* Classification
- 주어진 Data (Training set) : 각 데이터들은 attribute들의 집합이다. 그리고 각 Attribute들은 class이다.
- class attribute에 대한 Model을 찾는다.
=> 목표 : 새로 주어진 데이터의 class를 정확히 할당해주어야 한다. (Classification)
- Process

- Classification 에서 Error의 원인
1. 불충분한 training data
2. 너무 적은 feature
3. 너무 많거나 설명력이 떨어지는 feature (ex: 여자,남자를 classification하는데 오늘의 날씨.)
4. Overfitting
=> 해결법 : Introducing new feature
- Classification Terms
1. Accuracy : test data가 얼마나 잘 분류되었는가? : 맞은 개수 / 데이터 수
2. False Positive : Negative가 Positive로 잘못 분류됨. (주로 큰 class가 negative class이다.)
3. False Negative : Positive가 Negative로 잘못 분류됨.

* Clustering
- Attributes를 가지는 Data point들의 집합 및 그들 사이의 유사성 척도가 주어진다.
=> 이 Data point들 간의 유사도를 따져서 그룹을 나눈다. (Clustering)
- attribute들이 연속형일 경우 Euclidean Distance, 그 외의 경우 문제에 맞춰 측정한다.
사례 1. 시장을 구분된 소비자의 집단으로 나누어 각 집단이 구별된 마케팅 믹스를 통해 시장 목표를 설정.
- 접근 방식 :
- 고객의 지리적 및 생활 스타일과 관련된 다양한 속성 수집
- 비슷한 고객들의 군집을 찾음
- 같은 군집 내 고객들과 다른 군집의 고객들의 구매 패턴을 관찰하여 군집화의 품질 측정
사례 2. Document Clustering.
목표 : 중요한 용어(Keyword)를 기반으로 서로 유사한 문서들의 그룹을 찾는 것.
- 접근 방식:
- 각 문서에서 자주 등장하는 용어들을 식별
- 다양한 용어들의 빈도수를 기반으로 유사성 측정 기준을 세움
- 그것을 사용하여 군집화를 진행
* Association Rule Mining
- Item의 집합이 포함된 데이터 집합이 주어진다.
=> 이때 다른 아이템들의 발생에 기반하여 앞으로의 아이템 발생을 예측하는 규칙을 생성하는 것이다.

그 예시로, 각 TID 마다 Item들의 목록이 있으며, 해당 데이터들을 기반으로 발견된 Rule 중 Milk가 있을 때 Coke가 구매될 가능성이 있음을 나타낸다.
사례. Marketing & Sales Promotion
- 발견된 규칙 : {베이글} -> {포테이토 칩스}
=> 포테이토 칩스를 결과로 사용함 - 판매를 촉진하기 위해 무엇을 해야하는지에 도움
=> 베이글을 선행 요소로 사용함 - 상점이 베이글 판매를 중단 시 어떤 상품이 영향을 받는지 파악.
# Regression
- numerical value를 예측하기 위한 모델.
- Parametic model들은 여러 개의 parameter들로 구성된다.
1. parameter를 뭘로 쓸지는 본인이 결정해야한다. (데이터들을 보고)
2. x,y는 parameter가 아니다. (직접 관찰하기 때문에)
3. 모든 모델이 parameter를 가지지는 않는다.
Modeliong process
1. 모델 고르기
2. loss function 지정. (error의 기준 정해줌.)
3. Fit the model.(Best parameter를 찾는 과정)
4. Evaluate model performance.
* Simple Linear Regression Model

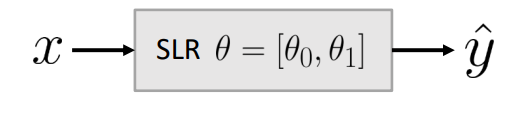
=> Parametic model이다. 데이터들을 가장 잘 설명하는 선을 찾는 것.
* Loss Function
- 우리는 얼마나 모델이 "좋은지" 판단하는 metric이 필요하다.
- Loss Function은 특정 model 또는 model parameter 선택에서 발생하는 cost, error 또는 fit resulting을 포함한다.
(예측된 y'가 실제 값 y에 가깝다면 낮은 loss를 주어야한다.)
- Loss Function을 정할 때는 내가 어느정도의 정확도를 원하는지, 모든 error가 equally costly인지, output이 어떤 형태인지에 따라 다양한 방안을 고려해야한다.
# L1 Loss = |y-y'|, L2 loss = (y-y')^2
(L2 loss가 많이 쓰인다.)
결국 y=a+bx 에서 L2 loss는 L(y,y') = (y-(θ0+θ1x))^2이 되게 되는거다.
# Average Loss(Empirical Risk)
- 우리는 데이터 세트 전체에 대해 모델의 예측이 얼마나 나쁜지를 알아야한다. 따라서 단 하나의 점이 아니라 모든 점에 대해 나쁜 정도를 측정하는 자연스러운 방법은 Average Loss 이다.
- 어렵게 생각할 것 없이 각 Point 들의 Loss들의 산술 평균을 구해주면 되는 것이다.

- 주어진 데이터는 고정되고, 따라서 이 함수는 θ의 함수이며 y'를 결정한다. (L2 loss의 식 표현 참고)
- Average loss는 모델이 주어진 데이터를 얼마나 잘 맞추는지를 알려준다. 그러나 모집단에 대한 정보는 아닐 수 있단 것을 명심하자.
(이때, Loss function을 L2로 쓰면 Mean Squared Error, L1으로 쓰면 Min Absolute Error가 되는 것이다.)
* Minimizing MSE
- 결국 model을 fitting 한다는 것은 Average Loss를 줄이는 것이다. 여기서 Model은 일단 간단한 SLR을 가정하자.
y'= θ0+θ1x => 결국 이 model의 MSE를 최소화 하고 싶다는 것이고. 이는 test y와 predict y의 간격을 줄이는 것이다.
이때 MSE에 대해 θ0, θ1을 편미분하여 0이 되는 지접을 통해 매개변수의 최적값을 구할 수 있다.
* Evaluation
- 얼마나 model이 실제 data에 대해 잘 예측하는지 점수를 매긴다.
1. data Visualization, compute statistics.
- Plot original data
- 열의 평균과 표준편차를 계산한다. 이 과정까지 하면 데이터를 수치적, 시각적으로 이해가 가능하다.
- 변수 간의 correlation을 계산해서 양의 관계인지, 음의 선형관계인지, 아예 관계가 없는 변수인지를 따져볼 필요가 있다
2. RMSE는 MSE에 root 연산을 한 것으로, 평균 loss를 나타낸다. MSE에 root를 취해서 실제 y 값과 같은 단위를 가진다.(Performance metric)
3. Visualization=> error e에 대해 (e=y-y') plot을 그린다.
'개인 공부' 카테고리의 다른 글
| 데이터 과학 - 6. Data Understanding & Visualization (0) | 2024.04.09 |
|---|---|
| 데이터 과학 - 5. Data Acquisition (0) | 2024.04.09 |
| 확률 및 통계 - 5. Joint density and Cumulative Distribution Func. (0) | 2024.04.07 |
| 데이터 과학 - 3.Data Science Methodology Part 2. (0) | 2024.04.03 |
| HCI - Needfinding (0) | 2024.04.02 |