* Data Acquisition
CRISP-DM에서 데이터 이해 과정을 생각해보자.
1. 초기 데이터 수집.
2. 데이터 묘사. (데이터 셋의 field, records 등에 대한 설명서)
3. 데이터 탐색. (querying, visualization 그리고 요약을 통해 데이터 과학 질문, 데이터가 어떤 영향을 끼치는지 파악)
4. 데이터의 Quality 검증. (데이터의 결측이나 오류 등을 검증한다.)
TDSP에서 데이터 습득 및 이해 과정을 생각해보자.
- 목표 : 대상 변수와의 관계가 파악된 깨끗한 고품질 데이터 세트 생성, 데이터를 정기적으로 고치고 점수를 매기는 데이터 파이프라인의 개발.
- 과정 : 데이터 수집 -> 데이터 탐색 -> 데이터 파이프라인 설정하여 새로운 데이터 점수 매김.
=> 공통점을 생각해보면 Data Acquisition이란 결국 데이터를 수집하고 전처리를 거친 후 관찰, 최종적으로 데이터의 점수를 매겨서 데이터 습득을 하는 것을 알 수 있다.
=> 데이터를 수집할 때는 어떤 데이터가 얼마나 필요하고, 어디서 찾을 수 있으며 어떤 문제가 있을지를 알아야한다.
* Data Types
1. Primary data : 분석을 수행할 조직이나 개인이 직접 수집한 데이터. 내가 논문을 쓰기 위해 ns3를 사용해 데이터를 수집한 것 역시 Primary data가 되는 것이다. 이러한 Primary data는 시간이 많이 소요되고 전문성이 필요하지만, 데이터를 더 잘 이해할 수 있다는 장점이 있다.
(본인이 직접 했기 때문에)
2. Secondary data : 다른 사람이 공유해준 데이터. 쉽게 얻을 수 있으나, 데이터가 어떻게 생성되었는지를 이해해야한다.
* Cleaned data vs Raw data
1. Pre-cleaned data : Kaggle과 같은 기관에서 이미 전처리를 한 데이터 셋.
- 사용 방법이 편리하나 raw data로 작업할 때 제공되는 유연성과 제어 기능을 일부 상실한다.
* Data File Formats
Tabular, non-Tabular, Lmage, Agnostic(.dat), Proprietary(MS Excel)
- Primary Data는 실험, 관찰, Scraping 등으로 구할 수 있다.
- Secondary Data는 간단히 사이트에서 다운받거나, API를 통해 받을 수 있다. (보통 Restful API)
- 데이터를 가져올 때 여러 PC를 통해 서버에 Request를 하면 빠르게 가져올 수 있다.
=> wget, curl, Aria2 등 다양한 CLI 툴이 있다.
=> 또 다른 방법으로는 Crawling이 있다. Mechanize 같은 경우에는 사이트를 HTML로 가져올 수 있다.
그렇게 가져온 데이터 중 정규표현식을 통해 매칭된 문자열만 수집하는 것이다.
* Crawling

(단, Web Crawling은 보통 수집된 데이터를 상업적 용도로 사용하면 안되고, 지나치게 쿼리를 많이 발생시키거나 사용 조건에 Crawling 금지가 있는데도 시도를 하면 안된다.)
* Regular Expression
- 쉽게 얘기하면 문자열을 수학 공식처럼 표현하는 것이다.
예를 들면 ' 최고 기온 : 28 도, 최저 기온 : 0 도' 라는 문장에서 최고 기온만 추출하고 싶다고 생각해보자.
그러면 가장 쉽게 떠올릴 수 있는 건, 최고 기온 : 이라는 문장의 이후 정수 부분을 추출하면 될 것이다.
이 부분을 표현하여 컴퓨터에게 전달하는 것이다. ( 최고 기온 : ([0-9]+) )

이 정규표현식을 보면, h로 시작하는 문장이면서 h 이후에 1개 이상의 aeiou가 발생할 시를 match하는 문장이다.
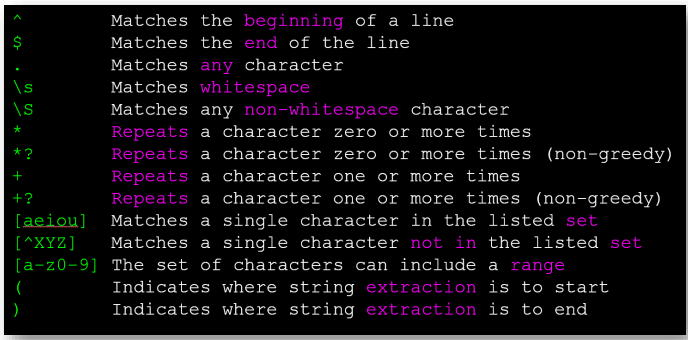
python에서 정규표현식을 사용하고 싶으면 import re를 한 후 search, findall 등을 사용하여 정규표현식 기반 검색을 할 수 있다. (re.search('^From: ', line))
- Wild-Card Characters
=> ^X.*:를 생각해보자. ^X는 X로 시작하는 라인부터 매칭을 시작한다는 것이다. 이후 .*는 아무런 문자나 계속해서 받겠다는 것이고 마지막 :는 해당 문자를 마지막으로 스캔을 끝내겠다는 것이다.

이제 해당 ^X.*: 에서 이것저것 바꿔보자.

초록색으로 색칠이 된 부분만 매칭하려면 어떻게 해야할까? ^X.*:이면 모두가 매칭될 것이다.
데이터 자료형을 보면, ^X-\S+: 이라고 작성해볼 수 있다. 이 경우, X-까지 매칭하고 공백이 아닌 문자열을 매칭해나갈 것이다. 이 경우 1,2 라인은 읽히나 3라인은 Plane까지 매칭후 공백이 발견되어 취소될 것이고, X-:는 X- 이후 문자가 없어 취소될 것이다.
따라서 y = re.findall('(^X-\S+:)', line) 과 같이 지정해줄 수 있다.
기본적으로 반복 문자(* 또는 +)는 가능한 한 가장 큰 문자열과 일치하도록 작동한다. (greedy)

예를 들면, ^F.+:을 정규표현식에 넣으면 From: 까지만 인식이 되고 끝낸다고 생각할 수 있지만, 계속 읽으며 또 다시 패턴이 만족되는 부분이 있기에, 해당 부분까지 매칭해버린다.
이 때, From: 까지만 인식시키고 싶으면 패턴이 만족되면 스캔을 끝내는 non-greedy matching을 사용하여야한다.
'^F.+?:' 과 같이 해주면 된다.
()을 통해 캡처할 부분을 정해줄 수도 있다.

예를 들면, 다음의 문장에서 메일만 뽑아내고 싶다고 해보자. \S+@\S+ 를 통해 메일을 인식할 수 있지만,
만약 To beige@gmail.com 이 있다고 하면 이 역시 매칭될 것이다. 따라서 From 뒤의 메일을 뽑되, 메일만 뽑도록 할 수는 없을까?
^From (\S+@\S+) 라고 하면 된다.
* String Parsing
직접 수동으로 데이터 슬라이싱 하는 방법은 다음과 같다.
1. 원하는 문자가 시작되는, 끝나는 인덱스를 찾기
2. 해당 인덱스 구간을 스캔하기.
ex)
data = From beige@gmail.com Sat
=> atpos = data.find('@')
stpos = data.find(' ',atpos)
searched = data[atpos+1:stpos]
print(searched)
문자를 단위로 쪼개는 방법도 있다.
ex) data = From beige@gmail.com Sat
words = data.split()
email = words[1]
pieces = email.split('@')
pieces는 ['beige', 'gmail.com']으로 구성된다.
여기서 도메인 부분을 정규표현식으로 표시하면 '^@(\S*)'으로 표현이 가능하겠다.
즉 y=re.findall('^@(\S+)', data)로 찾아낼 수 있을 것이다.
혹은 From부터 긁어오고싶다면, ^From .*@(\S*)와 같이 할 수 있다.
'개인 공부' 카테고리의 다른 글
| 확률 및 통계 - 6. Expected Values and Variance (0) | 2024.04.09 |
|---|---|
| 데이터 과학 - 6. Data Understanding & Visualization (0) | 2024.04.09 |
| 데이터 과학 - 4. Data Mining/Science Algorithms (0) | 2024.04.08 |
| 확률 및 통계 - 5. Joint density and Cumulative Distribution Func. (0) | 2024.04.07 |
| 데이터 과학 - 3.Data Science Methodology Part 2. (0) | 2024.04.03 |