것이 아니라 확률적으로 존재한다. 따라서 특수한 검색 방법이 필요하다.
1. Flooding : Flooding은 모든 이웃 노드에 검색 요청을 broadcast하는 방법이다. 노드 u는 특정 데이터 d를 찾기 위해 자신의 이웃들에게 요청을 보낸다. 각 이웃 노드는 자신이 해당 데이터가 없으면 또 다시 자신의 이웃들에게 요청을 재전송한다. 이 과정은 TTL(time-to-live)까지 지속된다. 당연하지만, 네트워크에 부담이 크다.
2. Random Walk : Flooding보다 효율적인 방법으로써, 요청을 글로벌하게 전송하는 것이 아니라 임의의 이웃 노드만 선정하여 전송한다. 당연히 트래픽이 적고 네트워크의 부하는 낮아지만, 당연히 Response Latency는 증가하게 된다.
- Flooding vs Random walk
=> N nodes 들과 각 data item들이 r 개의 random chosen nodes에게 복사되어있다고 가정하자.
=> Random walk가 이를 k 시도후에 찾아낼 확률은 포아송 분포에 의해 다음과 같이 모델링 된다.
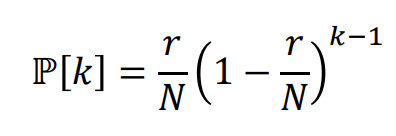
=> 따라서 Expected number of nodes는 다음과 같이 모델링 된다.
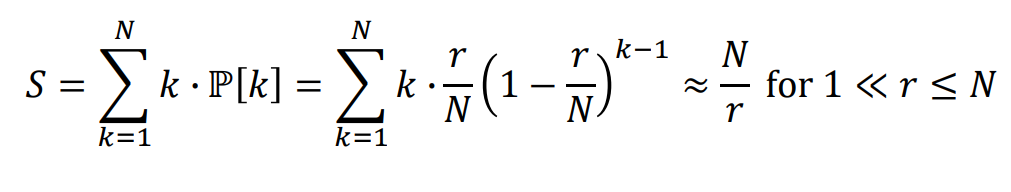
=> 즉, 데이터 복사 양을 늘릴 수록 search size는 작아지고, network에 node가 많아질 수록 search size는 커진다.
=> Flooding의 경우, 각 node가 d개의 neighbor를 지닌다하면 k step 이후에 R(k) = d*(d-1)^(k-1) 개의 노드를 접근하게 된다. 즉, r/N이 저장된 노드가 선택될 확률이고,
(r/N)*R(k) >=1 이 될 때, data item을 찾았다고 볼 수 있는 것이다.
=> r/N = 0.001이면 S ~= 1000 이고, d=10, k=4라 할 때, flooding 방법은 7290개의 노드를 탐색한다.
=> 즉, 검색 기댓값인 1000개의 노드를 찾아야하고, flooding은 4번만에 7290개의 노드를 탐색하므로 빠르게 찾을 수 있다.
- Super-peer networks
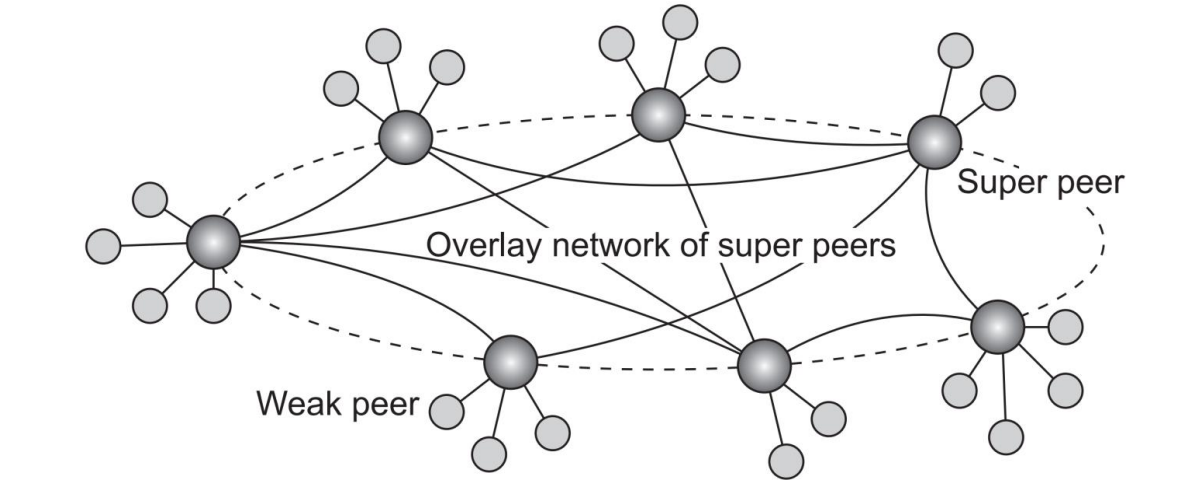
- 순수 P2P 방식의 평등한 역할 부여 방법으로는 비효율성이 발생할 수 있다. 모든 노드가 데이터를 공유하고 검색을 처리하므로 탐색 시간이 길어지고 네트워크 부하가 오는 것이다.
- Super-peer는 Verticalized된 방식으로, 에너지 수준과 계산력 등이 높은 node를 super peer로 선정하여 일부 Centralized된 역할을 수행하는 것이다. 이 방식에서는 Weak peer 들이 Super-peer에 연결되고 Super-peer는 네트워크 상에서 더 효율적으로 검색을 수행한다. 마치 Router와 그에 연결된 node들, 그리고 그 Router가 연결된 backbone 네트워크를 떠올리면 된다.
* Hybird architectures
- Edge-server architecture
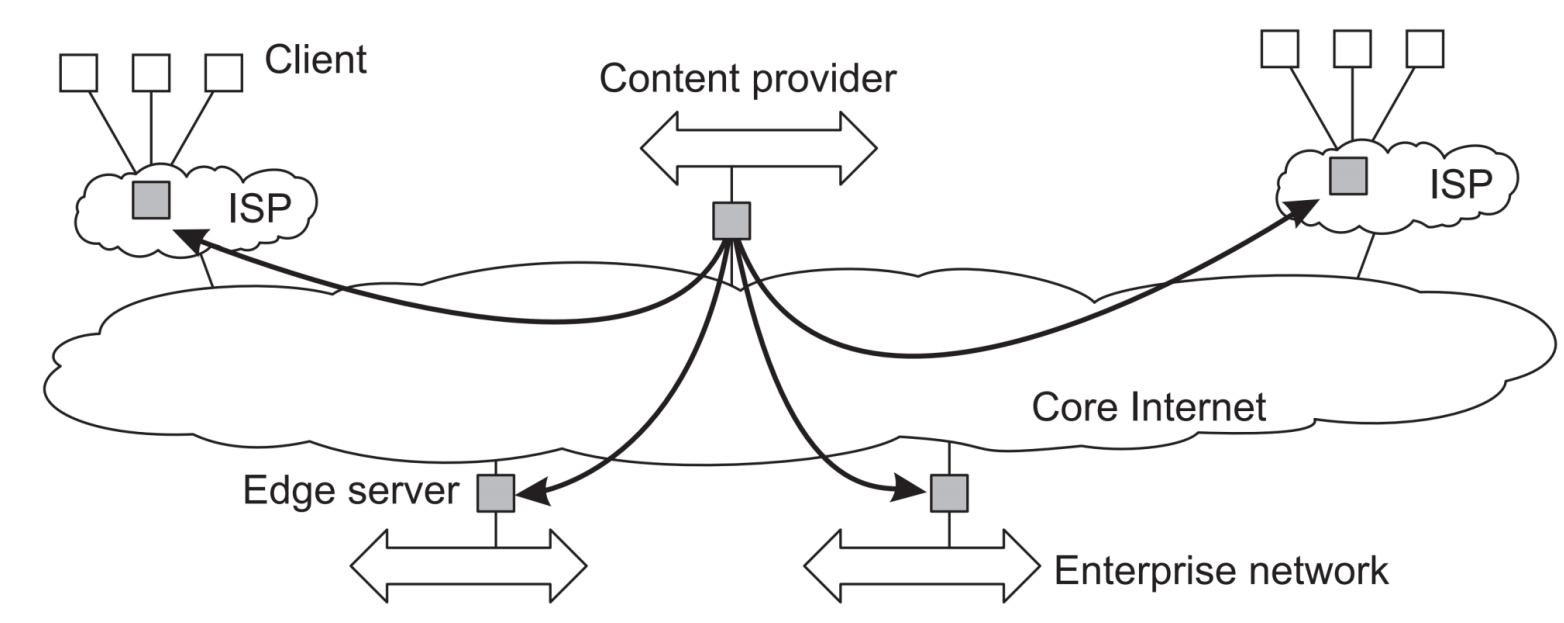
- Hybird network architecture의 일종으로, 네트워크의 edge 단에 서버를 배치하여 성능 향상을 꾀하는 방식이다.
- Edge server 란 end user와 연결되어있는 서버이다. 이 서버는 인터넷의 중심부에서 발생하는 core traffic 을 처리하는 대신, 사용자와 가까운 위치에서 데이터를 처리하여 성능을 향상시킨다.
- Clinet가 요청하는 데이터를 edge server에 캐시하거나 미리 배포하여 latency를 줄이고 traffic load를 분산시킨다.
(대표적인 예시로 Content Delivery Network가 있다.)
- Edge infrastructure를 구성하는 장점
1. Latency의 감소, Bandwdith의 확보 : Real-Time application에게 중요하다. (Youtube 등)
2. Reliability : 높은 연결 신뢰성을 확보 가능하다. 굳이 cloud가 아니라 local에서 데이터를 처리하기 때문이다. (연결 과정이 짧다.)
3. Security와 Privacy : 엣지 서버를 활용하면 데이터를 로컬에서 처리할 수 있어 강력한 보호를 제공 가능하다.
=> 그러나 여느 방법이 다 그렇듯이 Decentralized 성향을 띄면 복잡도가 증가한다. Edge server는 cloud보다 리소스가 풍부하지 않아 Resource allocation의 문제도 있을 수 있고, 언제 어디에 서비스를 배치할 지에 관한 Service placement 문제,
어떤 Edge server를 어떤 node에 연결시킬지에 대한 Edge Selection 의 문제가 있다.(항상 가까운게 정답은 아니다.)
* Example : BitTorrent case
- 파일을 여러 청크로 나누고 이를 여러 노드가 나누어 다운로드하고 업로드한다.
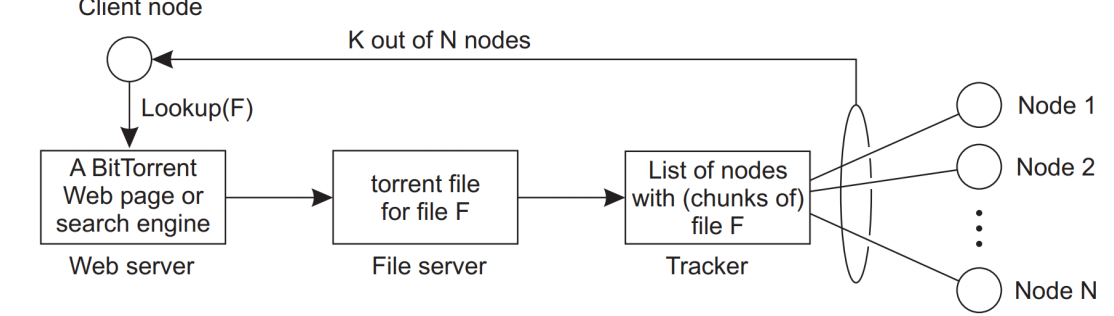
- 사용자(Client node)는 Global Directory(Web server)에서 원하는 파일 F를 검색한다. Web server는 File server에게 F를 찾게 하고, Tracker는 F를 저장 중인 node list를 제공한다. Client node는 return으로 온 노드 리스트의 노드들과 연결되어 파일 F의 청크를 다운로드하고 전체 파일을 조립하기 시작한다.
- Tracker는 파일 F에 대한 정보를 가지고 있으며 이 파일을 다운로드하기 위한 현재의 Swarm을 추적해준다.
(Swarm : 파일을 다운로드 중인 모든 Client node 들의 집합)
- Client A는 Swarm의 전체와 한번에 통신하지 않고, Swarm에서 일부 노드들과만 통신한다. 이 노드들의 집합을 Neighbor set이라고 한다. (네트워크 부하를 줄이고, 효율적인 데이터 교환을 가능하게 한다.)
- 상호 통신 규칙 : 만약 B 노드가 A의 이웃 집합에 포함된다면 A도 B의 이웃 집합에 포함된다. 즉 일방적으로 파일을 주는 관계는 없다.
- Neighbor set의 업데이트 : Neighbor set은 Tracker에 의해 정기적으로 업데이트 된다.
♠ Exchange Blocks
- 파일은 동일한 크기의 여러 Block으로 나누어진다.
- peer들은 자신이 가진 파일 조각을 다른 노드와 교환한다. 이를 통해 각 노드는 자신이 아직 가지지 않은 파일의 나머지 부분을 얻을 수 있다.
- A는 자신이 "소유"하고 있는 블록만 업로드 가능하다.
- B가 A의 이웃 노드로 간주되기 위해서는 B가 A의 필요한 블록을 가지고 있어야한다. 즉 서로 주고 받고가 가능해야 두 노드간의 교환이 가능하다.
=> 그러면 처음에 아무 데이터 정보도 없을 때 A는 어떻게 Swarm에 합류할까?
♠ BitTorrent의 3 단계
1. Bootstrap : A가 처음으로 파일 블록 조각을 받는 단계이다. 이 때, BitTorrent protocol은 optimistic unchoking이라는 방식으로 시작된다. 이 단계에서는 예외적으로 Swarm에 있는 다른 노드로부터 일방적으로 파일을 제공받을 수 있다.
2. Trading : A 노드가 적어도 하나 이상의 파일 조각을 받은 후, 다른 노드와 교환할 수 있는 파일 조각이 생기면 Trading이 시작된다. A의 neighbor set Na와 통신하며 서로 필요한 조각을 주고받으며 교환을 진행한다.
3. Last download phase : 다운로드가 끝나갈 수록 A는 완성된 파일을 가지게 된다. 즉, 받아야할 블록이 줄어들며 결국에는 자신의 Neighbor set에 교환할 파일 조각이 더 이상 없을 때가 온다. 이 때는 새로운 파일 조각을 얻기 위해 새로운 노드가 네트워크에 합류할 때까지 기다려야한다. 즉, A는 추가 파일 조각을 얻기 위해 새로 도착한 피어에 의존하게 되며, Neighbor set Na는 오직 Tracker에 의해 업데이트 된다.
'개인 공부' 카테고리의 다른 글
| Distributed System - 4. Communication (0) | 2024.10.20 |
|---|---|
| Distributed System - 3. Processes (0) | 2024.10.07 |
| Distributed System - 1. Introduction (0) | 2024.09.30 |
| CLIP : Connecting text and images. (기본 개념) (0) | 2024.06.25 |
| Q-Learning (0) | 2024.06.24 |