1. Reasons for replication
복제(Replication)이란 데이터를 여러 복제본(replica)로 분산하여 저장하는 것을 의미한다.
복제를 함으로써 얻을 수 있는 효과는 크게 2가지가 있다.
1. 성능 : 동일한 데이터에 대해 여러 클라이언트가 동시에 요청을 처리할 수 있어 성능이 향상된다.
2. 확장성(Scalability) : replica를 추가함으로써 시스템의 capacity를 확장할 수 있다. (Task 분산)
그러나 복제를 하면 자연스럽게 따라오는 문제가 있는데, 바로 replica 끼리의 consistency 문제이다.
replicas consistent를 지키기 위해서, Write 작업과 다른 작업이 동시에 일어날 때 처리를 해줄 규칙이 필수가 된다는 것이다.
1. Read-Write Conflict : 읽기 작업과 쓰기 작업이 동시에 발생할 때.
2. Write-Write Conflict : 쓰기 작업이 동시에 발생할 때
=> 충돌하는 작업들이 모든 replica에서 동일한 순서로 처리되어야 consistency를 유지할 수 있게 된다.
그러나 이 Global order를 보장하는 것은 매우 부담이 되는 작업이다. (Global 단위에서 동기화 문제는 오버헤드도 매우 크고 복잡도도 높다.)
=> 따라서 Weaken consistency requirements를 사용하여 동기화의 부담을 줄이는 방법으로 접근할 수 있다. (즉시 동일한 상태로 유지가 아니더라도 시간이 지나며 결국 consistency가 유지됨을 보장.) 즉, consistency model을 나누어서 관리하자.
2. Data-centric consistency models

Consistency model은 분산 데이터 저장소와 이를 사용하는 프로세스들 간의 계약이다. 즉, DB는 여러 replica가 분산된 상태에서 concurrency가 존재할 때, 데이터의 Read, Write task가 어떻게 동작해야하는지를 정의한다.
* Continuous consistency
그렇다면 model을 지정하기 전에 어느정도의 consistency를 유지할지를 정의해보자.
1. replica들은 서로 다른 numerical value를 가질 수 있다.
2. replica들은 Data의 업데이트 정도가 다를 수 있다.
3. replica들이 처리한 업데이트 작업의 개수와 순서가 다를 수 있다.
=> Consistency Unit(Conit)은 일관성을 측정하는 데이터 단위이다.
* Consistent ordering of operations
- Sequential consistency : 모든 프로세스 간에 동일한 연산 순서를 보장하는 것을 목표로 한다.

a의 경우 Sequential consistency를 지키는 model이다. P1이 변수 x에 a를 쓰고, P2가 x에 b를 쓴 뒤, P3와 P4가 b를 읽고, a를 읽는다.
b의 경우 Sequential consistency를 지키지 않는 경우이며, P3, P4가 읽는 순서가 같지 않은 점을 볼 수 있다. (읽기/쓰기 결과에 Consistency가 없다.)
- Causal consistency : 인과적으로 관련된 write 연산을 모든 프로세스에서 동일한 순서로 보여준다. (동시에 이루어지는 write 연산은 달라도 된다.)

a의 경우 x에 a를 쓴 후, P2가 이를 확인하고(R(x)a) x에 b를 썻으므로 W(x)a, W(x)b 사이에 인과관계가 있다. 그러나 P3는 b를 먼저 읽고 a를 이후에 읽었다. 즉, Causal consistency를 지키지 않았다.
b의 경우는 W(x)a, W(x)b가 인과관계가 없어 동시에 이루어진 작업으로 본다. 따라서 어떻게 읽든 관계가 없다.
3. Client-centric consistency models
* Consistency for mobile users
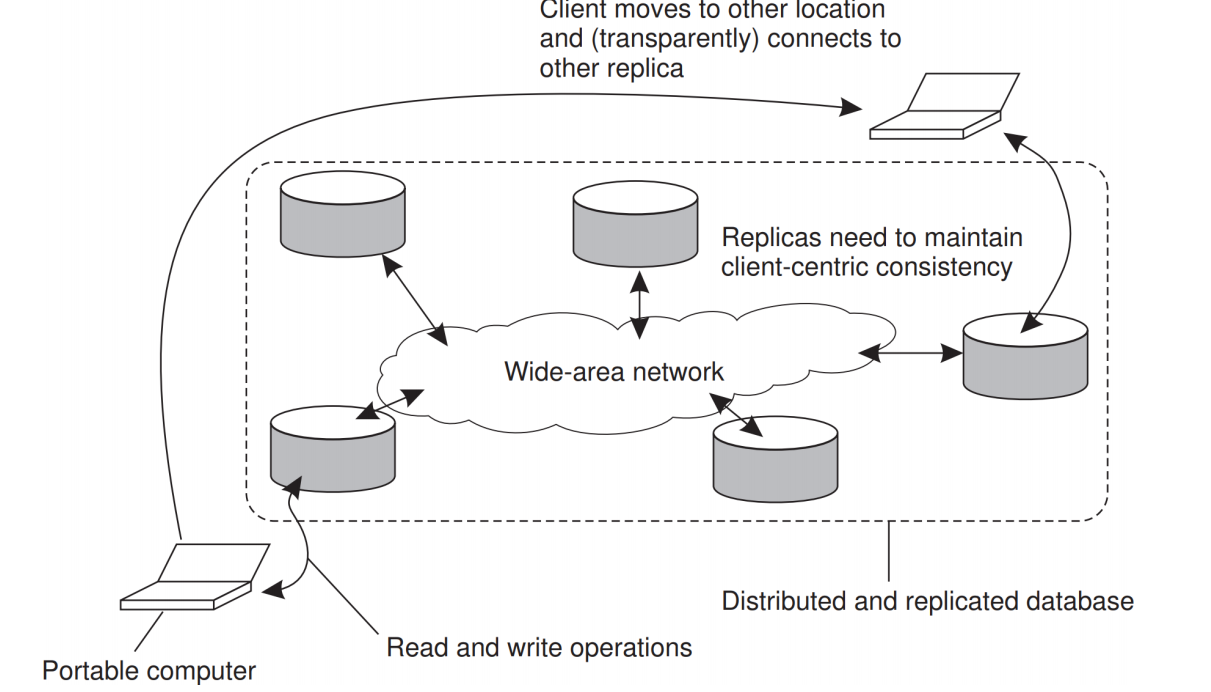
분산 DB를 사용하며 노트북이 DB에 대한 프론트앤드 역할을 한다고 가정하자.
만약 location A이서 read, update 작업을 수행하고, location B로 이동해 작업을 계속한다 할 때, 기존에 접속했던 서버와 접속 서버가 달라지는 경우가 발생이 가능하다. 이 경우 다음의 inconsistency가 발생 가능하다.
1. A에서 수행된 업데이트가 B에 아직 전파되지 않았다.
2. B에서 읽는 데이터가 A에서 사용하던 데이터보다 더 최신 것이다.
3. B에서 수행한 업데이트가 A의 데이터와 충돌할 수 있다.
이동성이 있는 환경에서 목표는 A에서 업데이트하거나 읽은 항목이 A에 남긴 방식대로 B에도 있는 것이다.
=> Monotonic reads : 어떤 프로세스가 x의 값을 읽으면, 이후 해당 프로세스가 x에 대해 수행하는 모든 read 작업은 항상 동일한 값 또는 더 최근의 값을 반환한다.
(ex : 서로 다른 서버에서 개인 캘린더 업데이트를 자동으로 읽는 경우, monotonic reads는 사용자가 어떤 서버에서 read를 실행하더라도 모든 업데이트를 볼 수 있도록 보장, 이동 중에 이메일을 읽는 경우, 다른 이메일 서버에 연결할 때마다 해당 서버는 이전에 방문했던 서버에서 가져온 모든 업데이트를 제공한다.)
* Monotonic reads notation
W1(x2) : 프로세스 P1에 x version 2를 write
W1(xi;xj) : 프로세스 P1이 이전 버전 xi를 기반으로 xj를 생성했음을 나타낸다. (xi와 xj가 연관된 작업 결과이다.)
W1(xi|xj) : 프로세스 P1이 xi와 동시에 xj를 생성했음을 의미한다.

사진은 단일 프로세스가 2개의 같은 데이터에 대한 복사본에 작업을 하는 것을 가정한다.
a에서 각 로컬 자원은 x1 write 이후 x2를 write 했다. 이 때 P1은 x1을 읽은 후 x2를 읽기 때문에 이전에 본 버전보다 이전 버전을 확인하지 않았다.
b에서는 x1이 작성된 후 x1,x2가 동시에 작성된다. 이 때 데이터간 순서와 의존성이 존재하지 않으므로 x1, x2 관계가 monotonic 하지 않아 관계가 깨지게 된다.
=>Monotonic writes : 동일한 프로세스에 의해 x에 수행되는 write task는 이후에 수행될 write task 이전에 반드시 완료되어야한다. 즉, 이전 버전이 모든 서버에 전파되기 이전에는 새로운 버전의 작성을 막는다.
(ex : 프로그램을 서버 S2에서 업데이트 할 때, 컴파일과 링크 작업에 필요한 모든 구성 요소도 S2에 준비되도록 보장하는 것, 복제된 파일의 버전을 모든 서버에서 올바른 순서로 유지하는 것.)

a의 경우에는 x1 -> x2 -> x3 순서대로 관계를 이루며 write 되었으므로 monotonic write이 보장되었다.
b의 경우에는 P1에서 x1을 write하고 이어 P2에서 x1에 독립적으로 x2를 write한다. 이 때, P1이 x1에 독립적으로 x3를 작성한다. 이는 순서와 의존성이 존재하지 않으며 Monotonic write을 보장하지 않는다.
c의 경우에는 P1에서 x1을 write하고 P2에서 x1에 독립적으로 x2를 write한다. 이후 P1에서 x2에 의존하여 x3를 작성하는데, (x1->x2)->x3 가 괄호의 구간에서 보장되지 않으므로 monotonic write을 보장하지 않는다.
d의 경우에는 P1이 x1을 write하고 x1와 독립적으로 x2가 쓰인다. 그리고 P1이 x1과 관련되어 x3를 작성한다. x1->x3는 인과관계가 성립한다. x1이 일부 x2에 의해 덮어씌워졌어도 일관성을 보장한다고 할 수 있다.
* Read your writes : 어떤 프로세스가 데이터 항목 x에 대해 수행한 write 결과는, 동일한 프로세스가 이후 x에 대해 수행하는 read에서 반드시 반영되어야 한다. 즉, 내가 상호작용한 결과는 다음 확인 때 반드시 반영이 되어있어야한다는 것이다.

a의 경우 P1의 x1의 작성이 완료 후, P2가 x1에 의해 x2에 반영한다.(causality) 따라서 P1이 x2를 읽게 된다.
b의 경우 P1의 x1 작성이 완료 후, P2가 x1과 무관한 x2 작업을 write한다. P1이 읽는 x2는 P1의 write 작업 x1과 무관할 수 있다.
* Write follow reads : 특정 프로세스가 x를 읽은 후 write을 수행하는 경우, 그 write은 read에서 참조했던 동일한 데이터 버전이나 더 최신 버전을 기반으로 실행됨을 보장한다.
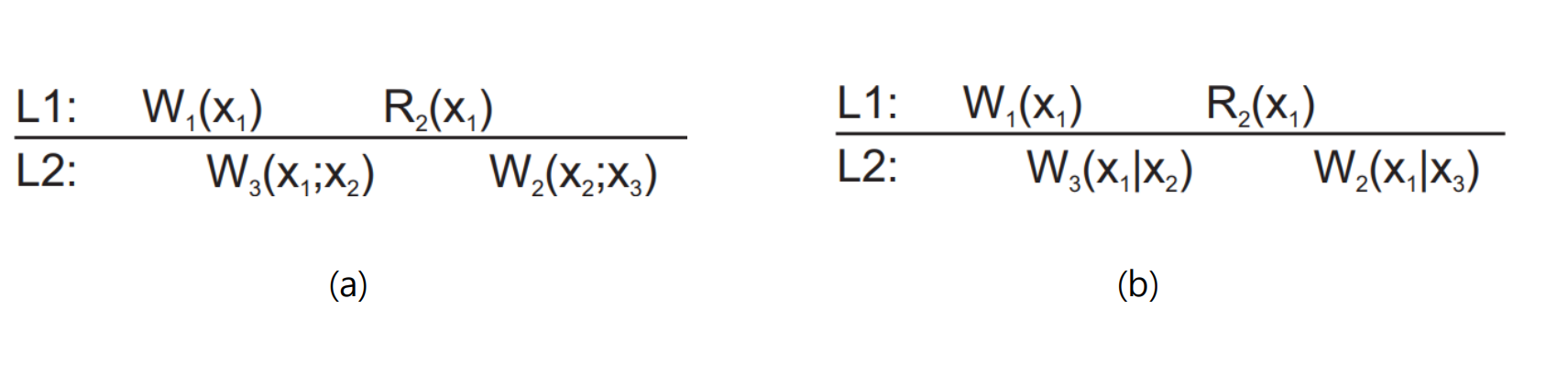
a는 x1을 작성한 후 x1->x2의 관계가 성립한다. 따라서 P2가 x2에 쓰기 작업을 할 때 해당 x2는 read한 x1 보다 최신 버전이다.
b는 x1와 x2가 독립이다. 따라서 W2(x2;x3)에서 x2가 이전에 read한 x1의 최신 버전인지 알 수 없다.
(만약 W2(x1|x3)로 보더라도 Writes follow reads가 성립하지 않는 것은 맞다. P2는 x1을 읽었고, x1은 P3에 의해 무관한 x2로 덮어 씌워졌다. 즉, x의 최신 상태는 x2가 되고, P2가 x1에 write을 실행하는 것은 규칙을 어긴다.)
*정리
Monotonic reads : 동일한 프로세스에서 항상 이전 read에 비해 최신 것을 read해야한다.
Monotonic writes : 동일한 프로세스에서 수행되는 write은 이전 write이 반영된 뒤에 되어야한다.
Read your writes : 동일한 프로세스에서 수행한 write은 이후 read에 무조건 반영되어야한다.
Writes follow reads : 동일한 프로세스에서 수행할 write은 이전에 read해둔 내용과 동등하거나 최신이어야한다.
4. Replica management
* Content replication : replica를 호스팅하는 방식에 따라 3가지로 구분할 수 있다.
1. Permanent Replicas : 항상 복제본을 유지하는 프로세스 혹은 머신 (ex: DB server)
2. Sever-initiated replica : 특정 서버의 요청에 따라 동적으로 복제본을 생성 및 호스팅하는 프로세스
3. Client-initiated replica : 클라이언트 요청에 따라 동적으로 복제본을 생성 및 호스팅 하는 프로세스
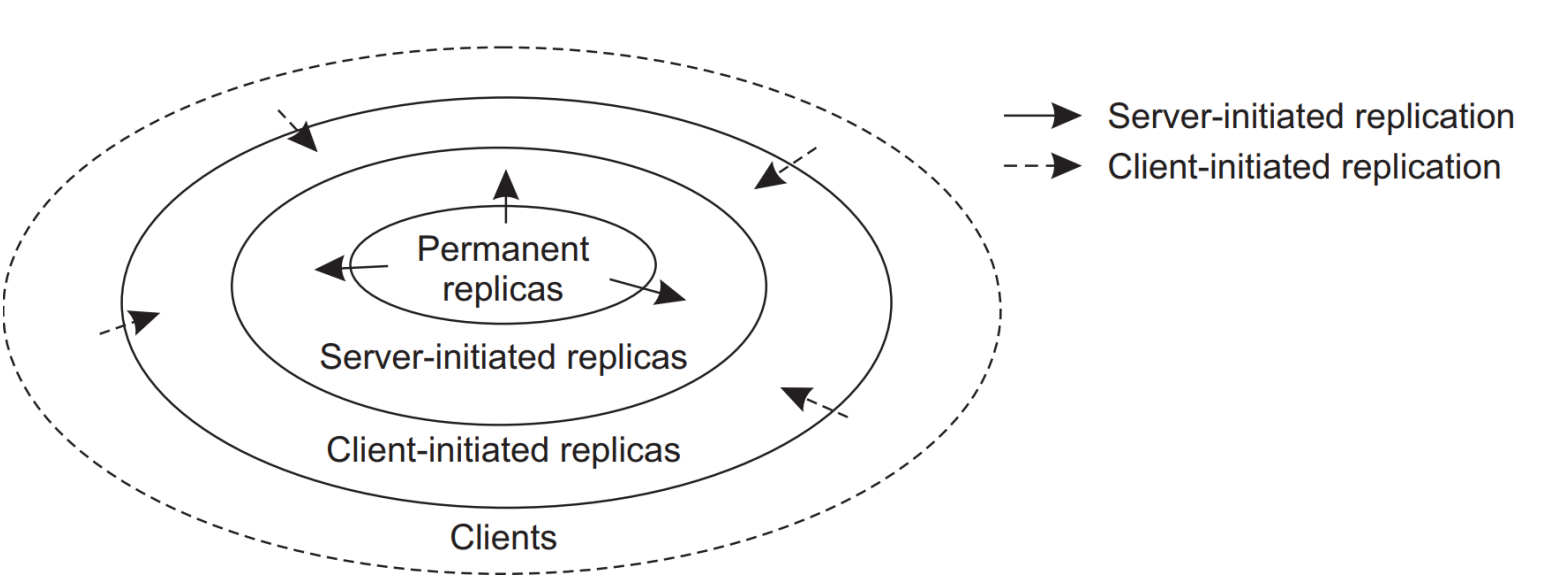
(Permanent Replica는 생략)
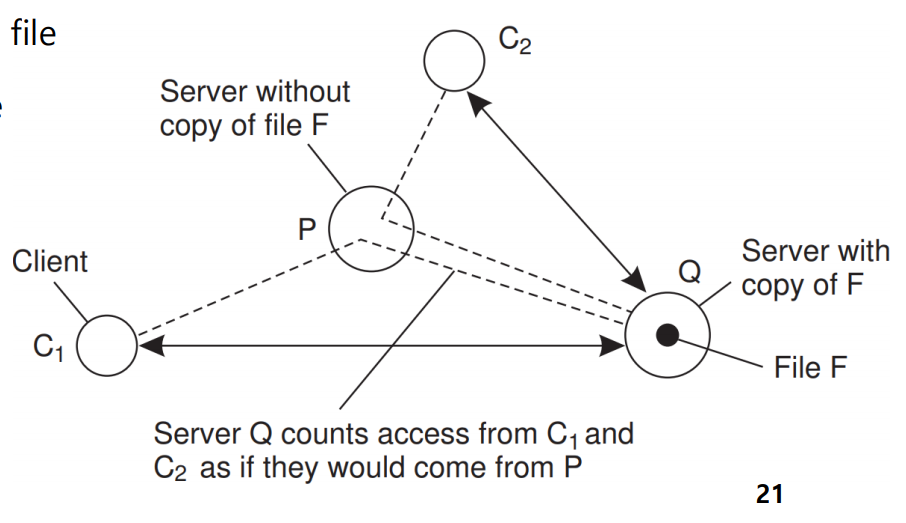
서버는 각 클라이언트들에 대한 access request들을 카운팅한다. (client의 요청이 들어온 가장 가까운 서버에 의해 집계된다.)
파일 당 access count를 유지하며 이를 집계하여 많거나 적은 경우에 따라 행동을 취한다.
1. 요청이 너무 적어 threshold D 아래로 떨어질 경우 -> drop file
2. 요청이 과도해 threshold R 이상 올라갈 경우 -> replicate file
3. 요청이 D,R 사이일 경우 -> migrate file (요청 지점과 가장 가까운 서버로 파일을 옮김)
=> 이렇게 결정이 이루어지면 Replica들 간 업데이트를 전파해야한다.
* Update 전파 방식
- 범위
1. 데이터 업데이트가 발생하면 변경 사항에 대한 알림 또는 무효화 메시지만 전송한다. (주로 캐시에 사용된다.)
2. 업데이트된 데이터를 Replica간 직접 전송한다. (Passive replication, 주로 분산 데이터 베이스에서 사용)
3. 업데이트 작업 자체를 전파한다. (Active replication)
=> 항상 최고의 approach는 없으며, 네트워크의 가용 대역폭, 읽기 쓰기 비율을 고려해서 결정해야한다.
네트워크 대역폭이 충분하면 2번이 최고이다. 부족할 시 1,3 을 선택해야하나 3은 client에 부담이 된다. 또한 읽기 쓰기가 자주 일어나는 환경이면 1번이 최적이다.
- 타이밍

1. Push-based protocol : 서버가 클라이언트의 요청 여부와 관계 없이 업데이트 자동 전파. (Server-initiated)
2. Pull-based protocol : 클라이언트가 요청한 경우에만 데이터 동기화. (Client-initiated)
=> Push-based는 서버에서 client cache들의 리스트를 가지고 있어야하며, 업데이트를 하기 전에 의견 교환 절차가 필요 없다. 또한 업데이트를 결정하면 즉각 client에 반영된다.
=> Pull-based는 서버에서 따로 유지할 client 정보가 없으며, 업데이트 이전에 의견 교환 메시지 절차가 필요하다. 또한 업데이트가 있어도 이를 Fetch 결정하기 이전까지는 반영되지 않는다.
- Leases : 서버가 클라이언트에 특정 시간 동안 데이터를 업데이트할 것을 보장하는 것.
=> Lease 유효 기간 동안 서버는 클라이언트에게 업데이트를 Push 방식으로 전파.
=> Lease 만료 시 Pull 방식으로 전환
- Adaptive Leases : lease 기간을 동적으로 결정하는 법. 주로 3 가지로 나뉜다.
1. Age-based leases : 데이터 객체가 오랫동안 변경되지 않은 경우, 가까운 미래에도 변경될 가능성이 낮다고 판단. 더 짧은 Lease 부여.
2. Renewal-frequency based leases : 특정 객체에 대한 클라이언트 요청 빈도가 높을 수록 더 긴 Lease 기간 부여.
3. State-based leases : 서버 상태(부하)에 따라 Lease 기간이 조정된다. (서버 부하가 높을 수록 짧게 설정)
5. Consistency protocols
* Continuous consistency의 3가지 형태
1. Bounding numerical deviations : 데이터 복제본 간 값의 수치적 차이를 제한
2. Bounding staleness deviations : 복제본이 최신 데이터와 얼마나 시간적으로 거리가 있는지를 제한
3. Bounding ordering deviations : 데이터 작업(R/W)이 복제본에서 발생하는 순서의 편차를 제한한다. (작업의 순서)
- Sequential consistency : 모든 작업이 전역적으로 동일한 순서로 처리됨을 보장.(Bounding ordering deviations)
1. Primary-based protocols : Primary-backup protocol
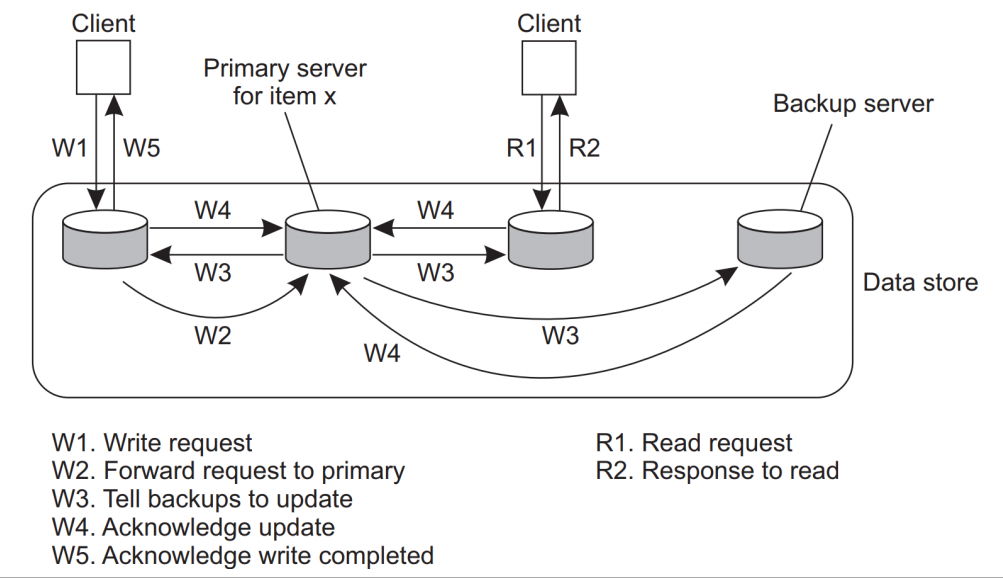
이 프로토콜은 Primary-backup protocol 로써 하나의 Primary Server와 여러 Backup Server들을 이용하여 데이터를 관리한다. 이 프로토콜을 취함으로써 Backup server 들에도 데이터가 존재하므로 높은 Fault Tolerance를 가질 수 있다.
W1. Write Request : 클라이언트가 server에 write 요청을 보낸다.
W2. Forward request to primary : Backup server들은 해당 요청을 Primary server에 전송한다.
W3. Tell backups to update : Primary Server는 해당 요청을 검토 후 backup server에게 update를 broadcast한다.
W4. Acknowledge update : 각 backup server는 update 후 완료를 Primary server에게 알린다.
W5. Acknowledge Write Completed : Primary server는 작업이 완료됨을 요청자에게 알린다.
R1., R2 : Read 작업은 backup에서 직접 처리한다.
2. Primary-based protocols : Primary-backup protocol with local writes
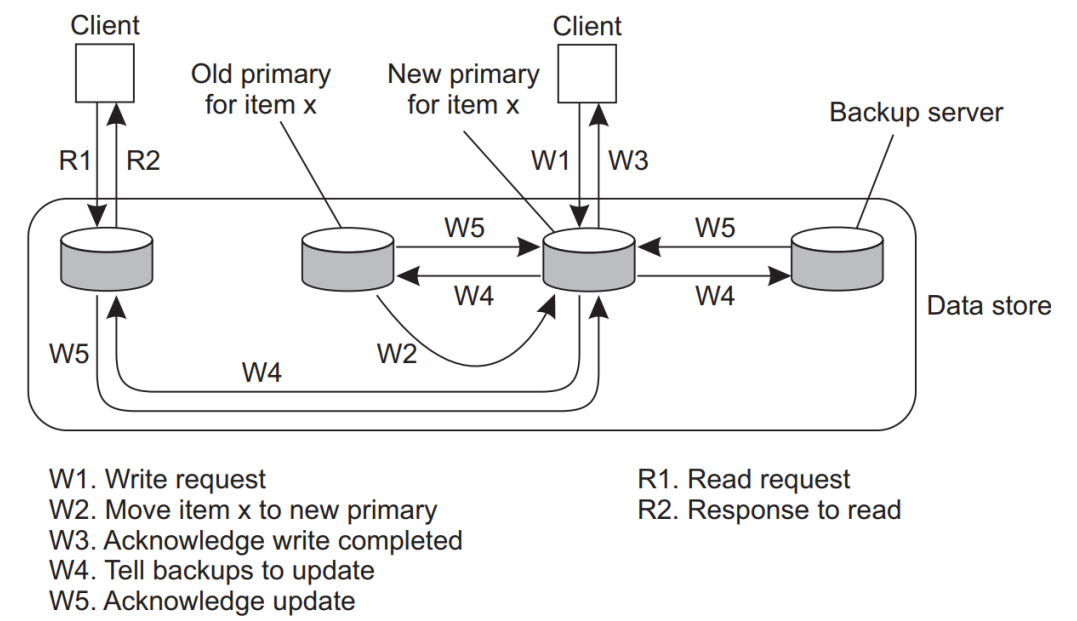
이동성을 가정한 상황에서는 클라이언트가 네트워크 연결이 끊어지는 것도 가정을 해야한다. 따라서 이 프로토콜은 기존의 Primary-backup 구조에 local write 기능을 추가한다. 연결이 끊어지기 전에 관련 파일 전부를 user에게 전송한다. 이후에 업데이트를 한다.
W1. Write request : Server로 데이터 쓰기 요청
W2. Move item x to new primary : 기존 Primary server는 요청받은 데이터를 새로운 Primary server로 이전시킨다.
W3. Acknowledge write completed : 새로운 Primary는 Write 작업 완료를 알린다.
W4. Tell backups to update : 클라이언트가 재연결되면 업데이트를 Backup server들에게 전파한다.
W5. Acknowledge update : 모든 Backup server가 동기화를 완료한 후 완료 신호를 보낸다.
R1. & R2 : 클라이언트가 데이터를 읽으려고 할 때는 자체적으로 처리한다.
* Quorum-based protocols
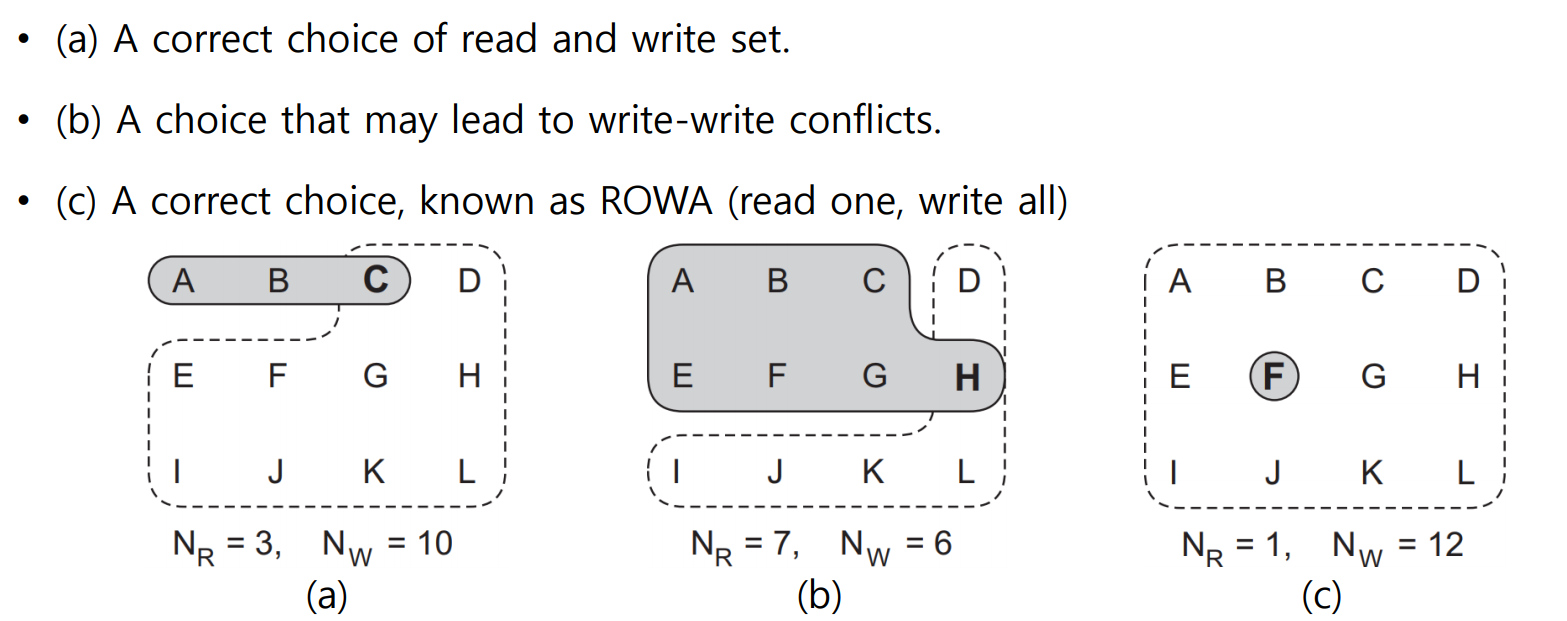
데이터를 읽거나 쓸 때, 특정 수의 서버(Quorum)에서 승인을 받아 작업을 수행하여 데이터 일관성을 보장하는 프로토콜.
적절한 NR(읽기 집합), NW(쓰기 집합)을 선택한다. (NR+NW > N, NW>N/2)
a) NR = 3, NW = 10, N = 12 : 적당한 크기
b) NR = 7, NW = 6 , N = 12 : 읽기 집합이 많다. write-write confilct 발생 가능.
c) NR = 1, NW = 12, N = 12 : ROWA(read one, write all)로 알려져있으며 단순하고 높은 일관성을 보장한다.
(* 각 알파벳은 같은 데이터의 복제본을 보유한 것을 의미한다.)
'개인 공부' 카테고리의 다른 글
| Distributed System - 9. Distributed Training (0) | 2024.12.05 |
|---|---|
| Distributed System - 8. Fault Tolerance (0) | 2024.12.04 |
| Distributed System - 6. Coordination (0) | 2024.12.02 |
| Distributed System - 5. Naming (0) | 2024.10.23 |
| Distributed System - 4. Communication (0) | 2024.10.20 |