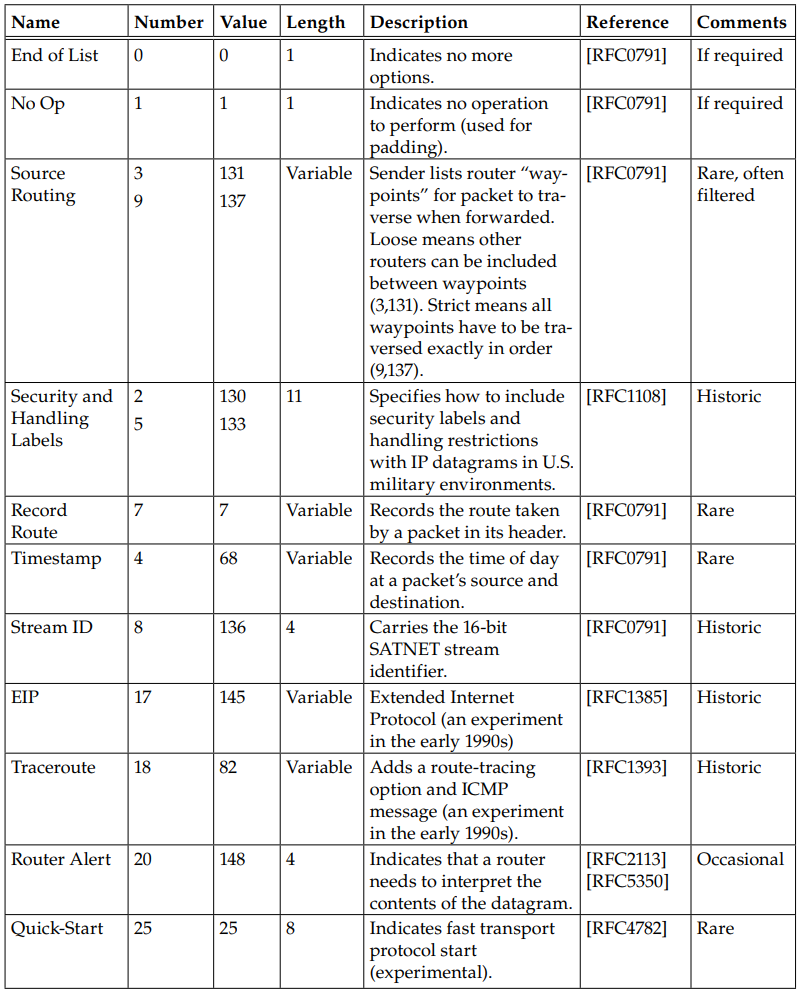
4. System Configuration: DHCP & Autoconfiguration - 1
1. IntroductionTCP/IP Protocol suite을 사용하려면 각 호스트와 라우터에 일정량의 구성 정보가 필요하다. 구성 정보는 시스템에 로컬 이름을 지정하거나, 인터페이스에 IP 주소와 같은 식별자를 할당하는데 사용한다. 또한 DNS(Domain Name System)이나 모바일 IP Home Agent와 같은 다양한 네트워크 서비스를 제공하거나 사용하는데도 활용된다. 그럼 이러한 구성 정보는 어떻게 만들까? 여기에는 3가지 접근방법이 있다. 각각 정보를 수동으로 입력하는 법, 네트워크 서비스를 이용해 시스템이 정보를 획득하도록 하는 방법, 알고리즘을 사용해 자동으로 정보를 결정하는 법이 있다. 이전에 살펴본 바와 같이, TCP/IP 네트워킹에 사용되는 모든 인터페이스는 IP 주소, 서..