1. Motivation
최근에는 분산 컴퓨팅의 활용 도메인에 AI를 위한 HPC 기능을 제공하는 것이 추가되고 있다.

그 이유에는 Transformer의 등장 이후 가속화된 모델 크기 비대화가 큰 지분을 차지한다.
모델을 사용한단 것은 크게 Training - Inference의 단계가 존재하게 되는데, Training의 단계에서 리소스 요구량은 단일 노드가 감당하기에는 불가능에 가까워지는 것이 현실이다. GPT-3 175B는 A100 기준으로도 단일로 3100000의 비현실적인 시간이 소요되는 것을 확인할 수 있다.
* Data parallelism
따라서 결국에는 여러 GPU가 학습을 병렬적으로 처리하게 된다. 이 병렬 방법중 Data parallelism이란 데이터 자체를 분할하여 각 GPU에게 할당하는 것이다. 즉, GPU가 연산 필요량을 분담하는 것이다. (Data split)
* Model parallelism
두번째는 model parallelism이다. 각 GPU가 모델의 특정 layer를 맡아서 학습을 맡는 것이다. 이는 모델의 단계를 쪼개 특정 단계를 맡는 것이다. (Model split)
* Tensor parallelism
Tensor란 모델의 중간 단계의 결과나 Matrix 등 데이터 양식의 일종이 될 것이다. 즉, 한 layer의 각 학습을 나누어 맡는 것이다. 이전에 살펴본 (n, k) MDS code와 비슷하게 데이터 하나를 쪼개서 나누어 학습을 하는 것이다.
즉, 각 activation function을 쪼개서 계산하고 합치고를 반복하는 것이다.
* Parallelism in distributed training
이렇게 Data, Model, Tensor parallelism을 살펴보았다. 이들의 특징을 정리해보자.
1. Data Parallelism
=> Data 들을 N개로 분할해 model에게 배치한다.
=> 같은 모델이 GPU들에게 복사하여 배치된다.
=> 병렬화가 쉽고 utilization이 좋다. (Model parallelism의 경우에는 중간 layer에서 Straggler effect와 같이 결과를 내지 못하면 아예 결과 출력 x)
2. Model parallelism
=> Model을 분할한다.
=> 모든 GPU가 모여 한 모델을 만든다. 즉 모든 GPU가 같은 모델이다.
=> 병렬화가 어렵고, Utilization이 낮다.
=> load balancing issue가 있다. (모델을 어떻게 split하냐에 따라서 각 GPU마다 연산량이 다르다.)
3. Data Parallelism
* Infrastructure overview
Data parallelism을 구현하기 위해서는 Parameter server 하나, Worker nodes를 준비한다. (앞에서 본 Master, Worker 노드와 비슷하다.)
Parameter Server : worker의 gradients를 모아 결과를 집계하고 다시 전송해준다.
Worker : Split된 dataset을 기반으로 gradients를 계산해서 paramter server에 전달해준다.
Parameter Server가 Neural Network Model 역할을 한다.
1. Param. Server에서 전체 모델을 복사해서 Worker 노드들에게 뿌려준다. (Local replica NN Model)
2. Training Dataset을 랜덤하게 섞어서 균일하게 split 하여 분할 분배한다.
3. 각 Worker들은 해당 data 를 Local replica model에 통과시켜 Local gradients를 계산한다.
4. 해당 값들을 Worker node들은 Param. server에 전달한다.
5. Param. server는 결과로 도달한 gradient들을 집계한다.
=> Centralized 된 방식은 항상 Single point failure 문제가 따라온다. 또한 Worker의 수가 증가하면 Param. Server에 걸리는 부하가 과도해진다. (Communication bottleneck) 따라서 거대모델을 로드하기 위해 많은 GPU를 사용하게 되면 자연스래 이러한 문제에 직면하게 된다.
=> Parameter를 직접 쓰지 않고 decentralized approach를 하면 어떨까?
* Distributed communication
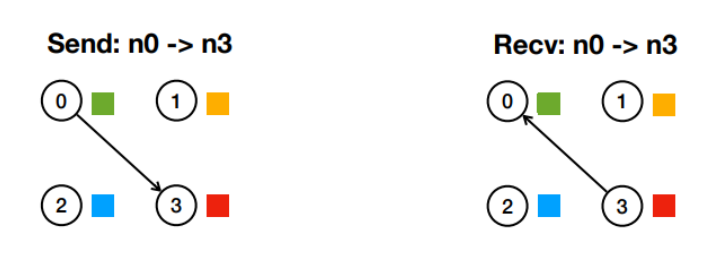
1. Point-to-point (one-to-one) communication : 1. Send : 특정 노드에게 데이터를 보낸다. 2. Recv : 그 노드에서 결과를 받는다.
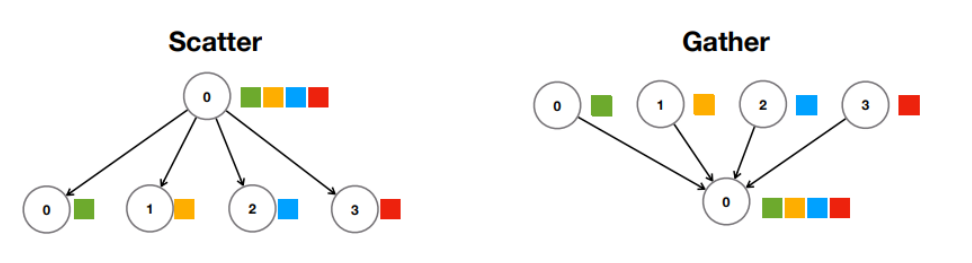
2. Collective (one-to-many) communication : 1. Scatter : 데이터를 쪼개 뿌린다. 2. Gather : 뿌린 데이터 연산 결과를 모은다.
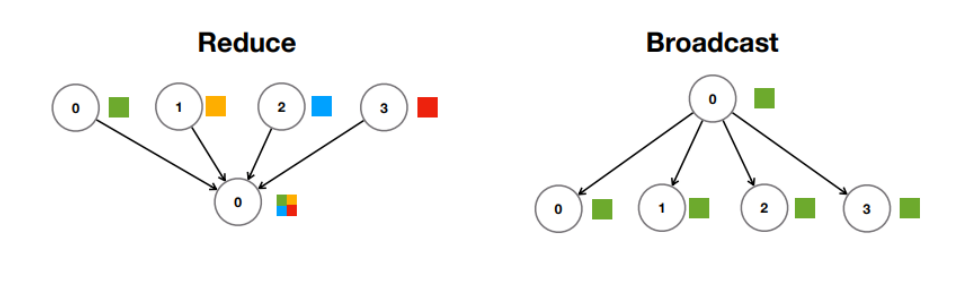
3. Reduce : gather와 비슷하지만 결과 값을 별도로 받아 정리하는 것이 아니라 받으면서 집계 작업을 처리한다.
(Gather에 비해 bottleneck 측면에서 이점이 있다.)
4. Broadcast : 모든 노드에게 같은 데이터 replica를 전달한다. (Param. server가 모델을 배포할 때)
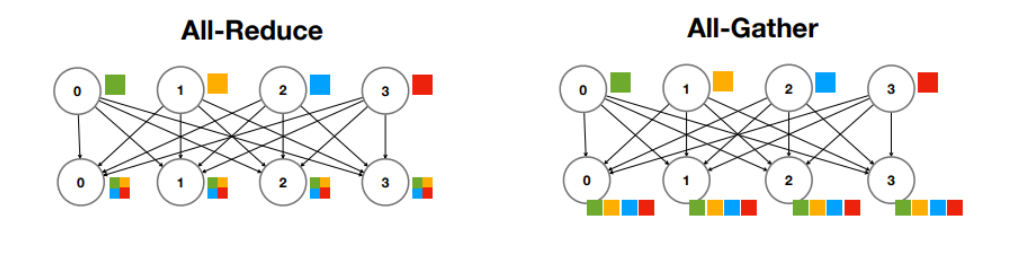
3. Many-to-many communication : 1. All-Reduce : 모든 Worker에 대해서 동시에 Reduce.(동시 전달을 위한 bandwidth 필요), 2. All-Gather : 동시에 Gather를 한다.
=> Param Server가 모델을 배포할 때 : Broadcast
=> Param Server가 결과 gradient를 집계할 때 : Reduce
=> Bandwidth requirements(N : Number of training workers) : Worker( O(1) ), Param Server( O(N) )
* Naïve All-Reduce implementation: Sequential
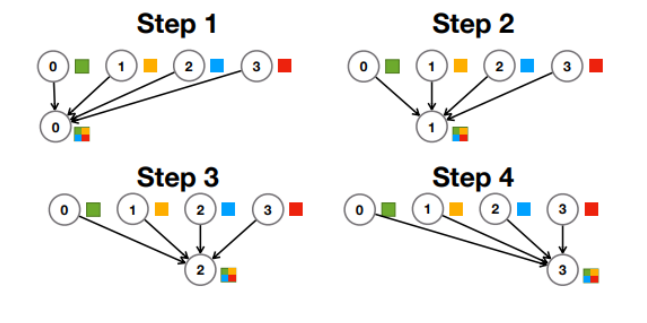
=> 순차적으로 각각의 Worker node에 여러 node가 협력해서 All-Reduce 구현. (모두가 Param Server 역할)
=> Time : O(N), Bandwidth : O(N)
* Naïve All-Reduce implementation: Ring
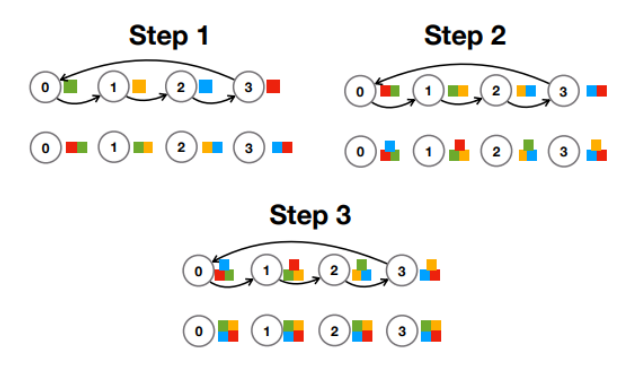
=> 매 Step마다 각각의 Server가 본인의 Gradient 전달
=> Time : O(N), Bandwidth : O(1)
* Naïve All-Reduce implementation: Parallel reduce
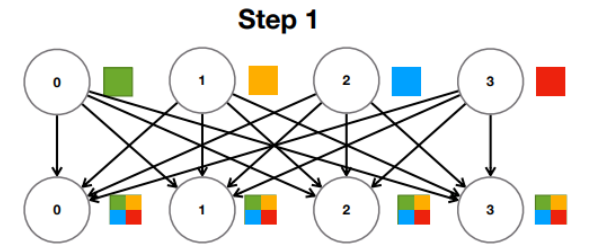
=> All Reduce를 한번에 실행. 모든 Worker가 모든 Worker에게 Gradient를 전달하며 동시에 집계
=> Time : O(1), Bandwidth : O(N^2)
* Better All-Reduce implementation: Recursive halving All-Reduce
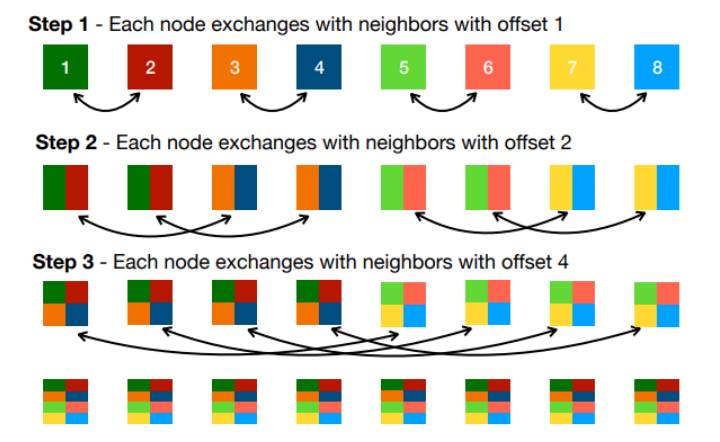
=> offset을 늘려가며 해당하는 Worker끼리 교환
=> Time : O(log N), Bandwidth : O(1)
4. Model Parallelism
* Motivation
Data Parallelism은 결국 큰 모델을 학습할 때 문제가 생긴다. 각 Worker 노드에 모델을 복사하여 replica들을 공유하기 때문이다. 이 때는 비록 전 단계가 끝나지 않아 다음 단계를 실행하지 못하고 노는 상황이 발생하여 Utilization이 떨어지고, Worker node간 load balancing 문제가 생긴다고 하더라도 Model을 나누어줄 필요성이 존재하게 되는 것이다.
* Model parallelism workflow
1. Naïve implementation
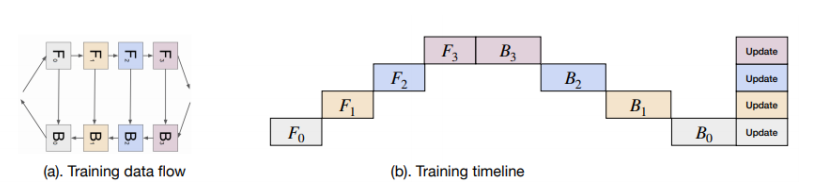
모델 학습에 필요한 과정인 Forward(F), Backward(B)로 절차를 나누면 위의 사진과 같이 모델 레이어를 나누어 줄 수 있다.
(F0 -> F1 -> F2 -> F3 -> 결과 도출 -> B3 -> B2 -> B1 -> B0 -> Update)
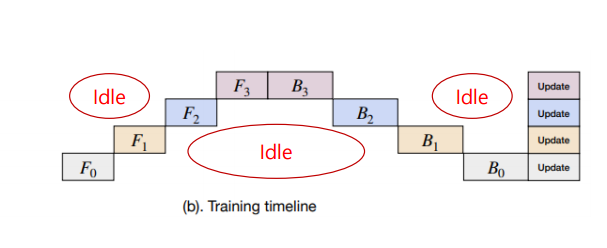
당연히 이 방법은 매우 많은 idle time이 존재해 Utilization이 매우 떨어진다.
2. Micro-batch pipeline parallelism : 각 Forward, Backward batch를 더 잘게 쪼개보자.
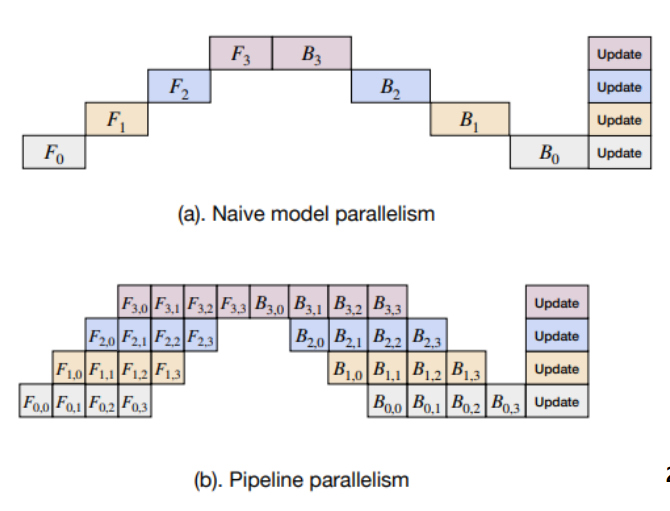
첫번째 micro batch에 대한 F(0,0) 결과를 F(1,0)에 전달한다. 동시에 F(0,1)을 계산하는 식으로 batch 연산을 parallelize한다.
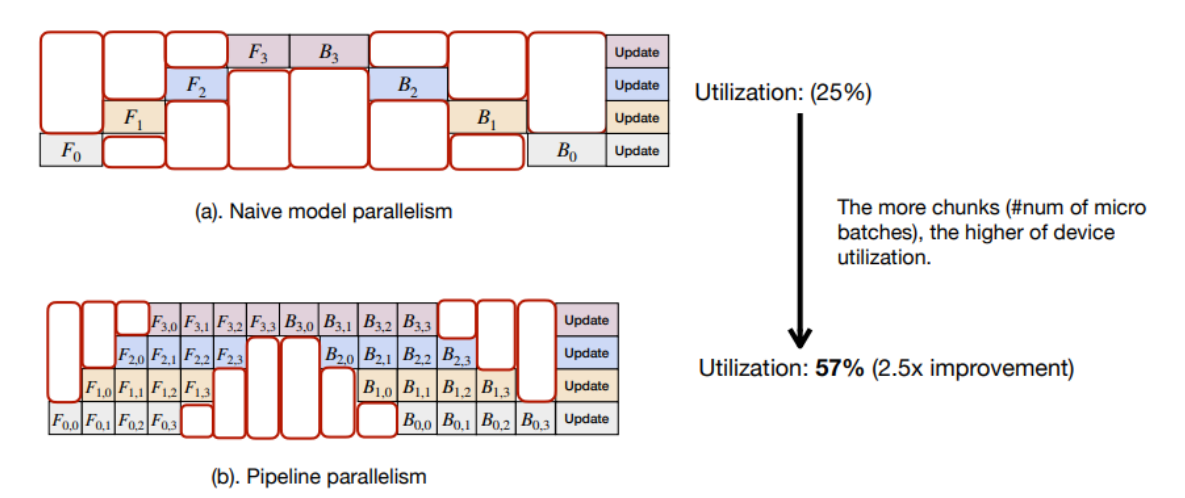
=> Utilization 상승이 된다.
5. Gradient Compression
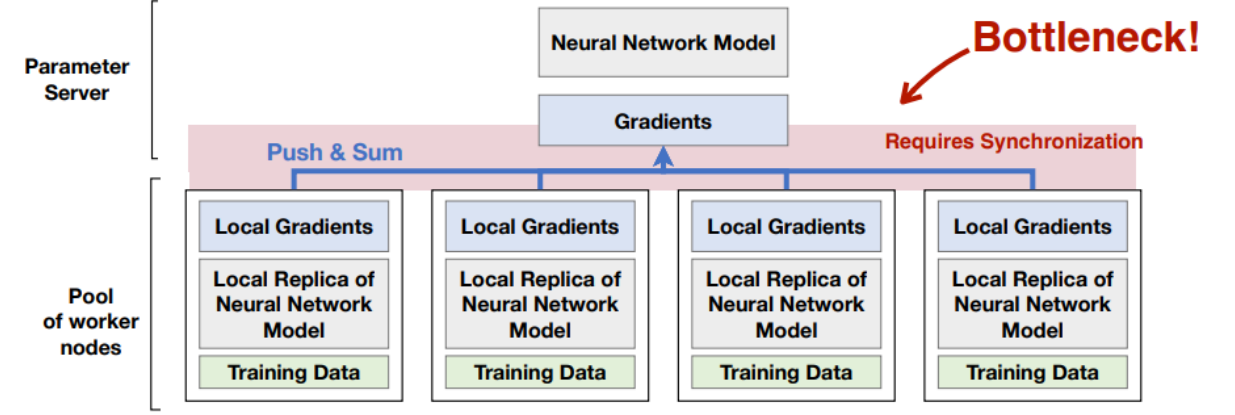
결국 Centralized 된 Param Server 하나를 돌리면 Gradients 전달에 있어 Bottleneck이 걸리는 것이 문제가 되었다. 따라서 Latency가 증가하게 되고 Communication cost가 너무 높아지게 된다. 계산을 빨리하고 싶어서 Worker node를 다는데 늘리면 늘릴수록 느려지는 기현상이 발생하는 것이다.
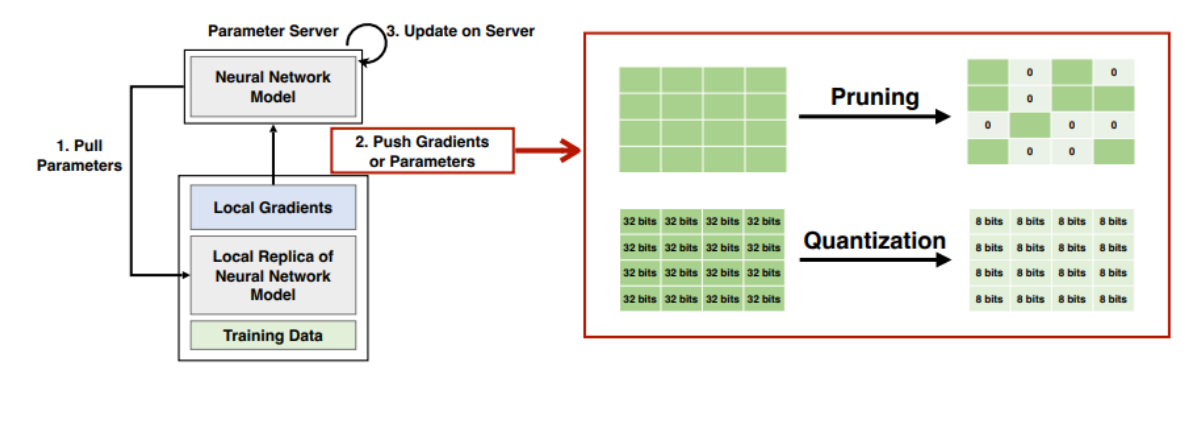
=> Gradient를 압축해서 적은 양을 보내보자. (Pruning, Quantization)
1. Pruning : 중요한 Gradient만 보내자.
2. Quantization : Gradient에서 중요한 정보만 남기고 데이터 유형을 줄여보자. (32 비트 표현 -> 8비트 표현으로 압축)
1. Gradient Pruning : Sparse communication
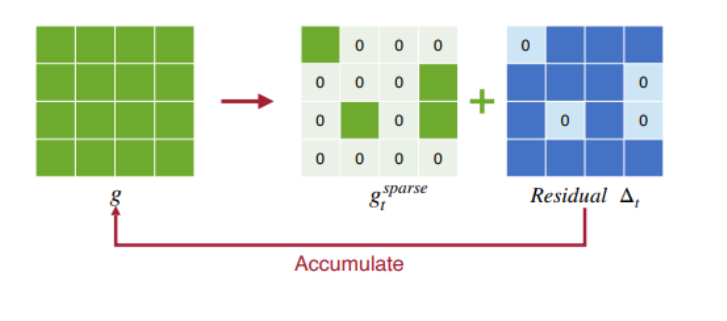
그렇다면 어떤 값이 중요해서 전달해줘야하는 Gradient 일까? => 모든 Gradient 중 가장 크기가 큰 k 개를 보내자.
(모델을 많이 변화시킬 것이기 때문에)
이 때, 버려질 0 padding part들의 학습 손해를 보완하기 위해 Residual로 백업을 해둔다.(계속하여 Worker node 단에 누적하면서 이후 Gradient 계산에 더해서 따진다.) 즉, 버려진 값들이 쌓여 모델에 유의미한 업데이트를 일으킬 수 있다면 이 때 적용하는 것이다.
2. Gradient Quantization : 1-bit SGD
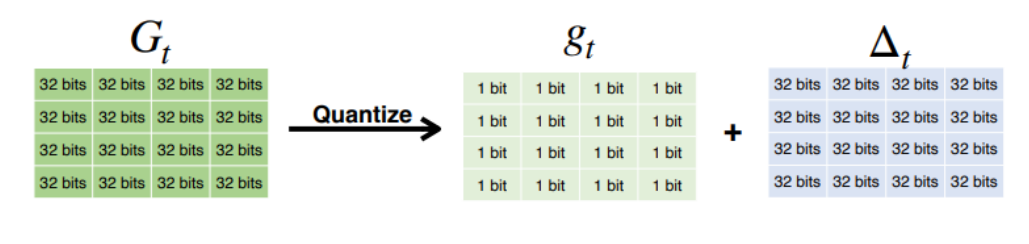
표현을 압축하는데, 이때 발생한 Error를 Pruing의 residual과 같게 기록을 해서 후 결과에 반영해준다.
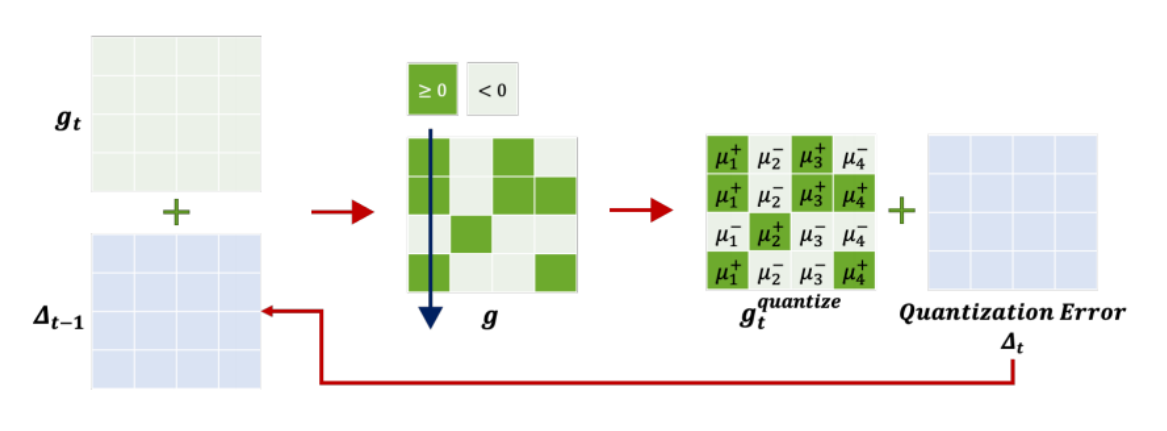
=> 전송은 +,- 여부만 전송하되, 다음 gradient 계산에 이전 Quatization Error도 누계한다.
'개인 공부' 카테고리의 다른 글
| Distributed System - 10. Distributed Learning Algorithms (0) | 2024.12.06 |
|---|---|
| Distributed System - 8. Fault Tolerance (0) | 2024.12.04 |
| Distributed System - 7. Consistency & Replication (0) | 2024.12.02 |
| Distributed System - 6. Coordination (0) | 2024.12.02 |
| Distributed System - 5. Naming (0) | 2024.10.23 |