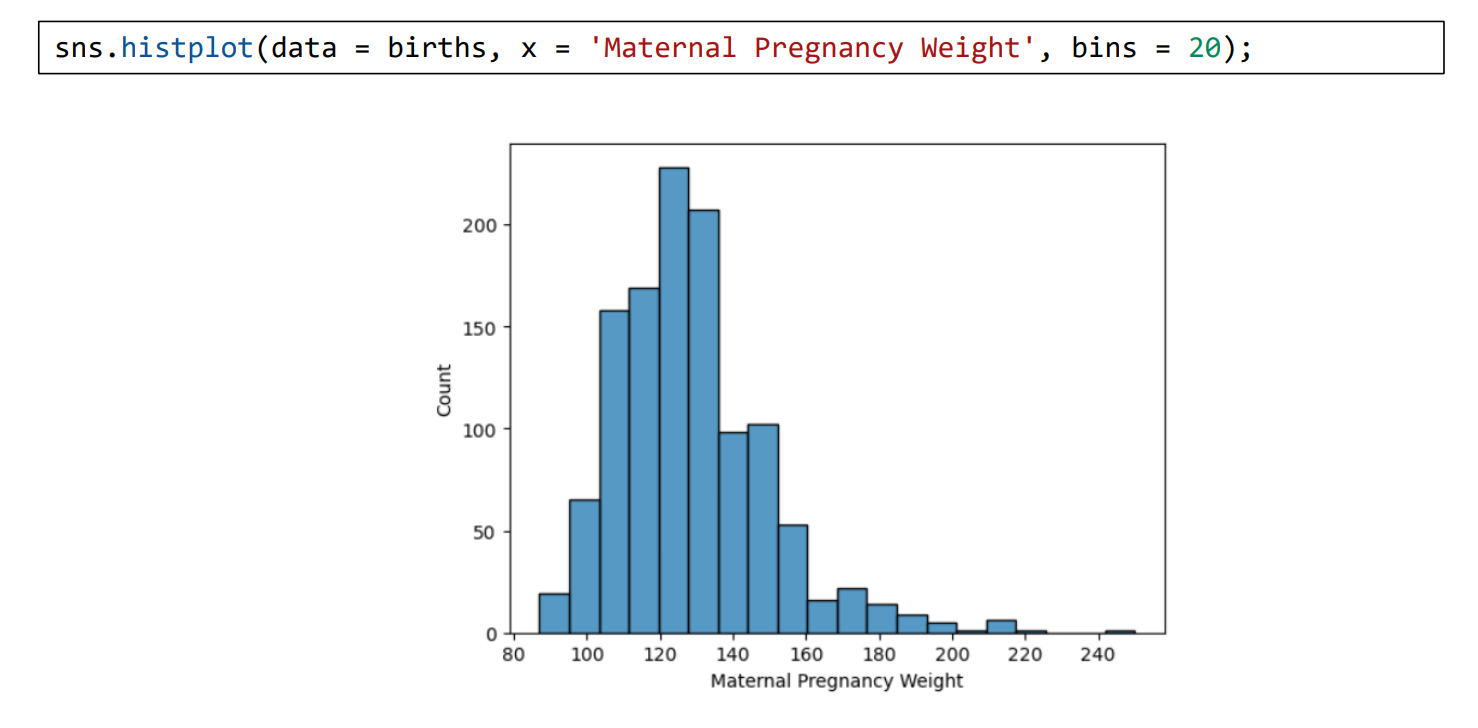
* Descriptive Statistics => 주어진 데이터를 잘 요약하는 방법. data를 의미있게 요약한다.(주어진 데이터의 정규분포 여부 등) (여기서 Data는 Numerical, Categorical를 생각한다.) - Distribution => 특정 Range로 나누어 data들의 frequency로 나타낸 것.(Data visualization과 Data reduction에서 다루었다.) => Distribution을 묘사하는 방법은 Visualization으로 하는 방법과 Numerical 적인 수치로 묘사하는 방법이 있다. 물론 이 방법 중 하나를 골라쓰는 것이 아니라 둘다 사용해야 객관적인 묘사가 가능하다. (Histogram을 그리면서 mean, S.D. 와 같은 수치도 묘사한다...