* Distributed learning
- 왜 분산 학습을 하여야할까?
ex) On-device learning

만약 모델이 개인 데이터를 학습하여 맞춤형 서비스를 제공해야한다고 생각해보자. 이 경우 Privacy 문제 때문에 Server로 데이터를 보내는 것은 문제가 될 수 있다.
1. 데이터의 분산성 : 데이터는 센서, 기기, DB 등 다양한 곳에 분산되어 존재하지만, 보안 등의 이유 때문에 고립되어있을 수 있다.
2. AI 시스템의 적응 필요성 : AI 시스템은 센서에서 수집된 새로운 데이터에 지속적으로 적응해야할 필요가 있다. 즉, 개인적인 데이터를 다룰 일이 필수적으로 생긴다.
=> 분산된 여러 client에서 데이터를 활용해 모델을 자체적으로 학습할 수 없을까?
1. Federated Learning

이전에 parameter server와 worker node들의 관계와 똑같이 Data는 edge layer에 남겨두고, 학습을 한 결과만 server로 보내보자.
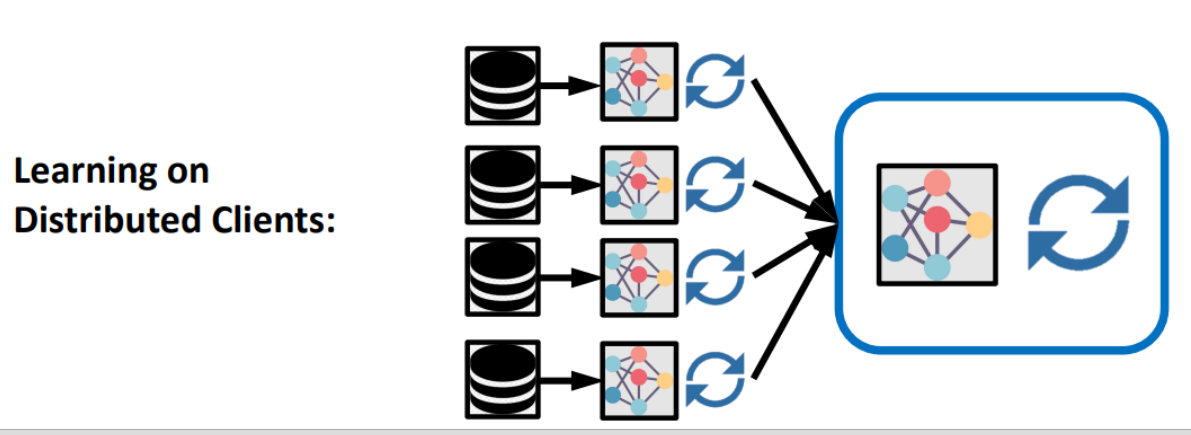

=> 이 컨셉으로 접근한 사례에는 Google G-board, NVIDIA Clara for medical image 등이 있다.
- Training data 사용 목적 : 모델의 학습 가능한 parameter를 최적하기 위해 사용된다.
=> 여기서 주목할 점은 모델을 학습하게 하는 요인은 데이터 그 자체가 아니라 데이터에서 얻어진 gradient라는 것이다. 따라서 edge 단의 local model에서 자신의 data로 학습을 하고 data의 gradient나 업데이트된 parameter만 서버로 전송해도 효과가 동일하게 나타날 것이다.
- Federated leraning strategy
1. Training data는 local edge에 유지 : 외부 서버로 전송 x
2. 초기 local edge가 학습할 모델은 서버에서 복사하여 edge device로 전송. (local model replica)
3. Gradients 또는 업데이트된 parameter 회수
=> Parameter server의 집계된 결과를 정리하는 방법이 중요해진다.
* Federated averaging : FedAvg algorithm
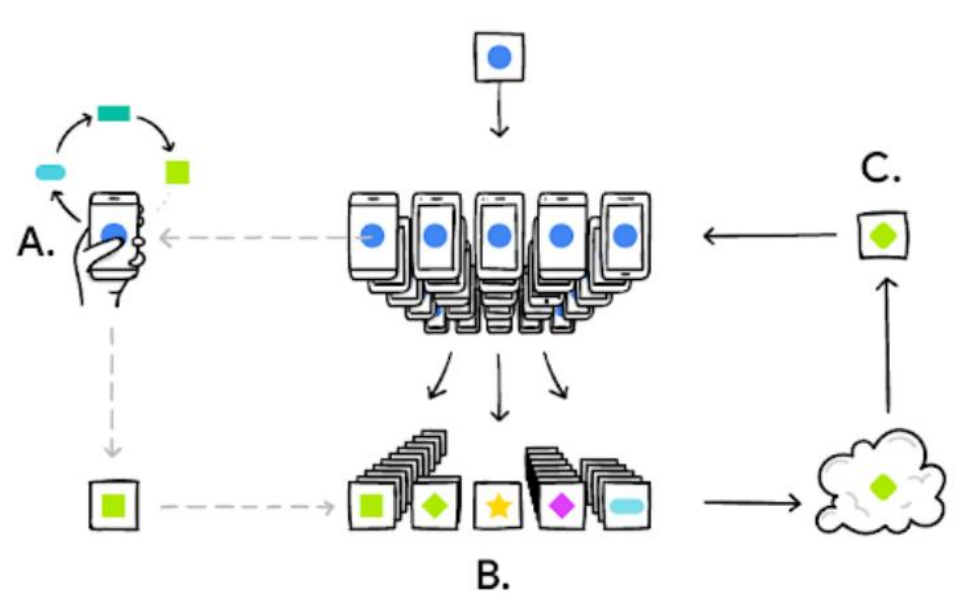
Base : Server가 model을 client로 전송. (초기 모델 배포)
1. Client에서 로컬 학습 수행(자체 데이터 활용)
2. 기준치만큼 학습 후 각 디바이스는 학습 결과를 Server로 전송.
3. 서버에서 여러 클라이언트로부터 받은 Gradient들의 평균을 계산하여 Global model 생성 후 배포(local model update)
4. 1~3을 반복
* 가정 :
1. Active clients : 꼭 모든 client가 매 학습에 전부 참여하지 않아도 괜찮다.
2. Local computation : local client에서 모델 학습을 다시 mini batch, epoch으로 나누어 학습해도 된다.
* Federated Learning의 단점
1. Massively Distributed : Data가 많은 디바이스에 분산되면 분산될 수록 통신 비용 증가, 계산 비용 증가 등의 문제가 생긴다.
2. Limited Communiucation : 디바이스와 중앙 서버간 통신 횟수가 제한적이고, 안정적이지 못할 수 있다.
3. Unbalanced data : 디바이스 간에 보유하는 데이터 양이 달라 load balancing 문제가 발생 가능하다.
4. Highly Non-IID Data : 디바이스들은 각자 그 사용자의 패턴을 반영하며, IID가 아니라 값의 편향이 가능하다.
5. Unreliable Compute Nodes : 각 노드들을 100% 신뢰할 수 없다. 잘못된 값을 전송할 수도 있는 등의 문제가 있다.
6. Dynamic Data Availability : 데이터 가용성이 시간에 따라 달라질 수 있다.(즉, 학습 데이터가 항상 접근할 수 있다는 보장이 없다.)
2. Asynchronous Federated Learning
* Motivation : 서버는 모든 client에게 gradient를 받을 수 있다는 가정을 없애보자. 즉.
1. Server와 device 간의 연결이 Unreliable 하다.
2. device는 예측할 수 없게 offline 상태로 전환된다.
3. Straggling 문제가 언제든지 일어날 수 있다.
=> Tight한 동기화 설정은 불필요한 학습 지연만 유발할 수 있다.
* FedAsync : Staleness - 항상 모든 client가 동일한 타이밍에 학습해서 결과를 주지 않을 수 있다는 가정
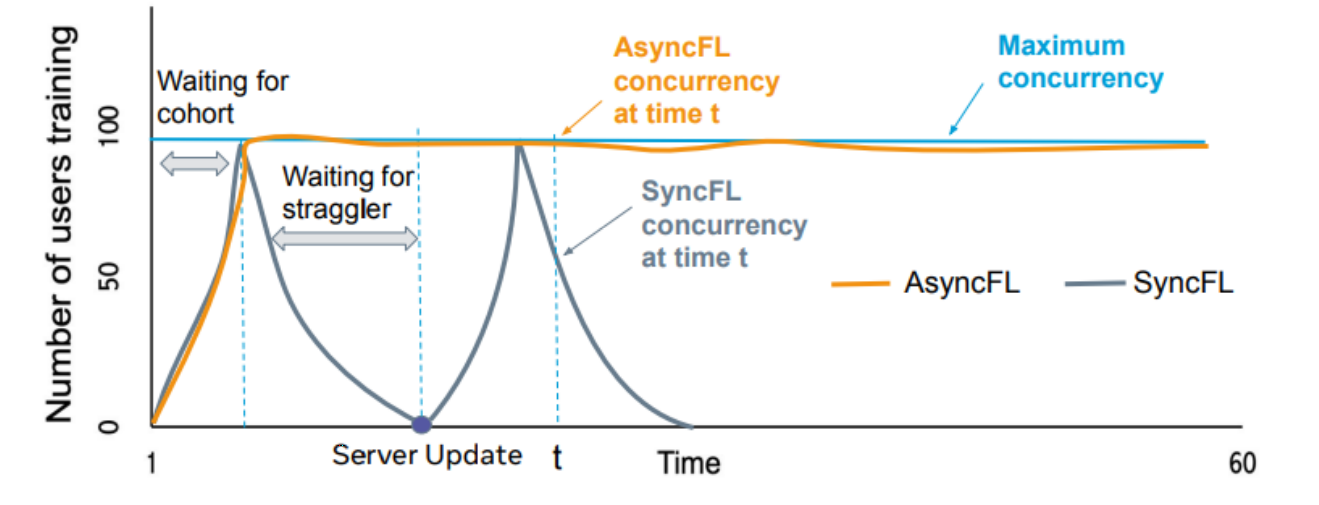
=> 각 local model 마다 staleness가 다를 수 있다. 따라서 SyncFL 방법으로 접근하면 한 노드의 Straggler 효과 때문에 대기해야할 타이밍이 언제든지 발생할 수 있다. 이 때 AsyncFL을 사용시 이를 기다리지 않고 온 결과부터 처리해줄 수 있게 될 것이다.
3. Robust Federated Learning

* Motivation : 악의적인 Client가 Byzantine attack을 수행하여 허위 파라미터를 전송할 수 있다. 꼭 이런 공격사례가 아니더라도 client의 오작동으로 outlier에 해당하는 값이 전달될 수 있다. 이 때, FedAvg 방법을 사용하면 해당 값이 평균 값을 크게 오염시키게 된다.
* Byzantine Gradient Descent : 악의적인 공격이 존재 가능한 상황에서도 안정적으로 학습하기
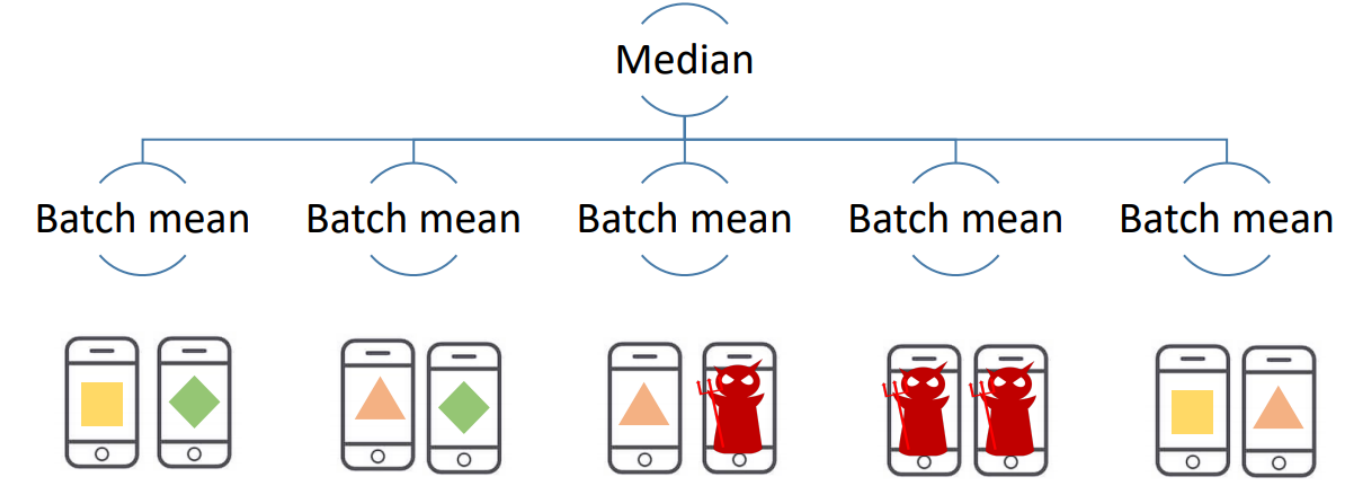
랜덤하게 edge device들을 그룹화 하고, 이들의 Batch 평균을 먼저 계산해서 이 값을 서버로 전달한다. 이러면 이상치를 어느정도 완화할 수 있다. 또한 그 값들의 Avg가 아닌 Median 값을 사용해 outlier effect를 줄일 수 있다.
(edge device group은 매번 랜덤하게 선정한다.)
4. Split Learning
* Motivation : FL은 모델이 커지면 커질 수록 해당 모델의 local replica를 유지해야하는 client 단의 부담이 심해진다.

또한 연합 학습의 참여 노드가 많으면 많을 수록 communication cost가 올라가게 된다.


Transformer 이후 거대모델의 시대가 도래한 현 시점, 이러한 문제는 심각하다고 볼 수 있다.
* Split Learning : 모델을 client part, server part로 나누어(cut layer) 서버에게 모델 연산의 부담을 어느정도 넘겨주기

=> 주로 Head, tail로 나눈다고 하며 이들은 각자 client, server에서 별도로 유지된다. 이때 Cut layer 기준 오가는 값은 계산 중간 값(Smashed Data)이므로 프라이버시는 여전히 지켜진다.

1. Forward propagation : Head -> Smashed Data -> Tail -> Result
2. Back propagation : Gradients -> Tail -> cuit layer -> head -> update
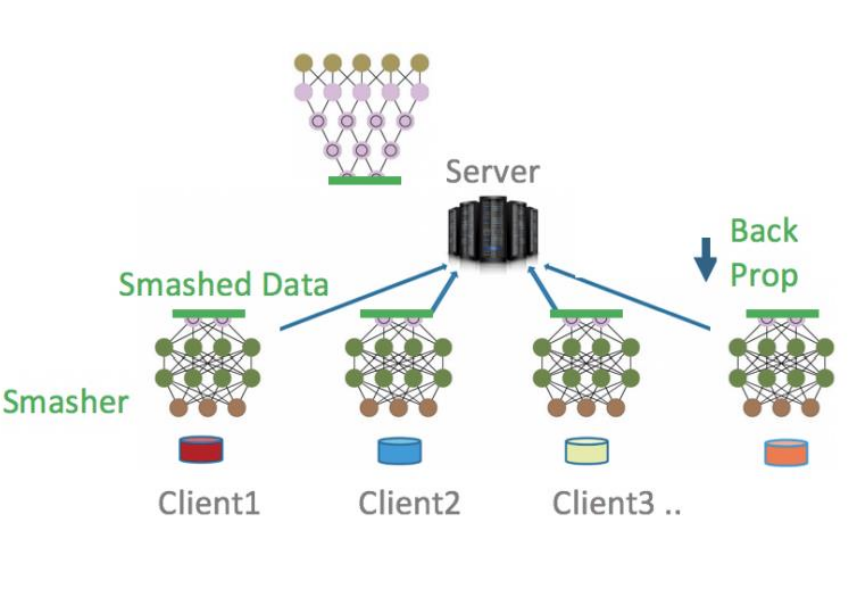
=> 또한 여러 client가 있을 경우에도 Smashed Data를 집계해서 학습에 활용할 수 있다.(FL과 유사)

a와 같이 값을 서버에서 받아서 일괄적으로 업데이트를 명령하는 중앙화 구조도 가능하지만, b처럼 모델 파라미터 업데이트를 peer끼리 하는 방식도 적용 가능하다. (서버의 역추적 방지)
* Split Learning의 장점 (FL과 비교) :
1. model privacy 상승. (모델 구조 분할)
2. Client의 계산 부담 하락
3. 보통 communication overhead가 줄어든다. (모델 파라미터를 주고받는 것이 아닌 Smashed Data를 주고 받는다.)
4. Model 수렴 속도가 더 빠르다.
* Split Learning의 단점 :
1. Server와 client간 communication이 잦다.
2. Direct label leakage
3. Split Learning은 Client-Server 순차적으로 학습이 진행된다. 따라서 병렬 처리가 어렵고 Sync의 특성이 강제된다.
'개인 공부' 카테고리의 다른 글
| Distributed System - 9. Distributed Training (0) | 2024.12.05 |
|---|---|
| Distributed System - 8. Fault Tolerance (0) | 2024.12.04 |
| Distributed System - 7. Consistency & Replication (0) | 2024.12.02 |
| Distributed System - 6. Coordination (0) | 2024.12.02 |
| Distributed System - 5. Naming (0) | 2024.10.23 |