universal set U가 있다고 가정하자. 이 U의 subset들을 itemset I라고 정의하고, |I| = k일 시, k-Itemset이라고 부를 수 있다고 하자.
이 때 Association Rule Mining에서 관심이 있는 ItemSet들의 집합을 S라고 하자. S의 각 itemset들을 Transaction T라고 정의하면 결론적으로 itemset I의 Support는 다음과 같이 정의된다.

즉, support(I)는 전체 Transaction에서 특정 Itemset들이 얼마나 포함되는 지를 의미한다.

=> I = {beer, bread}일 때 suppprt(I)는 Transaction들에서 1.4.5.6이 해당되므로 4이다.
이 때, association rule R은 I1->I2와 같은 형태로 묘사된다.(단, 둘이 disjoint 해야함.)
이 때, sup(R) = I1 U I2이고 confidence R conf(R) 은 sup(I1 U I2) / sup(I1) 이다.

=> {beer} -> {bread}의 support는 1,4,5,6으로 4이고, conf(R)은 sup(beer)가 5이므로 4/5이다.
=> {beer} -> {milk}의 support는 3이고 sup(beer)가 5이므로 3/5이다.

다음의 사례를 보면 Item set의 item들이 같으면 Support는 같을 수 밖에 없다는 것을 알 수 있다. 그러나 조합에 따라 Confidence는 바뀌는 것 역시 관찰할 수 있다. 따라서 Sup, Confidence Requirement는 분리되어 생각되어야함을 알 수 있다.
즉, Association Rule Mining Problem은 주어진 minsup, minconf requirement를 충족하는 association rule R을 찾는 것이다.
이러한 minsup, minconf가 충족된 Association rule을 찾아 데이터의 규칙성을 분석이 가능하다.
일단 최대한 많은 assocation rule들을 찾고, 그 룰에 대한 sup, conf를 계산 후 만족하는 rule들을 남기는 것이 주로 접근하는 접근법이다.
주어진 d unique item들에 대해 2^d개의 itemset들이 가능하다. 이때, 가능한 association rule의 갯수는 다음과 같다.

d개의 item 중 k개를 골랐을 때, 나머지 item을 정하는 경우의 수이다.
* Aprori
=> I가 주어진 itemset이라 할 때, sup(I) >= minsup 일 때, I는 frequent하다고 한다.

minsup이 3일 때, beer와 beer,bread 그리고 beer,bread,milk는 frequent한 itemset들이다.(5,4,3)
이런 식으로 모든 frequent Itemset을 찾고, 해당 set에 대해 rule을 제작한다.
1. 모든 frequent itemset들에 대해 기록한다.
2. frequent itemset들에 대해 association rule을 만든다.
(Aprori 과정)
이때 support( I1 U I2 ) <= support( I1 )은 항상 성립한다.
그리고 I1이 I2의 부분 집합일 때, I2가 frequent하면, I1 역시 당연히 frequent하다.
또한 I1이 frequent하지 않다면, I2 역시 frequent할 수 없다.


예를 들어, {beer, bread}가 frequent하다면, beer, bread는 frequent 해야한다.
beer가 frequent하지 않다면, beer를 포함한 모든 set은 frequent 할 수 없다.
이 정의를 이용하면, 찾아낸 모든 rule에 대해 minsup, minconf threshold 계산은 할 필요가 없다.
찾아낸 룰을 검사했을 때, infrequent가 나온다면, 해당 룰을 포함한 모든 룰은 자동으로 pruning되기 때문이다.

결론적으로 Aprori 방법은 다음의 절차를 거친다.
1. k=1
2. Fk를 찾고, Fk = ∅ 일 시, 중지한다.
3. k+=1; go to Step 2
Ex)

U = {beer, bread, butter, milk, potato, onion} 이고 k=1이기 때문에 Candidate set은
C1 = {{beer},{bread},{butter},{milk},{potato},{onion}}
이 때, 각 support는 5, 4, 3, 4, 1, 2 이므로 Frequent set은
F1 = {{beer}, {bread}, {butter},{milk}}이다. 그 후 k를 2로 하고 다음 단계로 넘어간다.

이제 Global Set이 U에서 F1이 되었다. 이제 F1에서 가능한 association rule candidate set을 찾자.
C2 = {{beer,bread},{beer,butter},{beer,milk},{bread,butter},{bread,milk},{butter,milk}} 가 된다.
여기서 다시 Frequent set을 찾는다. 각각 suport는 4, 3, 3, 2, 3, 3 이므로
F2 = {{beer,bread},{beer,butter},{beer,milk},{bread,milk},{butter,milk}}가 된다.
그 뒤 k=3으로 세팅하고 반복한다.

이렇게 F3 = {{beer,bread,milk}}를 찾아내면, k=4일 때, 더 이상 가능한 set이 없다.(이미 F3의 원소가 1개이다.)
따라서 알고리즘을 종료한다.
이렇게 해서 Frequent Itemset들을 찾아냈으면, 이제 Rule Generation을 해야한다.
이전 단계에서 찾아낸 Frequent Itemset I에 대해 I를 서로 겹치지 않는 I1, I2로 나누어 I1 U I2 = I 면서 I1 ∩ I2 = ∅인 candidate association rule들을 생성한다.
그 뒤, 모든 신뢰도를 계산하고 가능한 규칙을 report 한다. (즉, minsup을 만족시키는 애들 중 minconf 만족시키는 rule을 찾는 것이다.)
이 때, I와 I'가 2개의 frequent item set들이라면, I에서 생성된 것과 I'에서 생성된 규칙이 동일할 수 없다.
(이전 단계에서 frequent item set을 찾는 과정을 보면 쉽게 알 수 있다.)
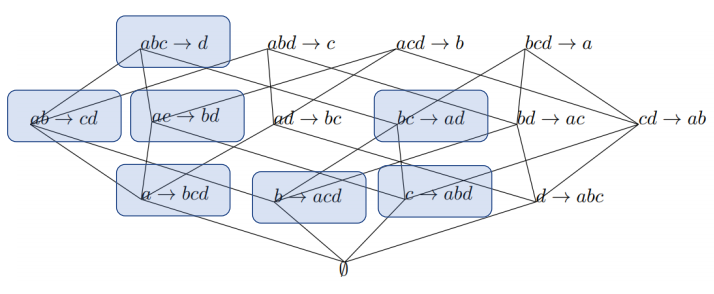
이 때, 다음과 같은 성질이 성립한다.

따라서 이전에 언급한 대로 성질을 활용하여 pruning이 가능하다. (이 때 I'1->I'2가 I1->I2를 left contain한다고 한다.)
'개인 공부' 카테고리의 다른 글
| 데이터 과학 - 12. Clustering Part 2(DBScan) (0) | 2024.04.27 |
|---|---|
| 데이터 과학 - 11. Clustering (0) | 2024.04.25 |
| 데이터 과학 - 9. Statistical Data Analysis PART 2 (0) | 2024.04.21 |
| 데이터 과학 - 9. Statistical Data Analysis PART 1 (0) | 2024.04.19 |
| 데이터 과학 - 8. Data Preprocessing Part 2 (0) | 2024.04.18 |