* Descriptive Statistics
=> 주어진 데이터를 잘 요약하는 방법. data를 의미있게 요약한다.(주어진 데이터의 정규분포 여부 등)
(여기서 Data는 Numerical, Categorical를 생각한다.)
- Distribution
=> 특정 Range로 나누어 data들의 frequency로 나타낸 것.(Data visualization과 Data reduction에서 다루었다.)
=> Distribution을 묘사하는 방법은 Visualization으로 하는 방법과 Numerical 적인 수치로 묘사하는 방법이 있다.
물론 이 방법 중 하나를 골라쓰는 것이 아니라 둘다 사용해야 객관적인 묘사가 가능하다.
(Histogram을 그리면서 mean, S.D. 와 같은 수치도 묘사한다.)
* Distribution의 수치적 묘사
=> Distribution은 중심 경향(Mean, Median, mode), 얼마나 분산되어있나(Variance, Standard Deviation), 어떤 모양인가(Skewness,kurtosis)를 기반으로 수치적인 묘사가 가능하다.
- 중심 경향
1. Mean

=> 우리가 흔히 아는 산술평균이다.
2. Median

=> data들을 sorting한 후, 중앙에 있는 값을 골라낸다. 데이터의 수가 짝수일 경우 n-1,n+1의 수의 평균, 홀수일 경우 그냥 n번째 수를 고르면 된다.(n= N/2, N은 len(dataset))
3. Mode
=> 최빈값이다. 최빈 값이 1개일 시 unimodal, 2개일시 bimodal 그 이상일시 multimodal이라고 한다.
* mean Vs Median
=> mean은 모든 값이 다 반영되나 Median은 양 끝단에 데이터가 추가되면 중앙값이 한칸 변하는 정도의 변화만이 있다.
즉, mean이 더 계산이 쉽고 이해하기 쉬우나, mean보단 median이 좀 더 Outler에 robust한 특성을 지니고 있다.
- 얼마나 분산되었나를 파악하는 수치들
1. Range
=> 데이터가 분포하는 범위를 말한다.( [10,5,2,100] => 100-2=98. )
2. Variance

=> (x - 평균)^2의 값을 n-1로 나눈 수치이다.(표본 분산의 경우를 가정하여 불편 추정량으로 나눈다.)
3. Standard Deviation
=> Variance에 root 처리를 해준 것이다. 이를 통해 scale을 기존 y scale과 똑같이 가져갈 수 있다.
4. Quartiles
=> Dataset을 정렬 후, 4 분할로 나누어 Q1,Q2,Q3,Q4의 4단계로 나눈 것을 말한다. data set size n일 시
(n+1)/q 를 통해 어디까지가 어디에 quartile에 속하는지 알 수 있고, 정확히 나누어떨어지지 않을 시 내림처리를 한다.
(Q2의 upperbound가 중앙값이 되게 된다.)
5. IQR
=> Q3-Q1의 크기이다. 이 크기를 통해 해당 구간에 얼마나 많은 데이터가 속하는지(중심분포)를 알 수 있다.

7, Percentiles
=> 데이터를 (n+1)/100으로 쪼개서 퍼센테이지로 표시해 tile을 나누는 것이다. 25,50,75 %의 구간으로 나눈다.
8. Coefficient of Variation

=> Scale 요소를 뺴고 순전히 얼마나 "차이"가 나나를 보고싶을 때 사용하는 계수이다.
9. Five number summary
=> (min,Q1,median,Q3,max)로 나타낸 5-tuple 표기법이다.
-> 그렇다면 어떤 수치로 Distribution을 묘사해야할까? 정해진 답은 없다. 만약 데이터에 Oulier가 많다면 Mean,S.D.로 만 표현하는 것은 좋지 않은 접근법일 것이다.(데이터의 모양도 봐야함.)
- 데이터의 모양을 묘사하는 수치들
1. Skewness

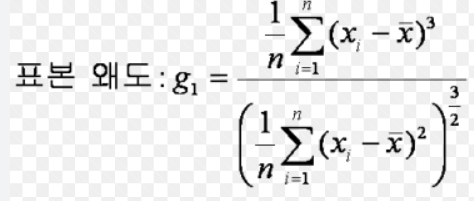
데이터의 분포가 어디로 치우쳤나를 묘사하는 계수이다. 값이 양수면 왼쪽으로 치우치며, 오른쪽 꼬리를 지닌다.
값이 음수면 오른쪽으로 치우치며 왼쪽 꼬리를 지닌다.
2. Kurtosis


=> 데이터의 분포가 얼마나 완만한지를 나타내는 계수이다. 크면 클수록 뾰족하다.
-> 지금까지 수치 분포를 어떻게 묘사할 수 있는지 3가지 타입으로 알아보았다. 그런데 만약에 데이터가 페어링이 되어있는(zip) 형태면 어떻게 해야할까? (ex: x,y 데이터) == 2개의 데이터를 어떻게 similarity 데이터로 묘사할까
1. Distance



=> Distance는 단위가 같은 데이터 쌍에 적합한 metric이다.
거리로 는 L2(Euclidean), L1(Manhattan) 과 같은 단위가 있다.
2. Correlation


- 두 수치 변수 간의 연관성을 나타내는 척도이다.(단, 직접적인 인과관계가 아니라 Covariation이다.)
- 대표적인 척도로는 Pearson correlation coefficient가 있다.
- 공식을 보면 분자가 각각의 data가 자신의 mean에서 얼마나 벗어났는지를 알려주는 것이다. 해당 값이 양의 방향으로 크면 클 수록 양의 선형관계가 있는 것이고, 음의 방향으로 크면 음의 선형관계가 있는 것이다.
=> 절댓값이 .5보다 크면 강한 관계가 있는 것이다. 보통 .3 이상이면 관계가 있다고 볼 수 있다.
* Correlation을 캡처할 때 주의할 점

a. Variable들은 interval 혹은 Ratio level에서 정의되어있어야한다.
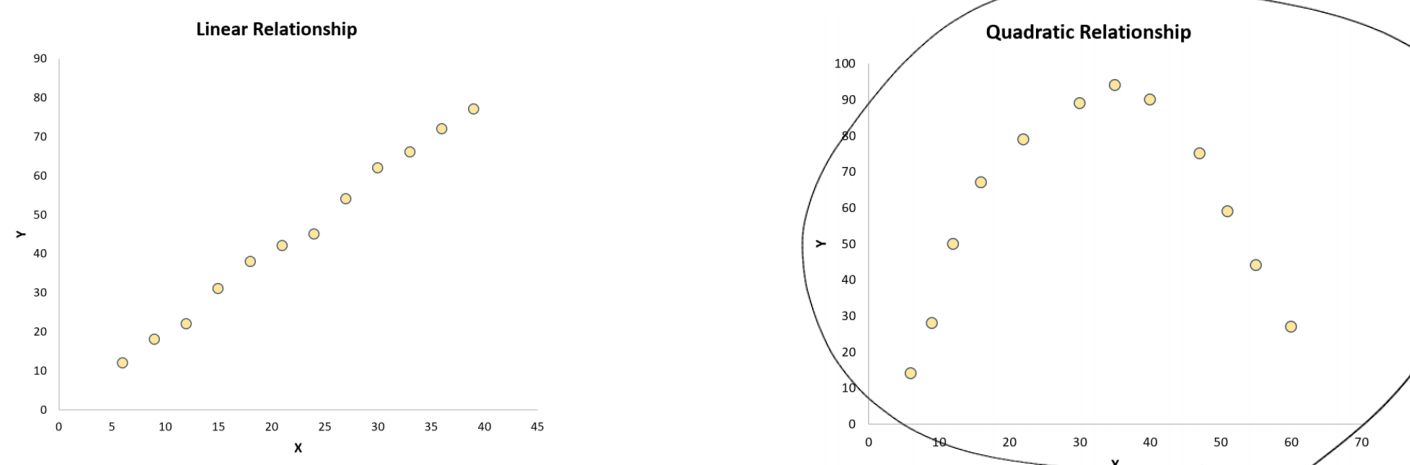
b. 애초에 Variable들이 어느정도 선형성을 띄어야 값에 의미가 있다. 하필이면 찍은 쪽이 Quadratic Relationship의 초반, 후반 부분일 경우 오해의 여지가 생긴다. (따라서 2개의 변수에 대해 미리 scatter plot을 그려보기.)
c. Pearson Correlation coefficient를 구하기 위해서는 2개의 변수가 러프하게라도 정규분포를 따라야한다.
(Histogram을 그려보는 방법이 빠르다.)
d. 사실 데이터가 선형을 띄는데도 큰 Outlier 한 두개에 선형성이 망가져 버려 오해를 할 수 있다. 따라서 Outlier 제거 절차 이후에 구해볼 수 있다.
e. 관계있는 쌍들로 Correlation을 계산해야한다. 즉 same subject로부터 추출된 2개의 데이터 쌍이어야한다.(ex: X,Y)
(예를 들어 weight과 height의 관계를 따지려면 같은 데이터셋에서 같은 항목에서 추출된 데이터 셋이어야한다. 미국 사람의 키와 한국 사람의 몸무게를 들고와서 상관관계를 계산하는건 의미가 없다.)
f. 각 Feature들은 독립적이어야한다.
3. Covariance(Numeric Data)


-> correlation과 비슷하다. 결국 A와 B가 평균에서 얼마나 떨어졌나에 대한 평균이다.
- 양의 관계가 있을 경우, A,B 둘 다 expected value보다 큰 경향이 있다. ( 두 변수는 같은 방향으로 움직인다. )
- 음의 관계가 있을 경우, A가 expected value보다 크면, B는 expected value보다 작은 경향이 있다. ( 두 변수는 반대로 움직인다. )
- 0일 경우 선형적인 관계가 없음을 의미할 수도 있다.( 그렇다고 꼭 독립이라는 것은 아니다. 독립이면 Cov가 0이지만, Cov가 0이라고 독립은 아니다. )
* Anscombe's quartet

- 이 데이터들은 전부 수치상으로는 똑같은 데이터이다. 결국 그려봐야 안다는 것이다.
'개인 공부' 카테고리의 다른 글
| 데이터 과학 - 10. Association Rule Mining (0) | 2024.04.24 |
|---|---|
| 데이터 과학 - 9. Statistical Data Analysis PART 2 (0) | 2024.04.21 |
| 데이터 과학 - 8. Data Preprocessing Part 2 (0) | 2024.04.18 |
| HCI - Safety (0) | 2024.04.16 |
| HCI - Efficiency (0) | 2024.04.16 |