* Data Understanding
=> 데이터가 모델링을 위해 충분한 quality를 갖추고 있는가는 다음의 3가지로 따진다.
- Completeness : 모인 데이터의 size를 측정한다.
- Noisiness : Scatter plot을 그려 경향성이 있는지 확인 가능하다.
- Consistency : Mean, Variance를 그려 확인할 수 있다.
어떤 모델이 사용되어야하는지 판단은 plot을 그리거나 상관계수를 측정하여 결정할 수 있고,
데이터가 project target에 관련 있는지는 Visualization,
modeling하기에 충분한지는 Data size를 측정함으로 알 수 있다.
우선 데이터를 사용하기 전에 데이터의 특성에 대한 이해를 하는 것은 매우 중요하다.
데이터의 특성이 어떠한 성질을 지니는지 모르는 상태에서 데이터를 변환하거나 건드리는 것은 좋지 않다.
따라서 이 단계 전에 데이터를 변환하는 것은 권장되지 않는다.
Data understanding 단계의 핵심은 모델링 단계에서 데이터의 활용성을 확보하기 위해 해당 데이터의 기본 지식을 구축하는 것이다.
이러한 목적으로 가장 자주 사용되는 방법은 "Data Visualization"이다. 이는 종종 EDA라고도 불린다.
결국 그려서 확인하는 것이 가장 좋다는 것이다.
예를들어, 다음과 같은 데이터가 있다고 가정해보자.


우리는 Number of Clicks와 D/W 데이터가 있다. 눈으로 수치 데이터를 봐보자. 한번에 데이터의 경향성이나 특성이 이해가 쉽지 않다. 이를 Scatter plot을 통해 Visualization을 해보자.
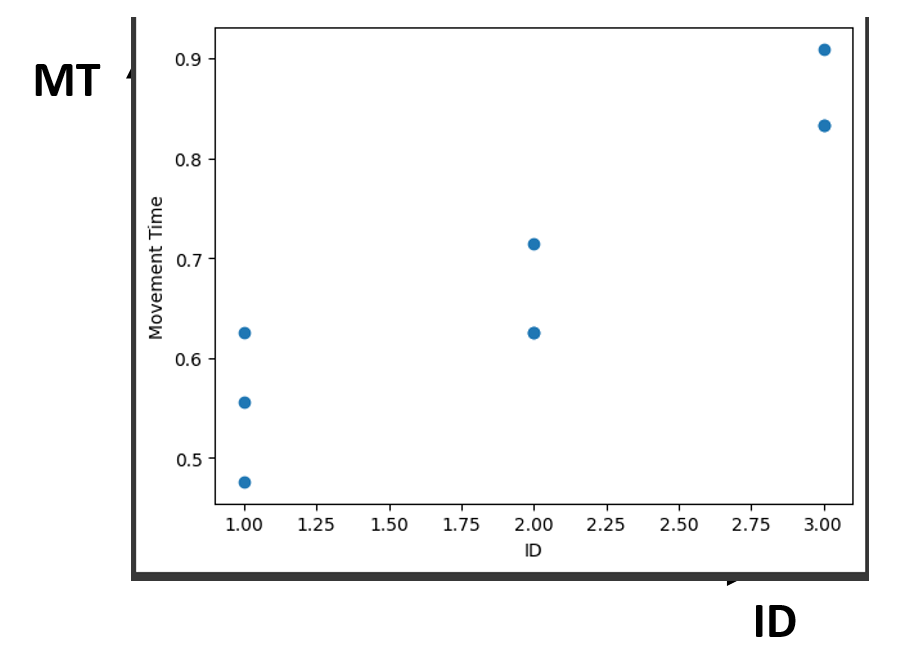
이제 뭔가 ID와 MT의 분포에 상관관계가 있음이 한 눈에 보인다.(Movement Time = TotalSecond / # of Clicks)
이렇듯 Visualization 데이터에 대한 결론을 내리는 것, 이해하는 것에 도움이 된다. 또한 이해가 직관적이기 때문에
다른 사람에게 결과를 설명하기 쉽다.
* Distribution
=> Distribution은 variable이 발생하는 빈도수를 의미한다.
각 값들은 분포 결과에 1대1 반영이 되어야 하며, 각 카테고리의 데이터는 빈도 수를 가르켜야한다. 따라서 총 빈도수의 합은 100%가 될 것이다.

이것은 Distribution일까? 정답은 아니다. 하나의 사람이 둘 이상의 카테고리에 속할 수 있다.
또한 각 그래프의 숫자는 개인의 비율이나 수가 아니라 "시간"에 해당한다.

이 역시 Distribution이 아니다. 각 범주에 % 단위로 그래프가 그려졌으나, 총합을 보면 100%를 넘는다. 세부 설명에도 써있지만 multiple option이 허용된 경우이다.
* Distirbution Visualization method
1. Value Table

보여주기는 쉽지만 직관적이지 못하다.
2. Bar plot

정성적(categorical) variable distribution을 표시하는 가장 범용적인 방법이다. 색상을 통해 범주별 표시를 할 수도 있다.
빈도 수를 직관적으로 표시하기 좋으며 비교가 용이하다. 그러나, scale의 설정이 중요하며 단순함으로 시계열 데이터 같은 데이터를 표현하는데는 부족할 수 있다.
만약 위의 그래프에서 y축의 scale을 극단적으로 크게 만들면, 모든 언어별 빈도수가 비슷하게 보일 것이다. 이는 설명력이 떨어져 bar plot으로서의 가치가 없으며, 심지어 악의를 가지면 결과를 다른 방향으로 유도하는데 사용될 수도 있다.
3. Pie Charts

Bar plot에 비해 "빈도 수" 보다는 분포에 초점을 맞춘 Visualization 방법이다. 결과의 balance, imbalance가 직관적으로 보인다.
4. Line Graphs & Area Charts
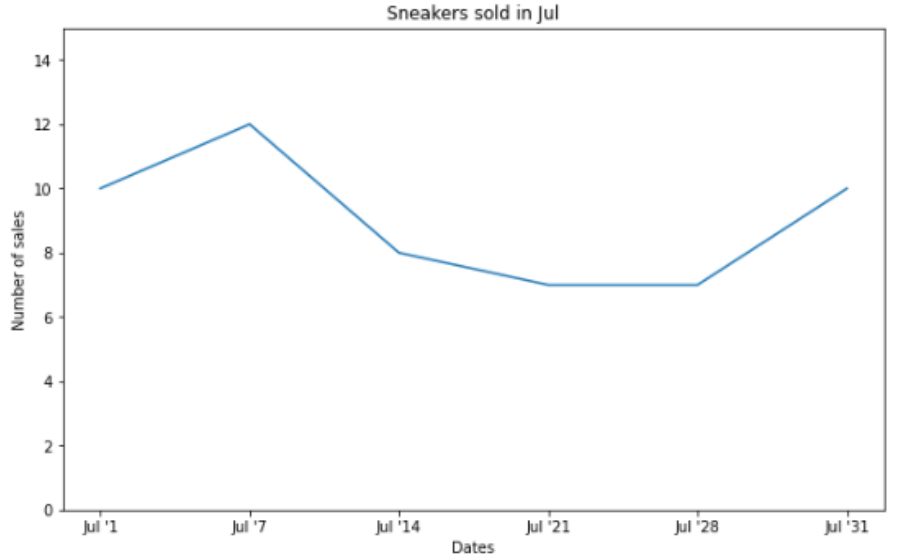
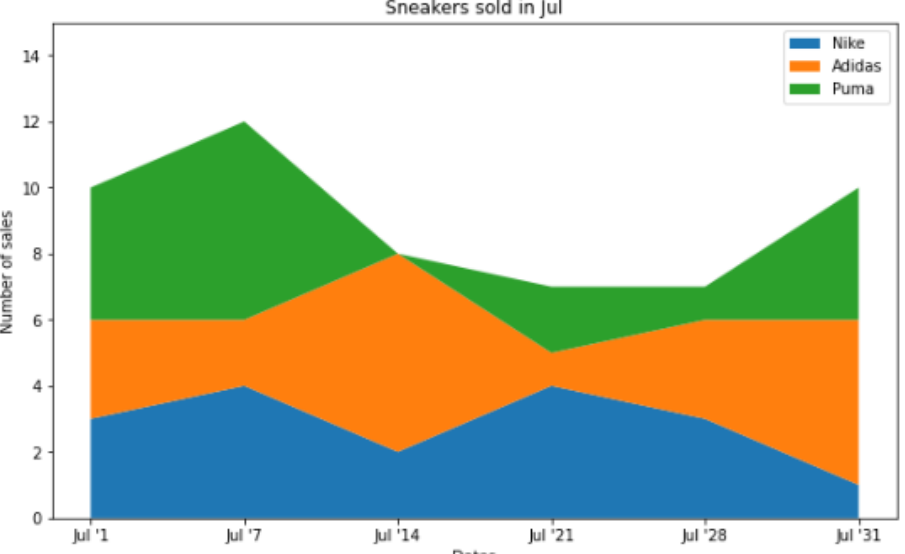
시계열 데이터의 표현이 좋으며 데이터 포인트 사이의 상승&하락을 명확하게 보여주어 경향성 파악이 쉽다.
또한 여러 데이터를 동시에 표시하여 비교하기 쉽다.
그러나 연속성이 강조되어 개별 데이터 포인트의 중요성이 감소되며, 데이터 포인트가 많을 경우 그래프가 혼잡해진다.
5. Scatter plots
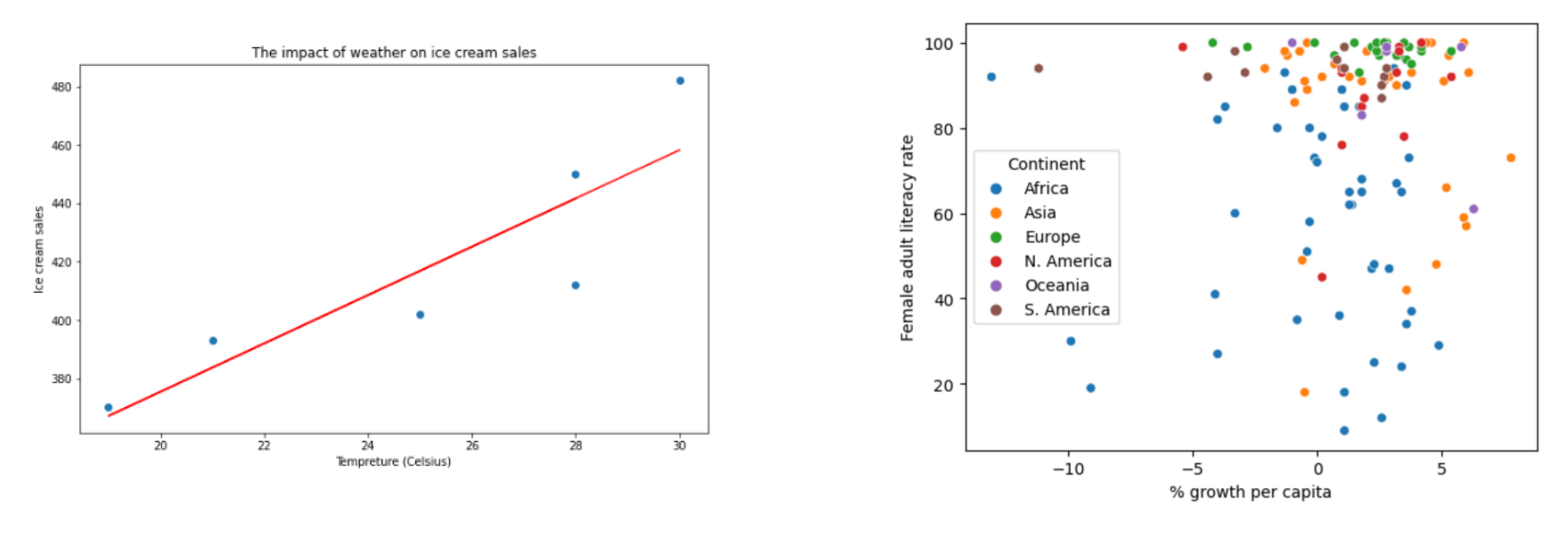
각 데이터 포인트를 좌표계 위에 찍는다.(위에 예시로 들었던 fitt's law 에서 Scatter plots을 사용하였다.)
x,y 축 두 변수간의 상관 관계 파악이 쉽고, Outlier의 확인이 쉽다.
그러나 큰 데이터 세트의 경우 약간은 복잡해질 수 있고, 다차원 데이터 표현이 어렵다.
또한 두 변수 간의 상관 관계는 보여줄 수 있으나, 이것이 인과 관계를 의미하는 것은 아니다.
6. Heatmaps
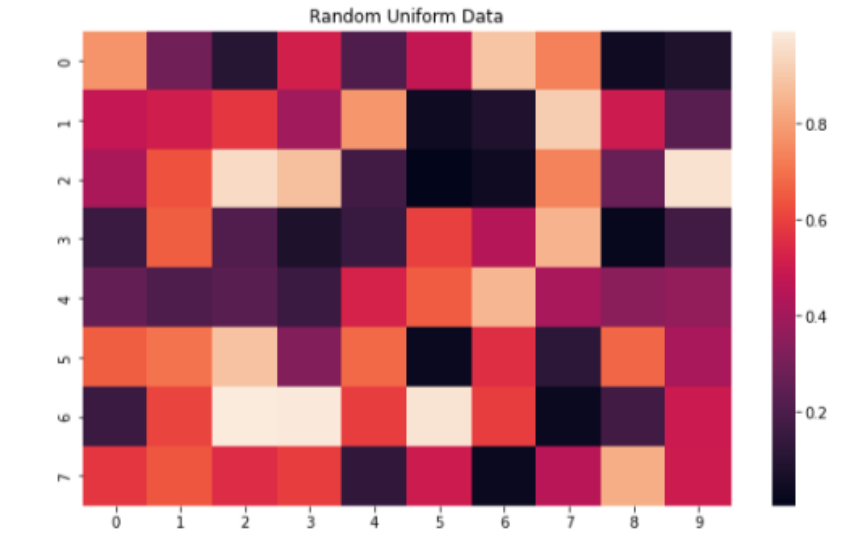
Heatmap은 각 셀마다 값에 따라 색상을 다르게 표시하는 방법이다. 데이터의 패턴, 변화, 특이점을 빠르게 확인할 수 있게 해준다. 특히, 많은 양의 데이터가 있을 때 유용하다(데이터의 밀도를 표현한다.).
그러나 색상에 대한 개인적인 인식 차이로 오해를 불러일으킬 수 있으며, 색상이 너무 많거나 미묘한 차이가 있을 때 정보가 과다해져 해석이 어렵다.
7. Treemap
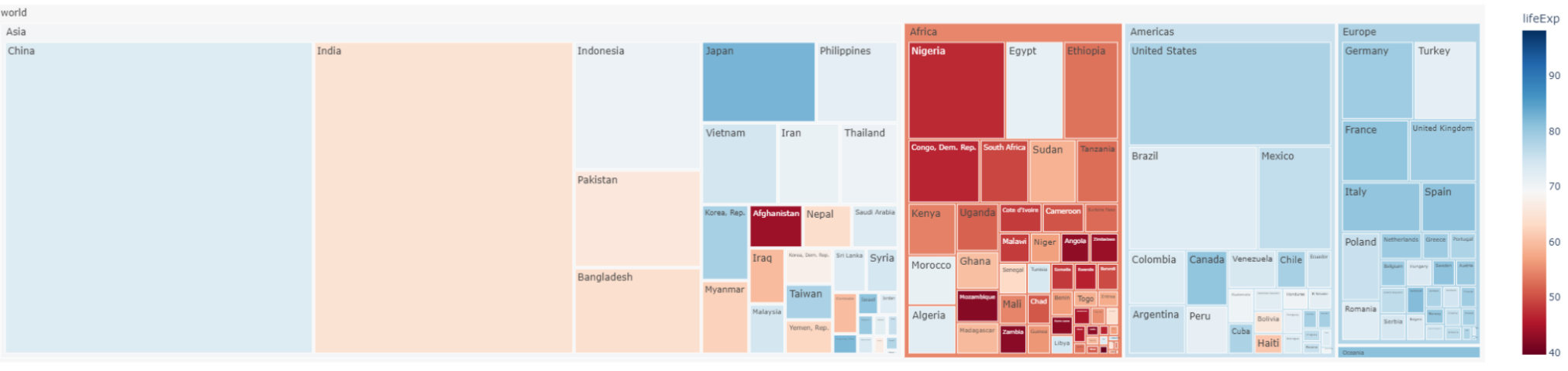
Treemap은 상위 category와 하위 category를 명확히 나타내며 전체 데이터의 계층적 구조를 한 눈에 볼 수 있게 해준다.
데이터의 상대적 크기를 사각형의 면적으로 표현하여 데이터 크기의 차이 또한 인지할 수 있다.
따라서 데이터 세트 내에서 여러 범주의 상대적 중요성을 비교할 때, 파일 시스템의 공간 사용과 같은 계층적 구조를 시각화할 때에 좋다.
단점은 너무 많은 사각형이 생성될 경우 확인이 어려우며, 정확한 면적 비교는 어렵다.
* Bar plot 그리기
1. 기본 라이브러리 사용
births['MaternalSmoker'].value_counts().plot(kind="bar")
2, matplotlib.pyplot 사용
import matplotlib.pyplot as plt
ms = births['Maternal Smoker'].value_counts();
plt.bar(ms.index.astype('string'), ms);
3. Seaborn 사용
import seaborn as sns
sns.countplot(data = births, x = 'Maternal Smoker')seaborn 라이브러리의 countplot은 높은 추상화를 제공하기 때문에 따로 데이터를 처리해서 줄 필요 없이 x축 카테고리만 지정해주고 데이터프레임을 주면 된다.
4.plotly 사용
import plotly.express as px
px.histogram(births, x = 'Maternal Smoker', color = 'Maternal Smoker')8. Histograms
bar plot과 유사하지만 중요한 차이점이 있다.
bar plot은 범주형 카테고리에 유용하다. 예를 들면 True or False 등이 있다.
그러나 이렇게 정리되지 않고 연속적인 수치를 값으로 가지는 데이터도 bar plot으로 표현할 수 있을까?
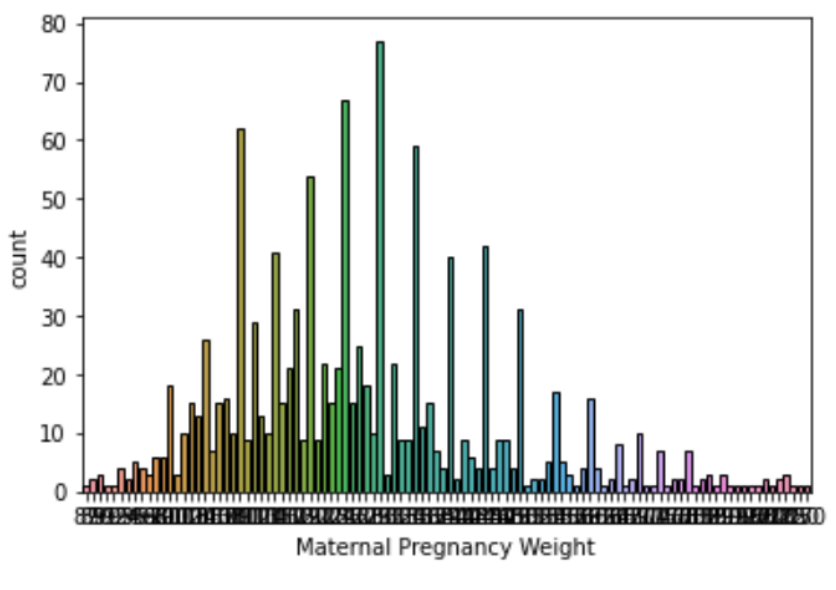
너무 각 수치에 대해 많은 범주가 생성될 것이다.
이 경우는 연속적인 수치 데이터를 나타내는 별도의 방법이 필요할 것이다.
해당 방법이 바로 Histogram이다.
데이터를 일정한 간격의 bin으로 나누어 각 bin에 포함되는 데이터의 빈도수를 나타내는 것이다.
막대 사이에 간격이 없으며 따라서 연속성이 강조된다.
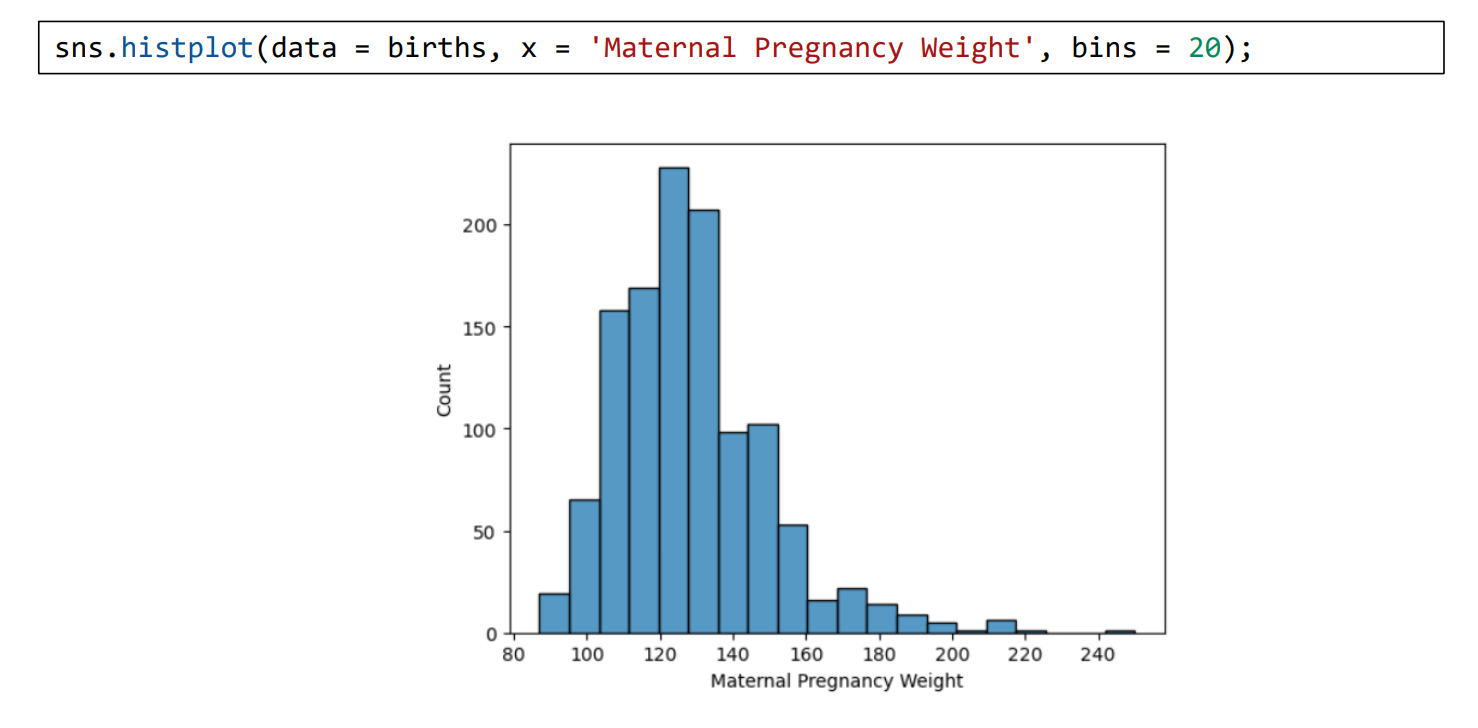
즉, Categorical은 Bar plot, Continuous Numerical은 Histogram을 사용하는 것이다.
9. Overlaid Rug plot
히스토그램의 바닥이나 옆면에 얇은 선(Rug)를 추가하여 실제 데이터 포인트의 위치를 표시하는 것이다.
Histogram에서 구간별 데이터의 밀도를 보여주는 대신 데이터의 분포를 확인할 수 없다는 단점을 보완해준다.
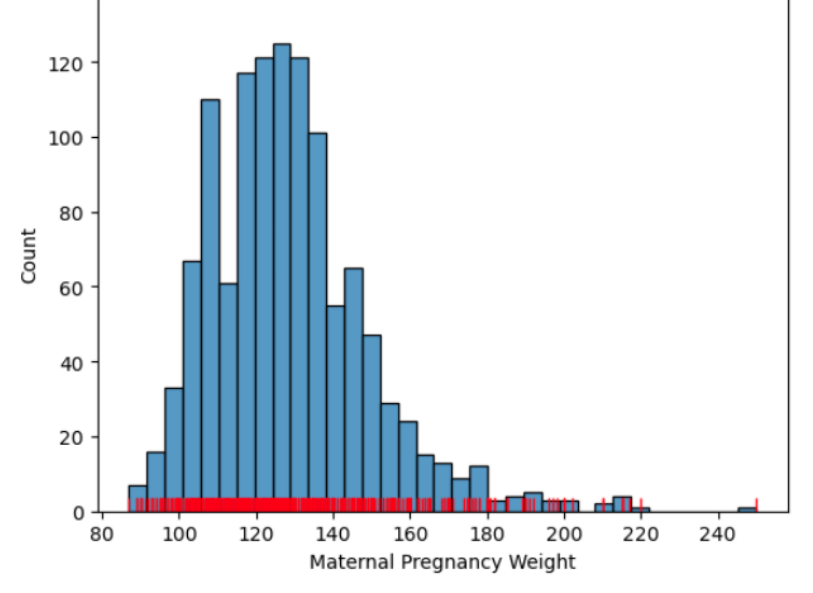
데이터에 이상치가 있거나 특정 구간에 데이터가 집중되어 있는 경우 유용하다.
* Evaluating Histograms
Histogram을 보고 우리는 데이터를 어떻게 이해하면 될까? 다음의 요소를 주목해보자.
1. Skewness & Tails
2. Outliers
3. Modes.
1. Skewness
- 만약 distribution이 long right tail을 지닐 시, skewed right이라고 부른다.
평균은 일반적으로 중앙값의 오른쪽에 있다. 값이 큰 극단값이 많은 케이스다.
- 만약 distribution이 long left tail을 지닐 시, skewed left라고 부른다.
평균은 일반적으로 중앙값의 왼쪽에 있으며 값이 작은 극단 값이 많은 케이스다.
2. Outlier
- 그래프를 통해 어느 지점부터(bin) Outlier로 판별할 것인지 등의 결정을 내릴 수 있다.
3. Modes
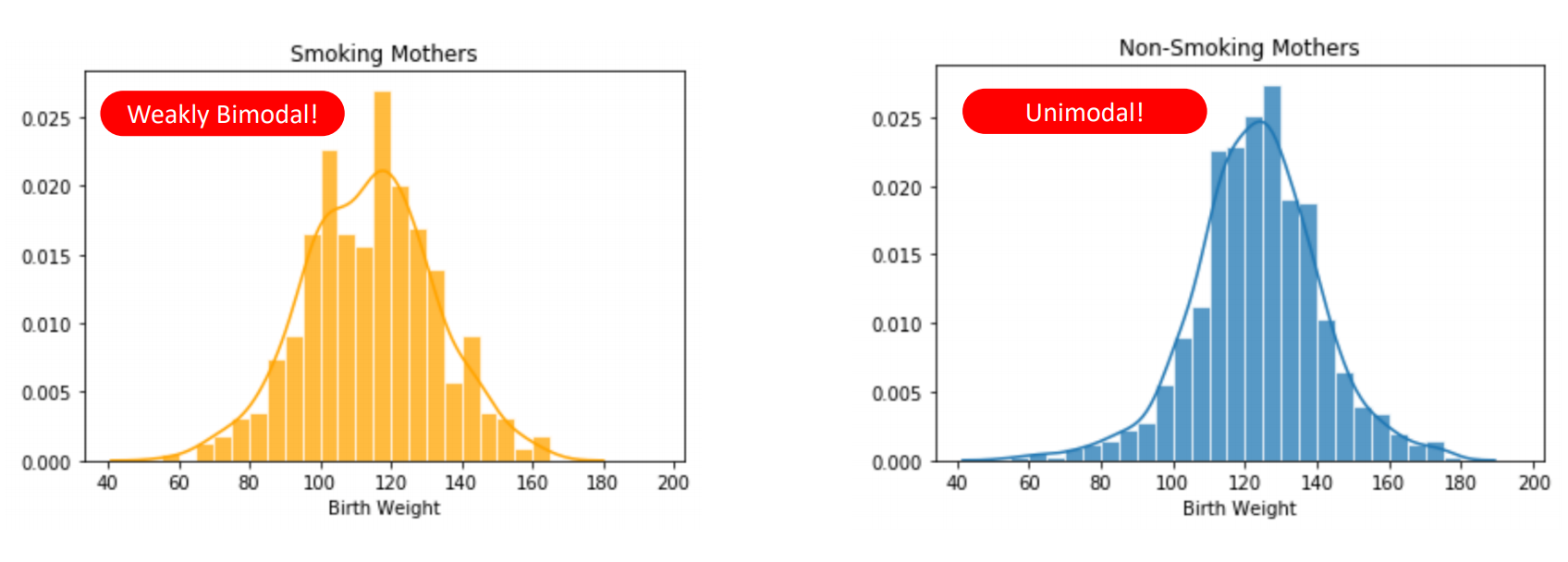
- local or global maximum을 의미한다.
한 개의 clear maximum을 지닌 distribution을 unimodal.
두 개의 maximum을 지닌 distribution을 bimodal, 3개 이상을 multimodal이라고 부른다.
단, 모든 maximum 부분이 유의미한 데이터 그룹을 나타내는 것은 아니다. (단순한 noise일 수 있다.)
10. Box and whisker plot
Box and whisker plot은 중앙값, quartile, Box, Whiskers, Outliers로 이루어진다.
First or lower quartile은 25%, Second quartile은 50%, third or upper quartile은 75% 로 나눈다.
[Q1, Q3] 구간은 중간 50%가 포함이 된다.
따라서 IQR = Q3-Q1으로 구할 수 있으며, IQR이 클수록 데이터가 Q1~Q3 사이에 밀집이 되어있는 중앙 집중형 데이터인 것이다.
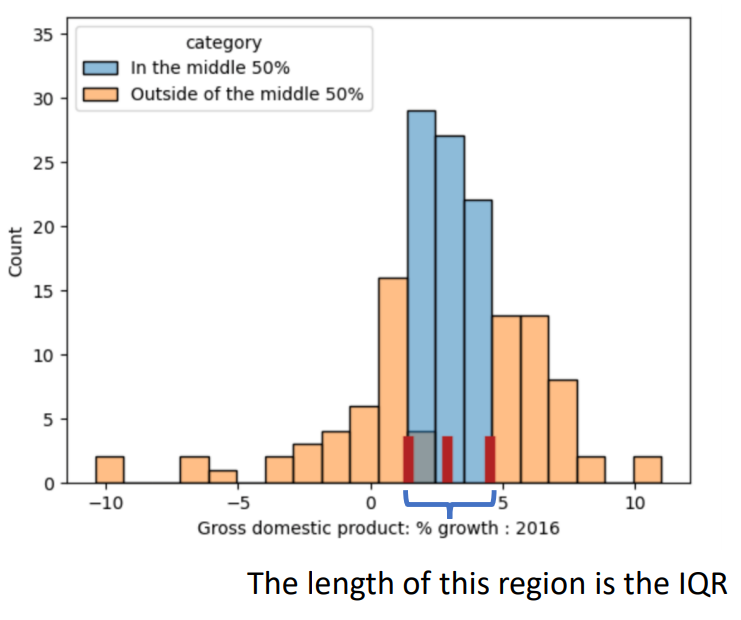
Box plot은 다음과 같이 그려진다.
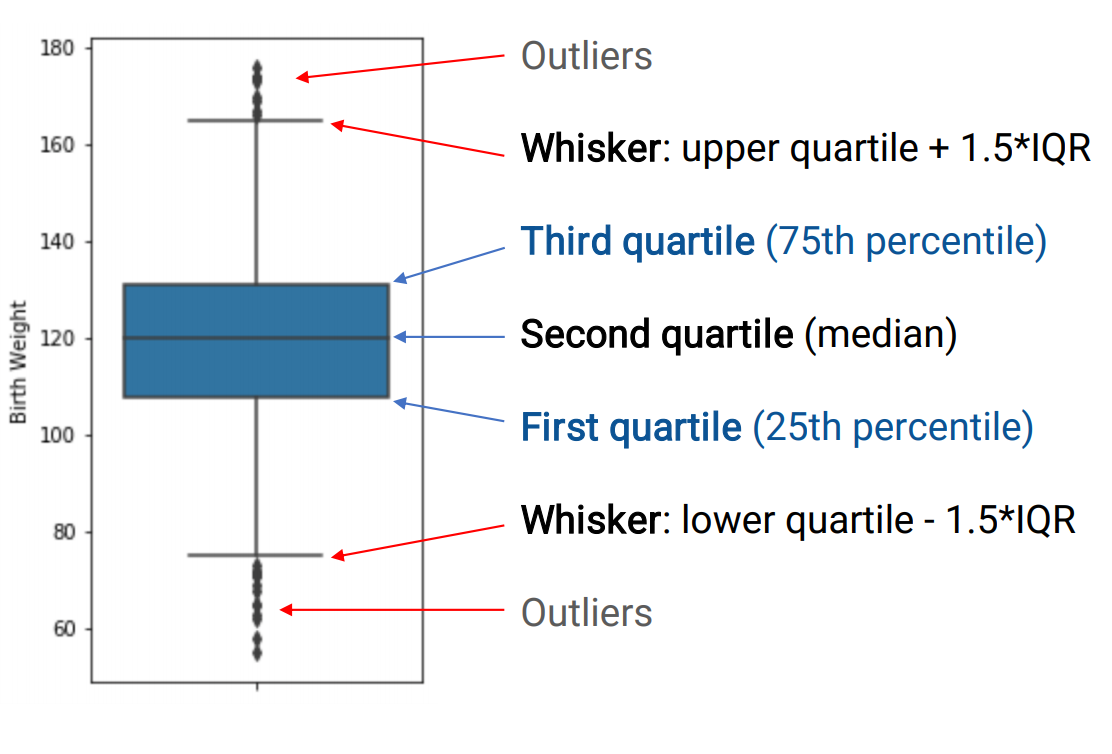
Box는 아래부터 위의 선으로 Q1,Q2,Q3로 그려진다. Whisker는 1.5*IQR만큼 위 아래로 선을 긋는다.
이 whisker를 벗어나는 것을 Outlier로 판단한다.
그림을 보면 알겠지만, 지나치게 많은 생략이 들어가는 편이다.
(데이터의 mode를 정확히 파악하기 어려운 등의 문제가 있다.)
보통 box,whisker plot을 표현하기 위해 (whis1, Q1, Q2, Q3, whis2)로 표현한다.
11. Violin plots
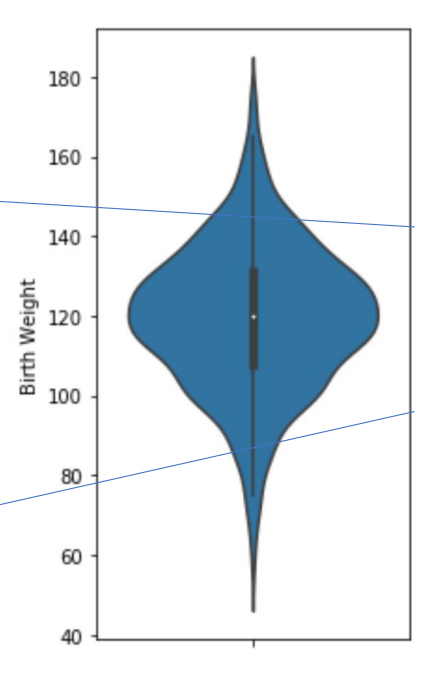
box plot과 거의 유사하나, box plot에 비해 데이터 분포의 밀도를 시각적으로 제공해주는 부드러운 밀도 곡선을 함께 제공한다. 그림의 width를 통해 기존 box plot에서 데이터의 밀도까지 파악할 수 있게 해주는 것이다.
12. Ridge Plots
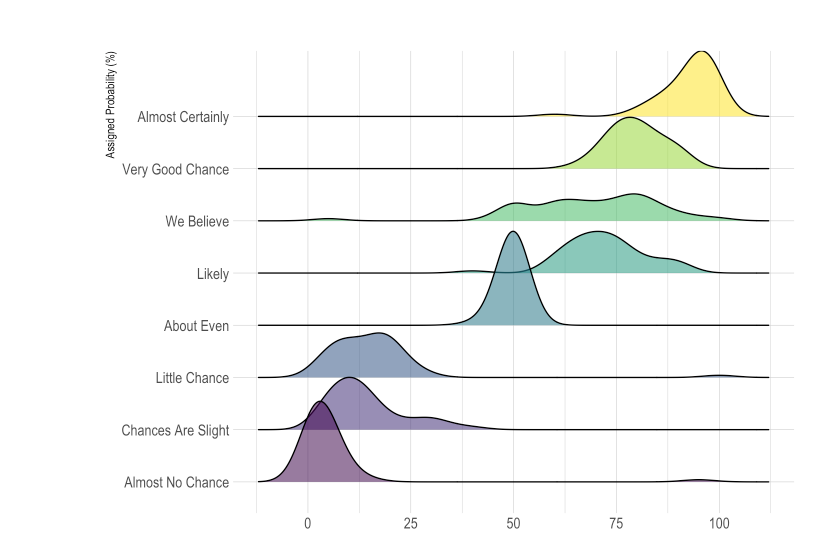
여러 개의 밀도 plot을 겹쳐서 보여주는 방식이다. 다양한 그룹의 분포를 설명할 때 좋다.
Overlap을 최소화하면서 한눈의 분포 형태를 볼 수 있다.
* Comparing Distributions
1. Overlay
Distribution을 비교하는 방법 중 가장 쉬운 방법은 Overlay시키는 것이다.
Histogram, Line graph와 같은 그래프에 적합하다.
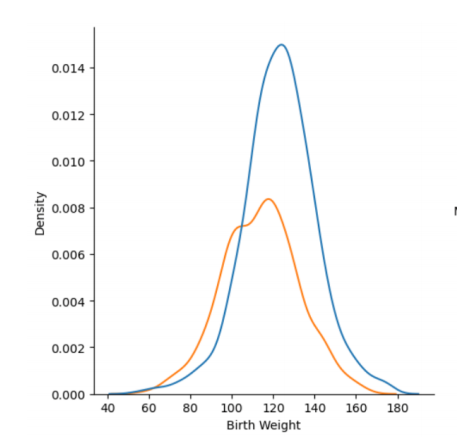
그러나 Histogram 같은 경우에는 색상이 섞여서 3개의 Histogram처럼 보일 수도 있다.
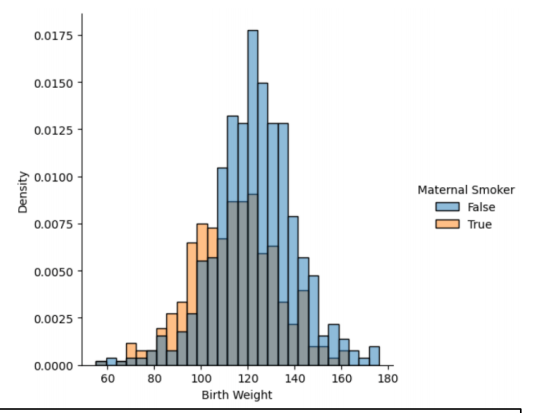
또한 많은 정보가 들어가게 되면 그래프가 난잡해진다.
2. Side by Side
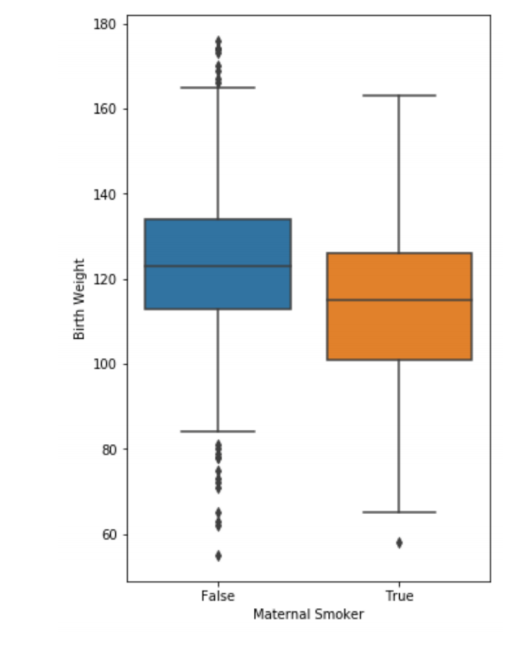
Box plot과 Violin plot 같은 경우에는 간결한 분포를 띄기 때문에 양쪽으로 그리기 편하다.
한 눈에 봐도 False 쪽일 수록 Birth Weight이 높게 분포되어있는 것을 알 수 있다.
* Kernel Density Estimate
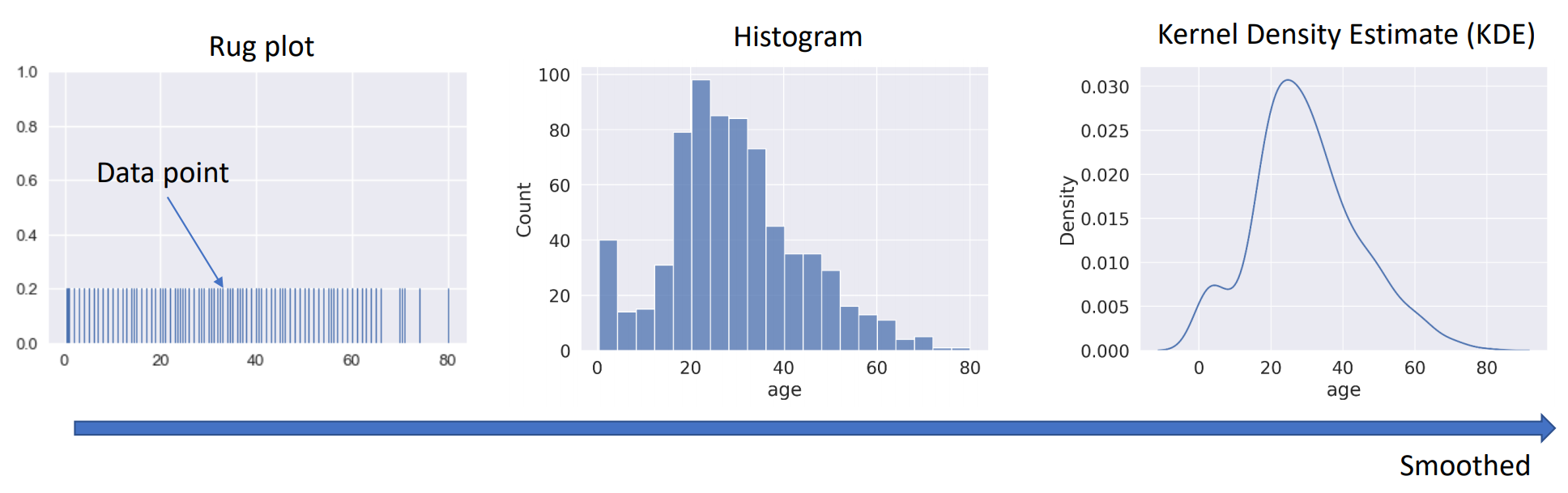
각 데이터 포인트에 가중치를 주어 부드러운 곡선을 생성하는 방식으로 작동한다.
이 곡선은 데이터의 밀도를 연속적으로 나타내며, KDE는 데이터의 가능한 모든 범위를 고려하여 평활화된 분포를 추정하므로, 실제 데이터가 존재하지 않아도 KDE 곡선이 그려질 수 있다.
(KDE는 데이터가 존재하지 않는 곳에서도 확률을 추정하여 그린다.)
KDE는 데이터 셋에서 확률 믿로 함수를 추정하는데 사용된다. 따라서 곡선의 총 면적은 1이어야한다.
1. 각 데이터 포인트에 커널을 배치한다.
2. 전체 면적이 1이 되도록 커널을 정규화한다.
3. 모든 커널을 합한다.
=> 해당 과정을 수행하기 위해 kernel function과 bandwidth(smoothing parameter)를 정해주는 과정이 필요하다.
아래의 데이터를 KDE로 표현한다고 해보자.
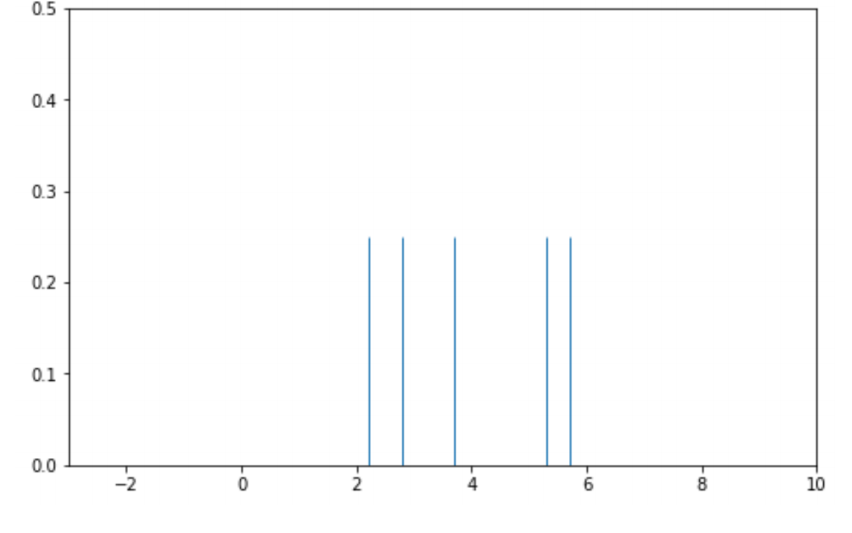
1. Place kernels
- Gaussian kernel을 bandwidth 1로 배치하자.
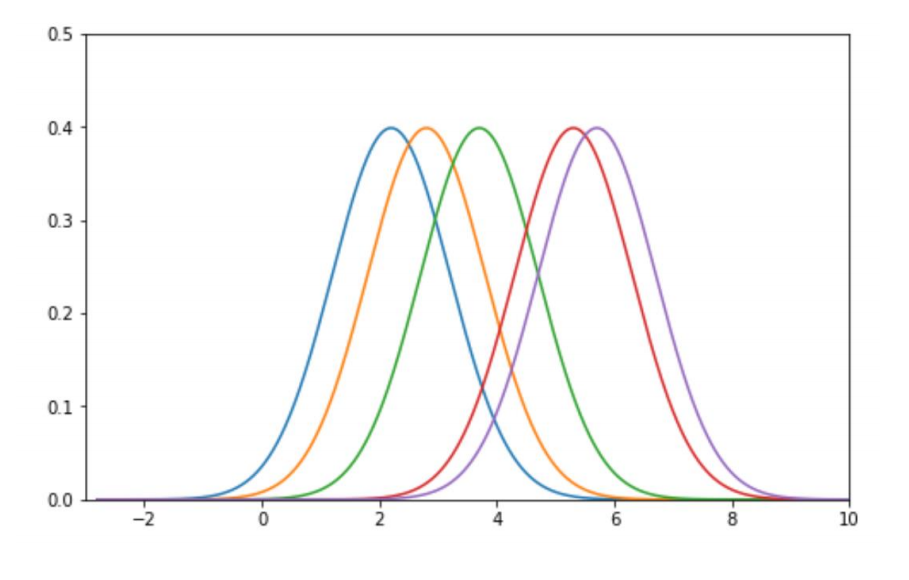
2. Normalize Kernels
- 결과의 합이 1의 크기를 가져야 한다. 각각 영역이 5개가 구성될 것이므로 커널들에 1/5를 곱해준다.
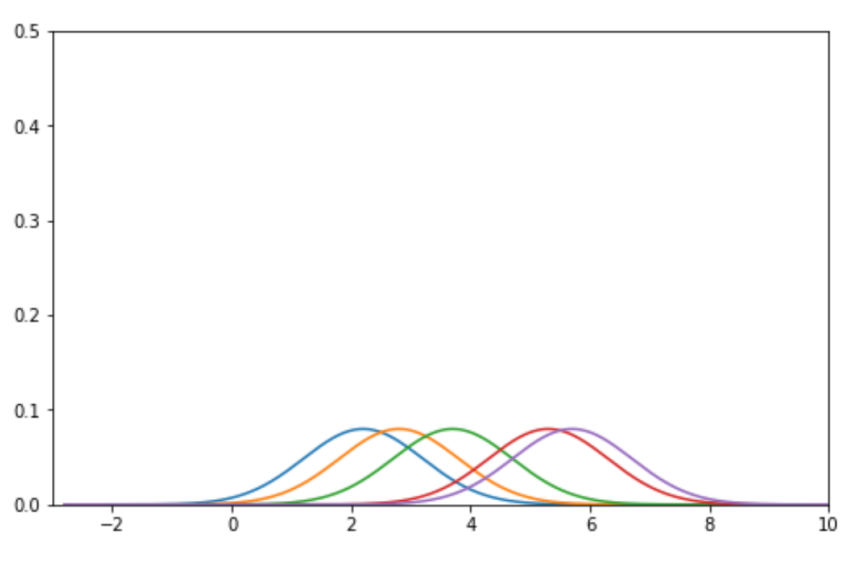
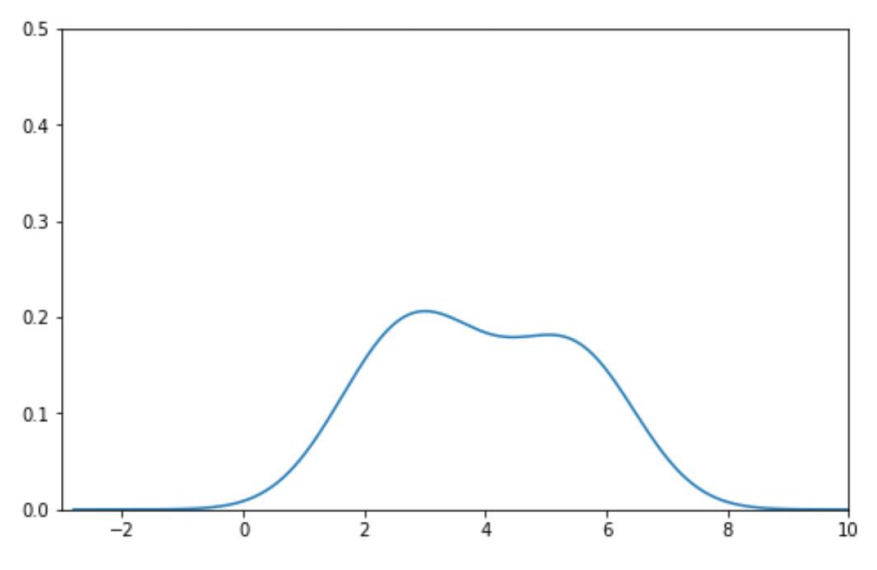
3. 합치자
* Kernel Function?
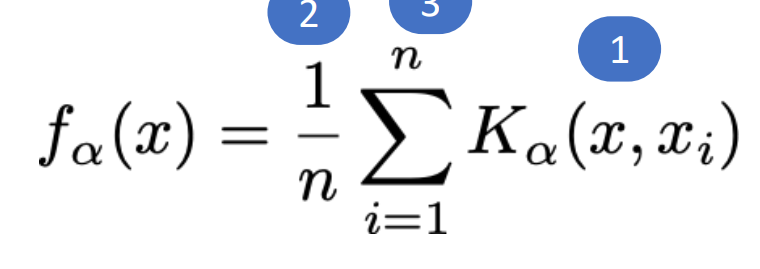
일반적인 KDE formula function의 모습이다.
Ka(x,xi)는 관측치 i를 중심으로 하는 커널이다. x는 수직선 위의 임의의 숫자를 나타낸다. (함수에 대한 입력)
커널 함수는 적분 값이 1이 나오도록 구성된다. (확률 밀도 함수의 성질을 만족함.) bandwidth가 클 수록 더 부드럽고 넓게 퍼진 밀도 추정을 얻게 되고, 작을 수록 더 뾰족한 밀도 추정을 얻게 된다.
가장 일반적인 커널은 Gaussian kernel이다.
n은 주어진 data set의 size이다. (정규화를 위해 1/n을 취함)
각 (x1,x2,...,xn)은 관측된 data point를 나타낸다.
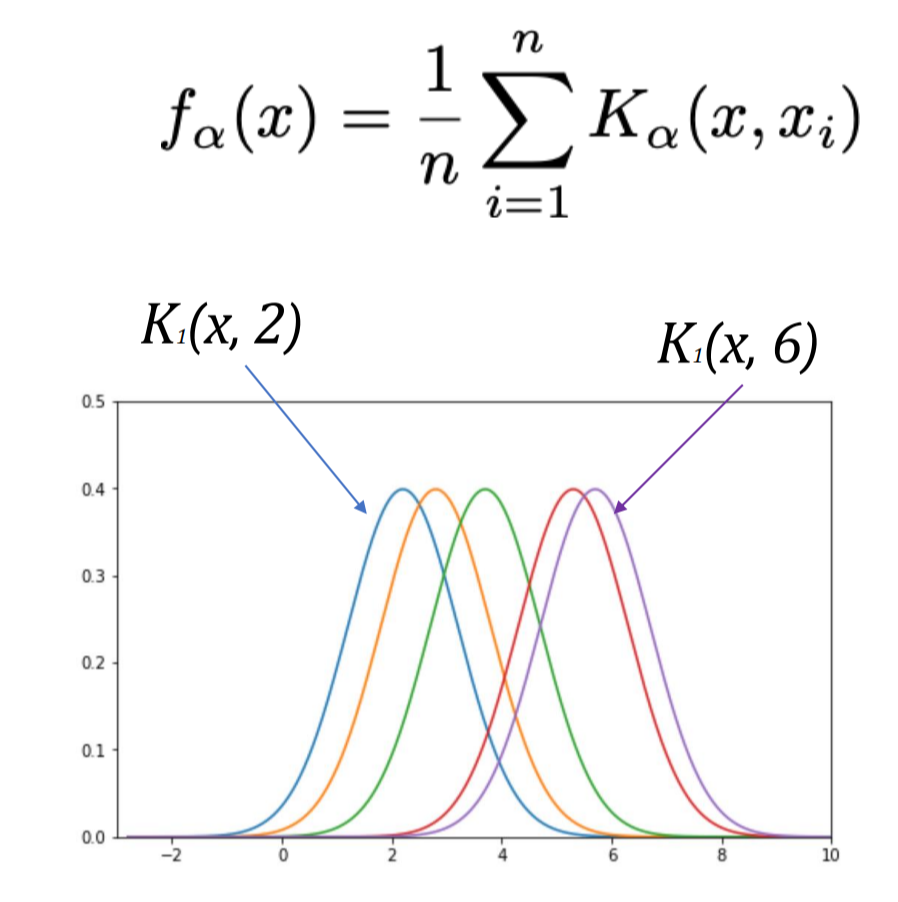
커널 함수의 특성을 요약하면 다음과 같다.
1. 모든 입력 값에 대해 항상 양수의 결과를 가져야한다.
2. 총 합(적분)은 1이 되어야한다.
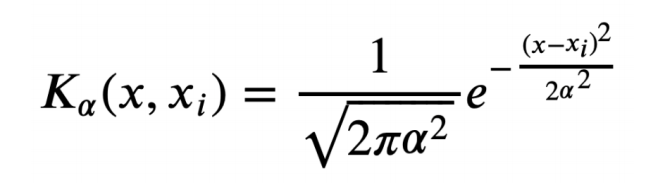
이것이 대표적인 커널 함수인 가우시안 분포 함수이다. 식이 꽤 복잡하다.(확률과 통계에서 자세히 다룬다.)
각 커널은 관측된 값(xi)를 중심으로 그려지는 확률 밀도 함수이며, 따라서 각 커널의 평균은 xi가 된다.
a는 smooting parameter(bandwidth)이면서 동시에 Gaussian의 표준 편차 역할도 해준다.
여기서는 함수를 이해하는 것에 주목하자. smoothing parameter 'a'가 어떻게 곡선의 평활도를 조정하는지를 이해하면 된다. 우리는 가우시안 분포에서 표준 편차를 직접 수정하며 그래프의 모양을 조정하는 것이다.
분포를 크게 주면 당연히 넓게 분포하게 되고, 작게 주면 뾰족하게 분포하게 되는 것이다.
큰 a 값은 KDE 자체를 이해하기 쉽게 만들어주나, 지나치게 많은 정보를 스킵한다.
(histogram의 bin과 유사.)
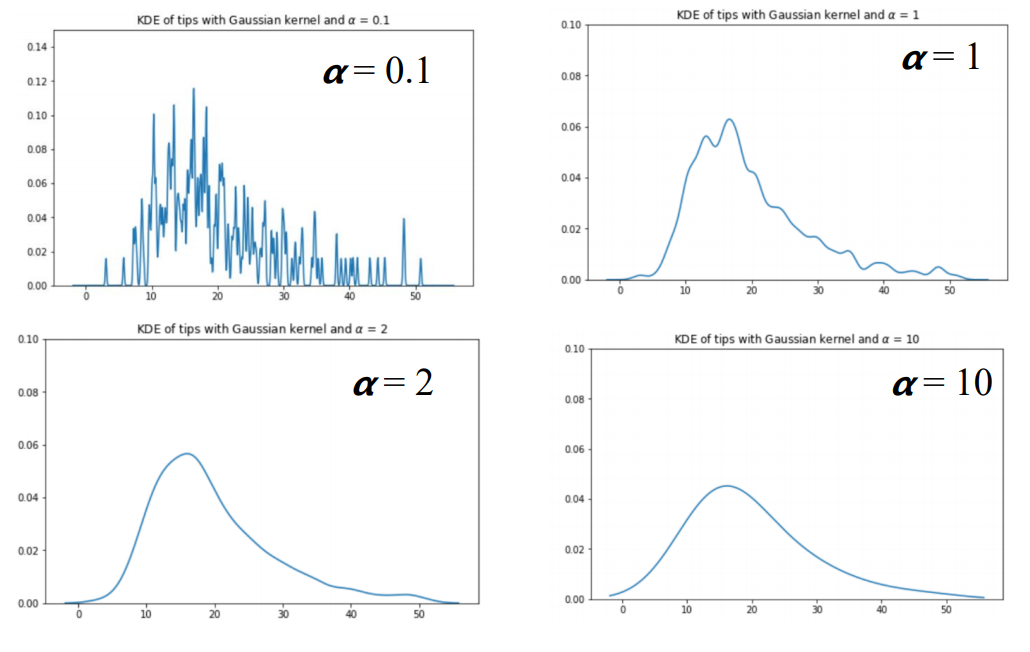
* Relationshops Between Quantitative Variables
Scatter plot은 numerical variable들의 쌍 간 관계를 나타내는데 사용된다.
만약 지금까지 계속 예시로 든 흡연 여부와 출산 아이의 몸무게 데이터를 Box,Violin plot이 아닌 한 그림에 Scatter plot으로표현하면 어떻게 될까?
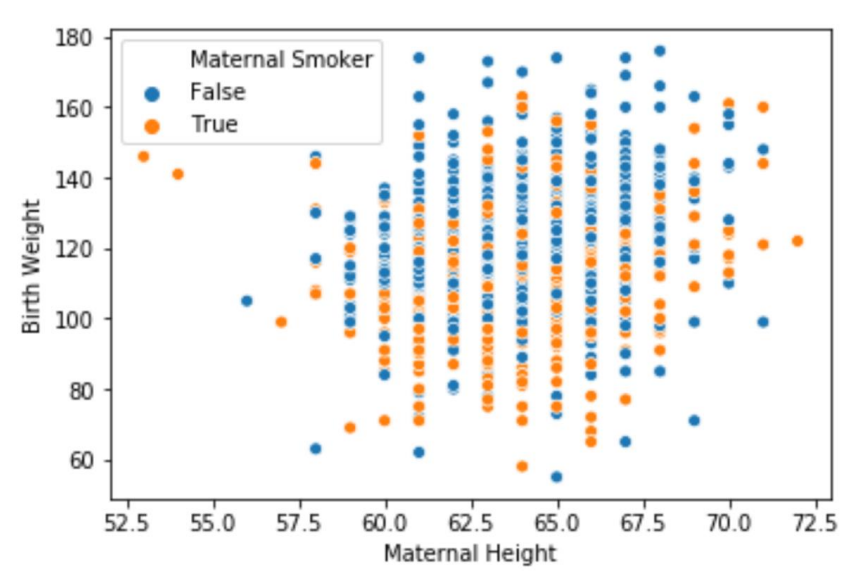
물론, Box, Violin plot의 whisker line 바깥에 존재하는 outlier 정도는 쉽게 인식이 되겠지만, 너무 많은 점이 겹쳐서 해석이 매우 어렵다. 그러면 2 개의 데이터를 Scatter plot으로 표현하는 것은 불가능한 것일까?
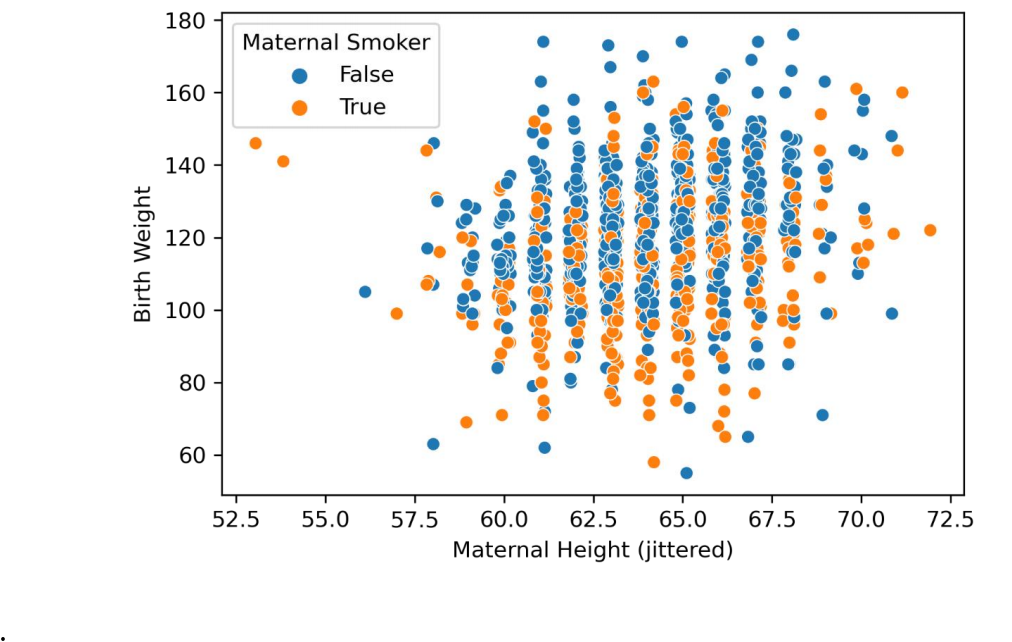
쉽게 생각해볼 수 있는건 jitter를 주고 그리는 것이다. 그러나 딱히 개선되어 보이지는 않는다.
따라서 이를 해결하고자 등장한 여러가지 방법이 있다.
1. Hex plots
Hex plots은 두 variables 의 관계를 시각화하는데 사용되는 2D histogram의 한 형태이다.
XY 평면을 육각형으로 나누어 각 육각형에 데이터 포인트의 빈도 또는 밀도를 색깔의 강도로 나타내는 그래프이다.
육각형은 정사각형에 비해 선형 관계를 더 쉽게 볼 수 있게 해주며, 영역을 더 효율적으로 그리고 시각적 편향을 줄여준다.
- 정사각형은 수직과 수평선에 눈이 가기 더 쉽다.
(Heat map과 비슷)
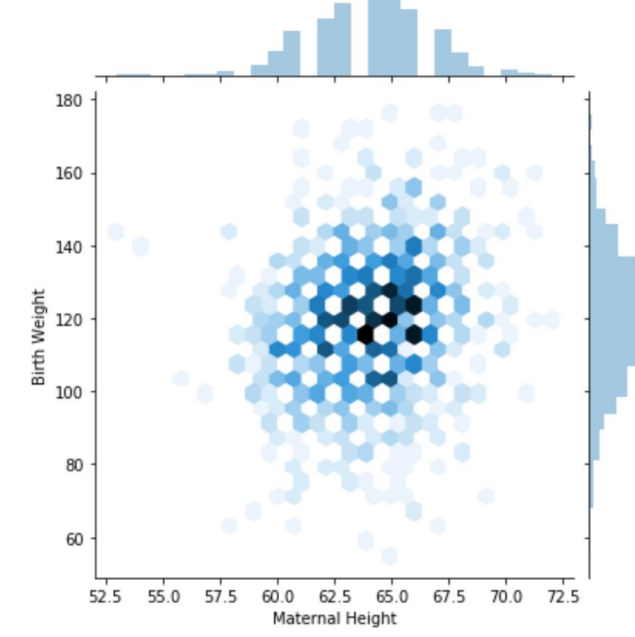
Birth weight과 Maternal Height의 데이터를 육각형 모양으로 시각화한 것이다.
이를 통해 기존 Scatter plot에서 데이터의 밀도를 확인하기 어려운 것을 해결했다.
2. Contour plots
Contour plot은 density curve의 2차원 버전이다.
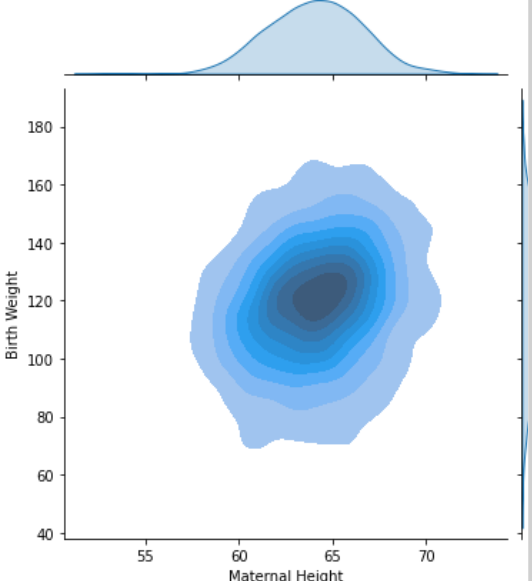
- 결국 종합하면 Scatter plot은 1차원으로 데이터를 표시하기 때문에 데이터의 중복이 심하면 밀도를 파악하기가 어렵다.
따라서 Hexplot, contourmap으로 2차원 표시를 하는 것이다.
'개인 공부' 카테고리의 다른 글
| 데이터 과학 - 7. Visualization Theory (0) | 2024.04.10 |
|---|---|
| 확률 및 통계 - 6. Expected Values and Variance (0) | 2024.04.09 |
| 데이터 과학 - 5. Data Acquisition (0) | 2024.04.09 |
| 데이터 과학 - 4. Data Mining/Science Algorithms (0) | 2024.04.08 |
| 확률 및 통계 - 5. Joint density and Cumulative Distribution Func. (0) | 2024.04.07 |