1. Clock synchronization
분산 시스템을 구축할 때, 각 Autonomous computing element 들은 물리적으로 격리되어있다고 가정한다.
따라서 이들은 공통된 Physical global clock을 가지는 것이 불가능하다. 따라서 분산 시스템을 구축하며 coordination의 측면에서 Clock 동기화는 필수이다.

위의 사진과 같이 output.c를 컴파일한 결과 output.o가 local clock이 달라 output.o가 먼저 만들어진 것으로 인식될 수가 있다는 것이다. 그렇다면 clock 동기화는 어떻게 하면 될까?
1. Physical clock
만약 단순히 선후 관계의 이벤트 순서만이 아니라 해당 이벤트의 정확한 발생 시간이 필요하다고 해보자.(Ex : UTC 등의 표준 단위) 그럼 2가지의 개념을 정의 가능하다.
- Precision : 두 시스템 시계간의 차이를 특정한 범위 π 안으로 유지하여야한다.

- Accuracy : 시스템 시계와 표준 시간 UTC와의 차이가 α 이하로 나야한다.

이 개념들을 기반으로 Clock drift를 정의 가능하다.
- Clock drift : Physical clock의 오차 범위. 모든 시계는 최대 Clock Drift Rate ρ 으로 정의된다. 이는 결국 해당 시계의 정확도가 1 +- ρ 만큼 빗나갈 수 있다는 것을 의미한다.

하드웨어 시계에서 발생하는 인터럽트를 이용해 HW clock, SW clock을 동기화 시킬 수 있으며, 따라서 SW clock의 drift rate도 HW clock의 drift rate을 따른다.

Clock drift가 1보다 크면 기준 시계보다 빠른 것이며 작으면 느린 것이다.
그렇다면 부정확한 시간이 어느정도인지를 어떻게 탐지하고 보정할까?
Request, Reply의 delay가 비슷함을 가정한다면 2가지의 metric을 정의 가능하다.

- Relative offset : (T2-T1)과 (T3-T4)의 평균. (두 시스템 간의 clock 차이)

- Delay : 각 서버 사이드에서 작업에 걸린 시간 (T4-T1),(T3-T2)의 평균.

=> Network Time Protocol은 8개의 (𝜃, δ) 쌍을 찾고, δ를 최소화하는 𝜃을 고른다.
* Berkeley algorithm : 기존에는 정답인 UTC time t 가 있고 이에 시계들을 맞췄다. 그러나 이것이 없을 때도 각 시계를 동기화할 필요가 있다. 이 때 사용하는 알고리즘이다.

Time daemon element를 설정하고 자신의 시간을 broadcast 한다. 그럼 그에 대한 reply로 각 element에서는 broadcast된 time daemon의 시간과 자신의 시차를 보낸다. 그럼 해당 시간의 평균을 계산하여 각 머신의 시간을 조정한다.
위의 사진에서는 3:25 -> 3:05로 시간이 역행했다. 그러나 실제로는 smooth adjustment를 적용하여 시계를 정지한 것처럼 매우 느리게 보내거나 아주 빠르게 보내 시간은 맞추어도 거꾸로는 보내지 않는다고 한다.
2. Logical clocks
지금까지는 절대 시간 t를 두고 그에 대해 정확한 시간을 맞추는 작업을 했다. 그러나 생각해보면 대부분의 일에서 꼭 절대적으로 정확한 시간 t를 맞출 필요는 없다. 그저 사건의 인과 관계를 보장해주는 순서만 지켜도 되는 logical clock을 설계해보자.
* The happened-before relationship
Ordering 규칙이 필요한 관계는 Event 간의 전후 관계가 뒤집히면 안되는 경우이다. (사칙 연산 등) 이러한 관계를 찾아내는 조건은 다음 3가지로 귀결된다.
1. 같은 프로세스 내에서 일어난 event는 순서를 매긴다.
2. Request, Reply event는 순서를 매긴다.
3. a->b, b->c의 선후관계가 있으면 a->c의 선후관계가 보장되어야한다.
그렇다면 어떻게 global view에서 일관된 happened-before 관계를 보장할 수 있을까?
- Lamport's Logical clocks
각 event에 자신의 발생 시간을 표시하는 timestamp C(e)를 찍어준다고 가정해보자. 이 때 timestamp들은 다음을 만족하여야한다.
1. a,b 가 같은 process 내의 event일 시 또는 a->b일 시, C(a)<C(b)
2. a가 message m을 보내고, b가 그 message에 대답하면, C(a)<C(b)이다.
=> 이 조건이 지켜진다면, 각 프로세스마다 logical clock을 유지하고 통신시마다 timestamp를 보고 clock 조정을 할 수 있다.
- Timestamp solution
각 프로세스는 local counter를 가진다.
1. event 발생 시마다 자신의 counter를 증가시킨다.
2. Pi가 message m을 전달할 시, 해당 message는 counter에 해당하는 timestamp를 지닌다.
3. 메시지를 받은 Pj는 timestamp를 확인하고 자신의 counter보다 값이 클 시, 자신의 counter를 해당 timestamp 값으로 바꾼다.
=> 이를 통해 Logical clock 조건 1,2 를 만족할 수 있다.
=> 만약 Counter 값이 동일한 event가 동시에 발생했다면 PID 기준으로 정리한다. (tie break)

이렇게 구현된 Lamport logical clock은 middleware에 의해 구현되고 관리된다.

* Total-ordered multicast
만약 복제된 DB가 존재 시 이들이 전부 동일한 순서로 update 해야하는 경우가 있을 수 있다.

예를 들어 P1이 100 달러를 계좌에 넣고, P2가 이자를 1% 매기는 순간, 이 사건의 인과 관계가 DB마다 다르면 많은 문제가 생긴다.
- Solution
1. Message local queue를 각 프로세스 별로 만든다. 이 message queue에는 자신이 받은 메시지와 추가로 자신이 발행한 메시지도 들어가게 된다.
2. queue는 timestamp 우선 순위 큐로 구성한다.
3. message queue에 어떤 incoming message가 들어오면 모든 다른 process에 ACK 메시지를 보낸다.
=> 1,2,3 단계로 관리되는 queue 메시지들은 다음의 기준을 만족시 처리된다.
a. local queue의 가장 앞에 있어야한다. (Timestamp가 가장 작아야한다.)
b. 해당 message가 다른 모든 process들의 timestamp보다 작다.(ACK로 확인이 가능하다.)
(Communication이 reliable하며 FIFO ordered를 가정한다.)
=>이를 통해 모든 시스템에서 가장 빠른 것이 보장되는 일만 처리한다.
- Vector logical clocks
Vector clock은 Event의 order를 정확히 보장하기 위해서 사용된다.
(Lamport clock은 사건의 순서를 보장하나, C(a)<C(b)일 때 a가 b보다 인과적으로 관계가 있다는 것을 보장하지 못한다.
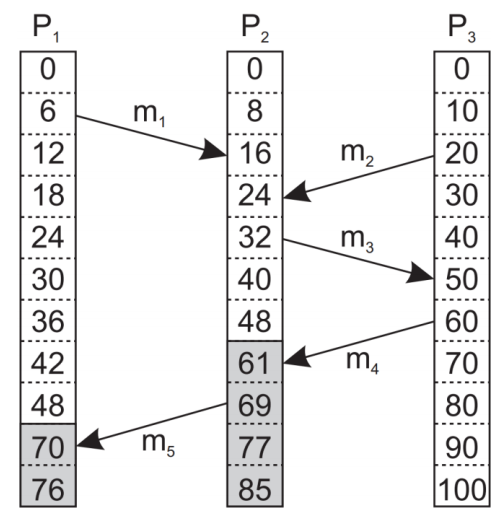
예를 들어 m1이 T 16에 P2에게 수신되었다. m2는 T 20에 송신, T 24에 수신되었다. 그렇다면 m1을 발생시킨 event a와 m2를 발생시킨 event b가 인과적으로 관계가 있다고 볼 수 있을까?
P1,P3의 아예 다른 프로세스에서 발생한 이벤트들에 대한 message이기에 답은 아니다 이다.
시간 정보만 가지고는 m1, m2가 서로 연관이 된 event인지 (ex : Request, reply), 별개의 이벤트인지 알 수 없다.
* Causal dependency
다음 조건을 만족할 때 b가 a에 인과적으로 관계가 있을 수도 있다고 간주한다.
1.

2.

=> a가 b의 precedence일 시 a는 b에 영향을 미친다. b가 a에 depend하면 a의 정보가 b에게 전파된다고 볼 수 있다.
* Capturing causality
각 프로세스는 각자 Vector counter를 유지한다고 가정하자. 이 때 VCi[j] = k 라면 Process i가 수신한 Pj의 이벤트 발생 갯수가 k개라는 뜻이다. 이 가정 하에 다음의 규칙을 지킨다.
1. Pi가 이벤트를 처리할 때마다 자신의 벡터 시계의 인덱스를 증가시킨다.
2. 메시지 전송 시 자신의 Vector clock 값을 timestamp로 쓴다.
3. 메시지 수신 시 ts(m)[k]를 확인하고, 자신의 VCi[j] 값보다 클 시 업데이트한다. 이후 자신이 메시지를 수신했으므로 자신 VC 값을 증가시킨다.

이렇게 유지되는 VC를 보면 인과관계의 가능성을 예측할 수 있다. 모든 Vector counter 값이 일정한 대소 관계를 가질 경우 인과관계의 가능성이 있는 것이다. ts(m2) = (2,1,0), ts(m4) = (4,3,0) 이므로 P3 시점에서 m2, m4는 인과관계가 있을 수 있다.
* Causally ordered multicasting
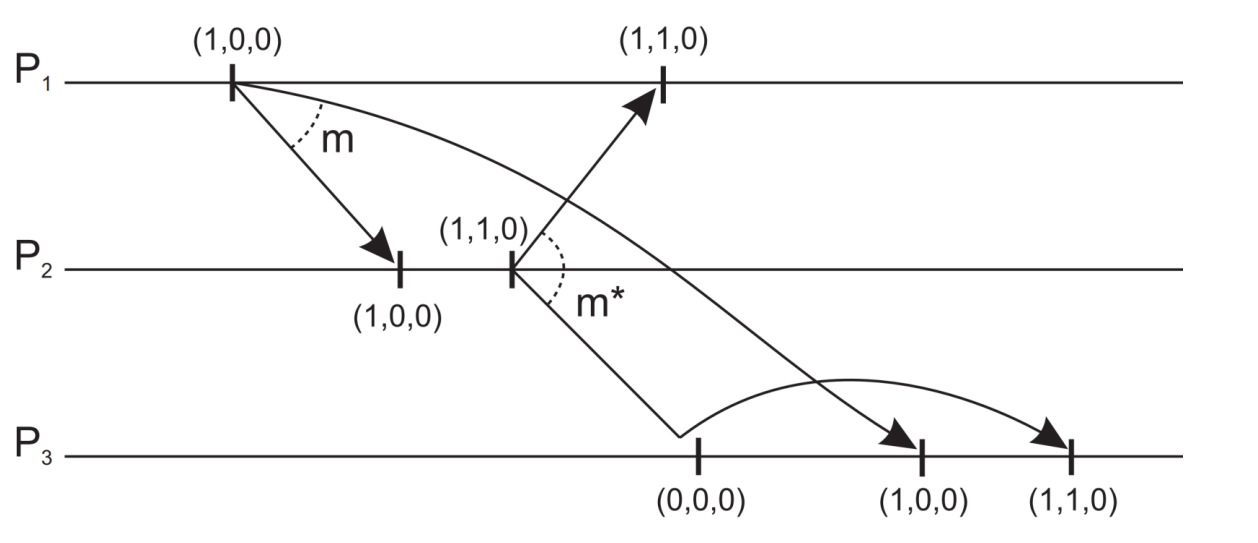
Multicasting된 메세지들이 인과 관계를 따르도록 보장해야한다. 예를 들어 P1이 m1을 보낸 후 m1의 영향으로 P2가 m2를 보낸다면 모든 프로세스에 대해 반드시 m1이 먼저 처리되어야한다. 따라서 2가지 조건을 만족할 때까지 전송을 지연시킨다.
1.

2.
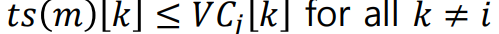
2. Mutal exclusion
이전까지 clock synchronous의 측면에서 physical, logical할 때 어떻게 동기화를 시킬 것이냐에 대해 알아보았다.
그러나 분산시스템에서는 공유 자원에 대한 접근 문제가 여전히 남이있고 일관성을 위해 이를 안전하게 처리할 필요가 있다.
자원 접근 관리법의 기본적인 방법으로는 2가지가 있다.
1. Permission-based : process가 critical section이나 resource access를 하고 싶다면, 다른 process들에게 permission을 받아야한다.
2. Token-based : process들 사이에 token이 전달된다. token을 가진 자는 critical section이나 자원에 접근이 자유롭다. 사용을 마치면 token을 패스한다.
* Centralized algorithm

가장 심플한 방법 중 하나는 중앙화된 Coordinator에게 책임을 일임하는 것이다. Coordinator는 본인의 Queue에 자원 요청 순서를 저장하며, 한정된 자원을 요청 순서대로 할당해준다.
* Decentralized algorithm
Decentralized 방법으로 구현하면, 각 자원에 대한 여러 개의 복제본을 만들고, 각 복제본에 자체 coordinator를 활용하는 방법도 있다. 만약 자원이 N개가 복제되었다면 N/2 이상의 coordinator들에게 OK 싸인을 받아야 자원에 접근하는 방법으로 구현한다. 이 경우 분산된 만큼 coordinator가 반응이 빨라지며, 멈춰도 빠르게 회복이 가능하다 (한 coordinator가 작동을 멈춰도 여전히 다수결로 돌아가기 때문에 시스템이 작동한다.) 그러나 자신이 승인해줬던 기록은 여전히 사라지게 된다. 단점으로는 요청이 분산되기 때문에 네트워크 부하가 증가하고 과반수 응답을 기다려야한다.
* Distributed algorithm : Ricart & Agrawala (Permission-based)

이 방식은 Lamport logical clock과 유사하나, 각 수신 메시지에 대해 ACK을 전송하지 않는다.
각 프로세스는 자원에 접근하기 위해 다른 모든 프로세스들에게 자원 접근 요청을 보낸다. 자원 접근 요청을 받은 프로세스 는 자신이 해당 자원에 관심이 없거나, 자신의 timestamp 값이 더 느릴 경우 이 요청에 답장을 한다.
* Distributed algorithm : A token-ring algorithm (Token-based)

프로세스들을 logical ring으로 구성하고, 토큰을 순서대로 순환시켜 접근 권한을 관리한다. 자신의 다음 process에게만 소통이 가능하다.(Linked chain)

중앙화된 방법일 수록 메세지 교환이 적고 network burden이 적다. 그러나 single point failure 문제의 리스크가 커진다.
3. Election
이전에 살펴본 coordinator를 이용하는 방법에서 coordinator는 누가 되어야하는 것일까? 많은 시스템에서 coordinator는 수동적으로 하나를 고르게 구성된다. 이는 필연적으로 single point failure가 발생하게 된다. (시스템의 자체 failure 대처 불가능)
다음의 가정을 하고 알고리즘을 살펴보자.
1. 모든 프로세스들은 unique id를 가진다.
2. 모든 프로세스들은 서로의 id를 전부 알고 있으나, 해당 process가 현재 활성화되어있는지 여부는 모른다.
3. Election의 목적은 현재 활성 상태인 프로세스 중 가장 높은 PID를 가진 프로세스를 코디네이터로 선출하는 것이다.
* Election by bulling

bully 알고리즘은 프로세스가 기존 coordinator에 장애가 생겼다는 것을 인지하면 시작된다. 장애 발생 사실을 인지한 프로세스 Pk는 자신보다 PID가 높은 프로세스들에게 ELECTION 메시지를 날린다. Pk의 메세지에 아무도 응답하지 않으면 Pk가 coordinator가 된다. 응답할 시 응답한 프로세스가 election을 이어받는다.
* Election in a ring

프로세스들을 링으로 구성하여 링 구조에서 가장 prioirty가 높은 프로세스를 Coordinator로 선정한다.
1. Coordinator의 장애를 확인한 프로세스로부터 다음 프로세스로 Election 메시지를 시작한다.
2. 메시지를 받은 프로세스는 자신의 ID를 추가하고 다음 프로세스로 순환시킨다.
3. 한 바퀴를 돌고 현재 활성화 되어있는 모든 활성 프로세스의 명단을 받은 시작 프로세스는 명단을 확인해 가장 높은 우선순위의 프로세스를 선출한다.
* Election in wireless environments

무선 환경에서는 노드의 capacity를 우선순위로 두고 Coordinator를 선출해야한다.
따라서 다음의 절차대로 수행된다.




'개인 공부' 카테고리의 다른 글
| Distributed System - 8. Fault Tolerance (0) | 2024.12.04 |
|---|---|
| Distributed System - 7. Consistency & Replication (0) | 2024.12.02 |
| Distributed System - 5. Naming (0) | 2024.10.23 |
| Distributed System - 4. Communication (0) | 2024.10.20 |
| Distributed System - 3. Processes (0) | 2024.10.07 |