* Visualization Theory
Visualization의 목적을 다시 짚어보자.
1. data에 대한 이해를 도움.
2. 결과를 다른 사람에게 설명하는데 도움이 됨.
- Linearization

이러한 Scatter plot의 경우는 데이터 분포가 편향되어 있어 해석하기 어렵고, x,y 변수간의 명확한 관계를 설명하기 어렵다.
변환을 조금 하여서 다음의 사진 같이 만들어보면 어떨까?

x,y가 linear한 분포를 띄도록 데이터를 재스케일링 해보는 것이다.그렇다면 기울기와 절편 등을 사용하여 관계 해석이 보다 쉬워질 것이다. 그럼 일단 변환을 해보자.

이 그림을 non-linear의 형태를 띄게 만드는 원인은 무엇일까?
1. 몇개의 아주 큰 X 값을 가지는 Outlier 들이 가로 축 scale을 왜곡한다.
2. 큰 y 값을 가진 많은 값들이 세로 축을 압촉한다.
1. 몇개의 아주 큰 X 값을 가지는 Outlier 들이 가로 축 scale을 왜곡한다.

- 기존 x data에 log를 취하자.
log 함수의 특성 상, 작은 x 값의 데이터에 적용할 경우 적게 줄어들고, 큰 값의 x 데이터에 적용할 경우 크게 줄어들 것이다.
2. 큰 y 값을 가진 많은 값들이 세로 축을 압축한다.

y를 pow 연산하자. pow(2,2)는 4지만 pow(4,2)는 16, pow(8,2)는 64이다. 이렇듯 작은 값에 대해서는 적게 확장되고 큰 값에 대해서는 크게 확장되는 성질이 있다.
이렇듯, x가 왜곡될 경우 log, y가 왜곡될 경우 power 연산을 통해 선형 관계로 scatter graph를 변환할 수 있다.
그러면 어떻게 왜곡 될 떄 어떻게 변환해줘야할까? 그 기준을 마련해둔 Diagram이 있다.

결국 log, sqrt 연산은 작아지게 만들고, power 연산은 커지게 만드는 것이다. 그래프가 어디 쪽으로 편향됬는지에 따라 X,Y에 어떠한 변환을 취해줄 지 정해놓은 Diagram이다.
* Visualization의 중요성

위 사진의 모든 Scatter plot은 전부 X,Y의 Min, Standard Distribution, 상관계수가 같다.
수치로만 데이터를 확인하는 것이 얼마나 위험한 판단인지 잘 보여주는 사진이다.
* Information Channels
지금껏 알아본 수많은 방법대로, Data는 visualization이 될 수 있다.
기본적인 plot type들을 알아보자.
1. Rug Plot : Encoding 1 Variable

각 데이터마다 수평 막대로 할당하고, Encoding 과정을 통해 위치를 결정, 표시하는 과정을 거쳐 생성되는 1개의 변수를 디자인하는 Plot이다.
2. Scatter Plot : Encoding 2 Variables

Rug Plot과 비슷하나 2개의 변수를 표현하므로 좌표축이 2개가 된 점이 다르다.
그렇다면 다음의 사진에서는 몇개의 변수(channel)을 담고 있을까?

답은 4개이다. (Color, Circle area, x, y)
다른 사례를 보자.

굳이 잘 살펴보지 않아도 길이가 비슷하여 구분이 어려운 것들이 보일 것이다. 위 사진보다도 눈에 들어오지 않는다. 이렇 듯 한 channel을 과도하게 사용하면 문제가 발생하기 마련이다. 따라서 Color, x/y, Markings, Context 등 다양한 visualization 요소를 적정 비율로 섞어주는게 중요하다.
* Harnessing X/Y
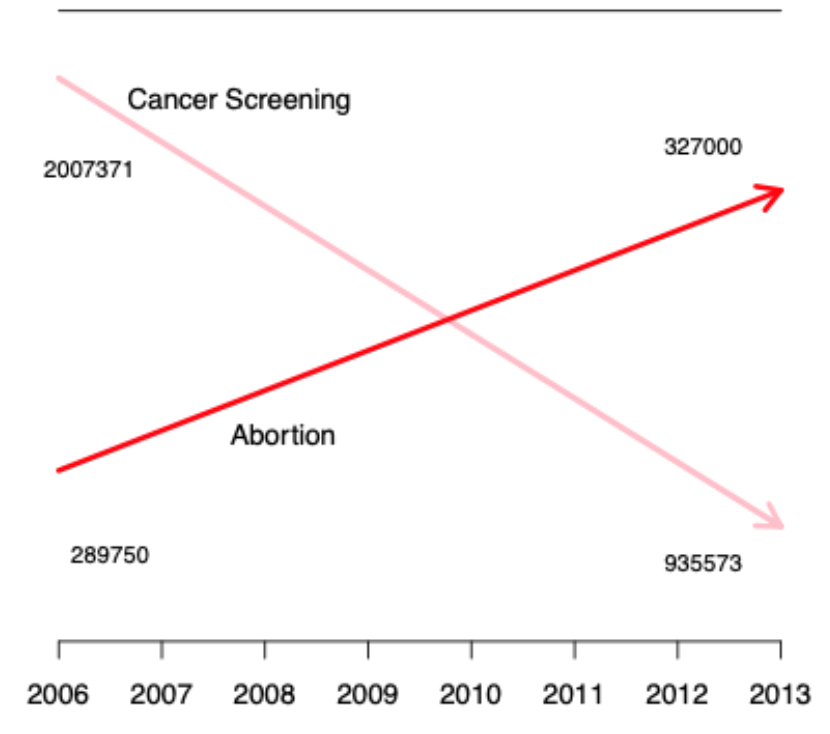
위 그림에서 이상한 점을 찾아보자.
Cancer Screening은 2007371-935573 = 1072000, Abortion은 327000-289740 = 90000 . 즉 10배가 넘은 등락폭이 있는데 그림상의 증감량은 거의 비슷하게 나온다.
또한 327000이 935573보다 현저히 낮은 수치인데 더 위에 있게 그려진 것이 맞는 것인지도 의심해봐야한다.

이렇게 구성된 그래프는 어떨까? 모든 데이터를 동일한 sclae로 나타내는 것이다. 이러면 Cancer Screening의 기본적인 분포 scale이 너무 커서 Abortion의 증감량이 거의 보이지 않는다. 즉 Abortion의 증가량이 무시가 되는 것이다.
이럴 때는 percentage로 y축을 수정하여 다음과 같이 표현하는 것이 객관적이다.

또는 공통된 scale을 가지는 또 다른 value를 y축으로 쓸 수도 있다. 예를들면 1년에 이루어진 총 procedure들 중 차지하는 비율과 같은 것이다.

이렇듯 visualization을 할 때는 다음을 고려해야한다.
1. axis limits을 정한다.
2. 모든 데이터를 다 표시할 필요는 없다. 중요한 부분을 확대 변환해서 표시하거나, 여러개의 그림을 사용할 수 있다.
* Harnessing Color
색상은 개인적이나 문화적인 요소가 많이 들어가는 표현 방식이다.
이를테면 빨간색은 따듯함, 높음, 위험함 등의 의미를 내포할 수 있는 여지가 있는 것이다.
또한 색맹 등의 경우에는 색상을 구분하지 못하는 치명적인 오류가 발생할 수 있다.
이외에도 각 수치에 시각적 변화가 고르게 분포되어야한다는 점도 있다.
(0.1~0.5는 약하게 변화하다가 0.5~1.0은 강하게 변화되면 왜곡될 여지가 있다. 물론 상황에 따라 일부러 이렇게 하는 경우도 있을 수는 있겠다.)

대표적인 colormap으로는 viridis가 있다. viridis는 색맹인 사람들에게도 이해가 잘되며 색상의 변화에 일정한 간격을 가지고 있어 기본 colormap으로 많이 사용된다.
만약, 정성적 지표를 사용한다면 범주끼리 상하 관계가 없을 것이다. 그 경우 색상은 어떤 의미를 담지 않은 중의적인 색상표를 선택하여 구분을 도와주면 된다.
만약, 정량적 지표를 사용하면 변화의 크기를 시각화 하는 색상표를 선택하는 것이 중요하다.
ex)
데이터가 낮은 값에서 높은 값으로 상승하는 경우 더 극단적인 묘사를 위해 밝아지는 색상표를 활용한다.
데이터가 낮은 값, 높은 값이 동일하게 강조되어야하는 경우 밝은 색상이 중간 값을 나타나게 하고 좌 우로 다른 색을 분포시킨다.
* Harnessing Markings

다음은 marking의 방법과, 특성을 나열해놓은 사진이다.
Length의 경우에는 대소를 비교하기가 쉽다.

Area의 경우에는 한눈에 구분하기가 쉽지 않다.

빨간 색 영역은 초록색의 2배이지만, area만 봐서는 명확하지 않다.
또한 Baseline을 쌓는 것은 basline의 움직임을 유발하기 때문에 비교가 어렵게 만드는 요인이다.

baseline에 따라 위의 막대기도 영향을 받기 때문에 비교가 어려워지는 요인이다.
예를 들면 왼쪽의 bar plot에서 파란색 부분은 거의 수량이 비슷해보이나 서로 비교가 어렵다.(밑의 분포들이 움직여서 파란색 막대기의 부분의 위치가 바뀐다.)

이 경우도 각 나라의 배출량을 비교하기가 어렵다. -> line plot으로 변환을 한다면 더 구분하기가 쉬워진다.
*Harnessing Conditioning

이 그림을 보면 남자와 여자의 학력별 주급 차이를 묘사하고자 한 것 같다.
교육 수준이 높을 수록 수입이 올라가는 것은 알 수 있지만 남성과 여성의 수입 차이를 직접 비교하는 것은 서로 간격도 있고 색상이 비슷해서 직관적이지가 않다.

이를 이렇게 line plot으로 표현하면 훨씬 성별간 차이가 잘 드러남을 알 수 있다.
여기서 더 나가면 Men/Women 과 같은 ratio를 그래프로 나타내는 방법도 있을 수 있겠다.(이러면 학력 수준에 따른 급여 차이는 생략이 된다.)
- Superposition vs Juxtaposition
=> Super position : 여러 밀도 곡선이나 Scatter plot을 겹쳐서 표시하는 것이다. 이는 동일한 차트 위에 여러 데이터 셋을 나타내어 직접 비교할 수 있게 해준다.
=> Juxtaposition은 여러 그래프를 나란히 배치하는 것을 의미한다. 각각의 그래프가 동일한 scale을 유지하며 그려진다.
* Harnessing Context

기존 그래프에서 제목을 만들고, text를 각 line 위로 올리고, 격자를 그린 뒤 단위까지 적어줘서 확실히 가독성이 늘어난 것을 볼 수 있다.
또한, 그래프만으로 표현하기 어려운 경우, Caption을 달아서 보조 설명을 할 수도 있다.
'개인 공부' 카테고리의 다른 글
| 데이터 과학 - 8. Data Preprocessing(1) (0) | 2024.04.14 |
|---|---|
| HCI - Learnability (0) | 2024.04.10 |
| 확률 및 통계 - 6. Expected Values and Variance (0) | 2024.04.09 |
| 데이터 과학 - 6. Data Understanding & Visualization (0) | 2024.04.09 |
| 데이터 과학 - 5. Data Acquisition (0) | 2024.04.09 |